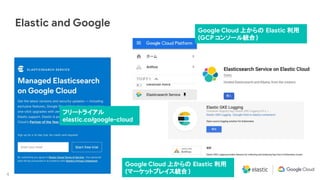
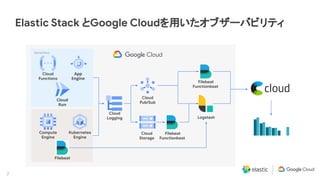
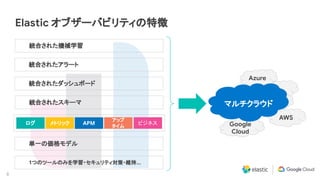
Download as PDF, PPTX






![15
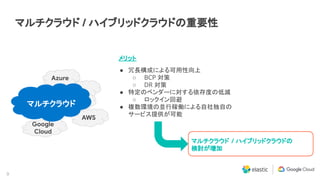
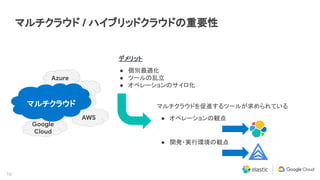
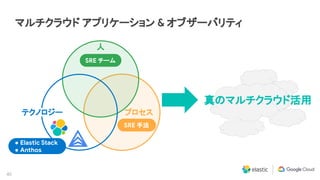
マルチクラウド / ハイブリッドクラウドの活用
テクノロジー
人
プロセス
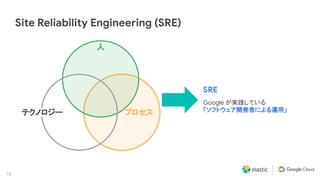
What [ テクノロジー ] だけではなく、
● Who [人]
● How [プロセス]
を考慮していく事が重要](https://image.slidesharecdn.com/2020-09-09googlecloudelasticontourobservability-200917204648/85/Elastic-and-Google-Anthos-SRE-15-320.jpg)





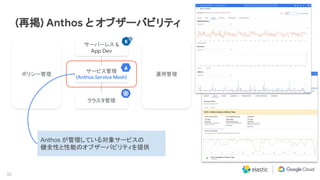
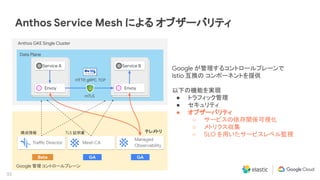



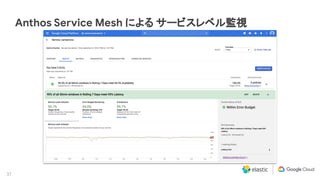




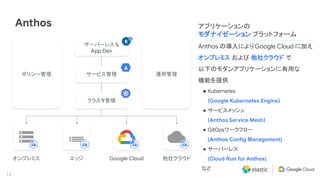
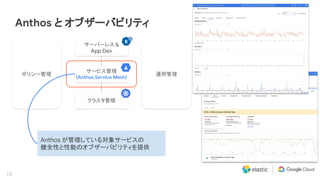
Elastic 同様に私達 Google Cloud もマルチクラウドおよびハイブリッド クラウドによる顧客システムのモダナイゼーションに注力しています。その中核にあたるソリューションとして Anthos を提供し、またオペレーションの観点では Site Reliability Engineering (SRE) を提唱しています。本セッションでは、Anthos と Elastic Stack のインテグレーション、そして SRE アプローチについて説明します。

![[Cloud OnAir] Google Compute Engine に Deep Dive! 基本から運用時のベストプラクティスまで 2018年7月1...](https://cdn.slidesharecdn.com/ss_thumbnails/uuuuuu-180719094903-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Cloud OnAir] Apigee でかんたん API 管理 2019年12月12日 放送](https://cdn.slidesharecdn.com/ss_thumbnails/1212-191212033259-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Cloud OnAir] Google Cloud Next '20: OnAir 特別編 〜世界で人気のあったセッション特集〜 2020年9月24日 放送](https://cdn.slidesharecdn.com/ss_thumbnails/ooo-200924094839-thumbnail.jpg?width=640&height=640&fit=bounds)


![[Cloud OnAir] Talks by DevRel Vol.5 アプリケーションのモダナイゼーション 2020年9月3日 放送](https://cdn.slidesharecdn.com/ss_thumbnails/ffffffffffffffff-200903090943-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Cloud OnAir] 【Anthos 演習】 解説を聞きながら Anthos を体験しよう 2020年11月5日 放送](https://cdn.slidesharecdn.com/ss_thumbnails/ab-201105085037-thumbnail.jpg?width=640&height=640&fit=bounds)



![[GKE & Spanner 勉強会] GKE 入門](https://cdn.slidesharecdn.com/ss_thumbnails/gke01-200121090059-thumbnail.jpg?width=640&height=640&fit=bounds)










![[Cloud OnAir] 事例紹介 : 株式会社マーケティングアプリケーションズ 〜クラウドへのマイグレーションとその後〜 2020年12月17日 放送](https://cdn.slidesharecdn.com/ss_thumbnails/ppp-201221033858-thumbnail.jpg?width=640&height=640&fit=bounds)















![[Cloud OnAir] Next ’19 サンフランシスコ最新情報 GCP 特集 2019年4月11日 放送](https://cdn.slidesharecdn.com/ss_thumbnails/0411-190411083444-thumbnail.jpg?width=640&height=640&fit=bounds)












![Modernising One Legal Se@rch with Elastic Enterprise Search [Customer Story]](https://cdn.slidesharecdn.com/ss_thumbnails/modernisingonelegalserchwithelastic-jsedit14thjune2021-210625013449-thumbnail.jpg?width=640&height=640&fit=bounds)



















