Download as PDF, PPTX






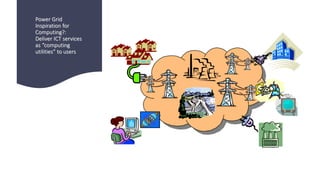

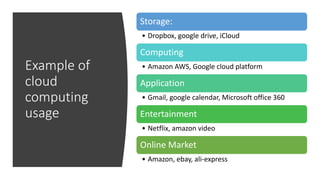


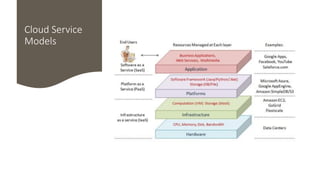








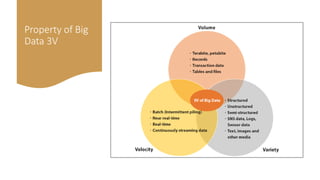
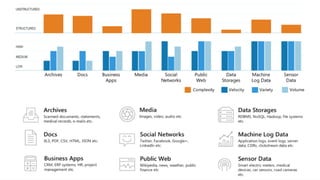

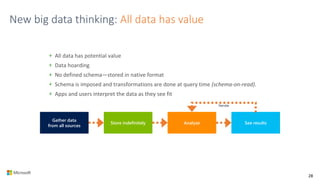
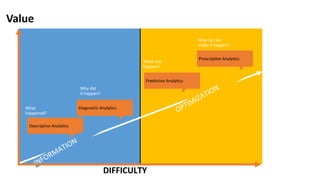

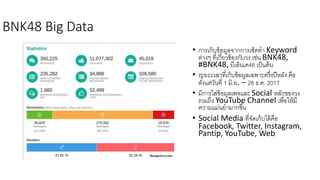
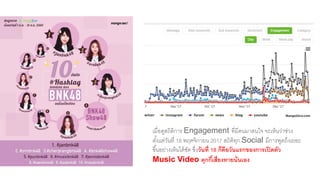

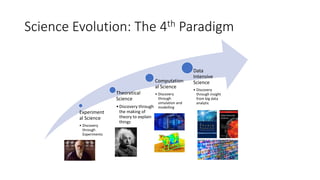











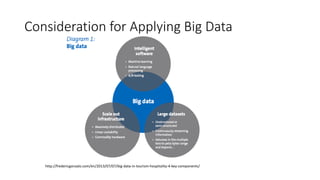








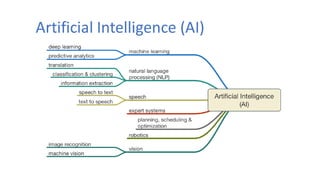



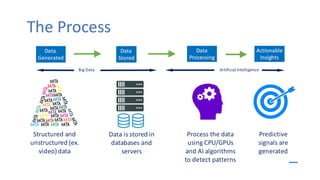
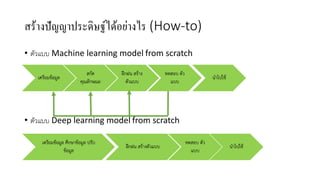

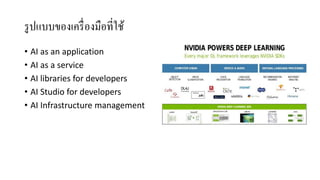
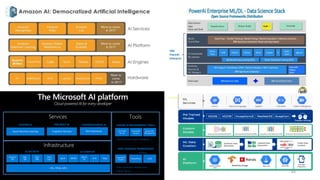
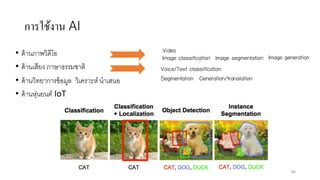













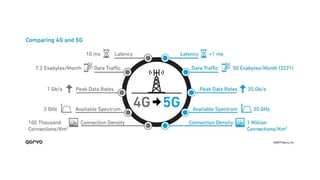
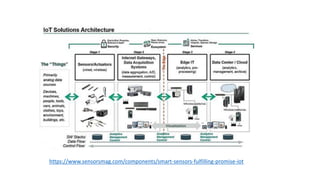
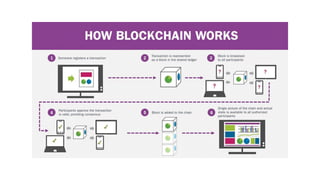
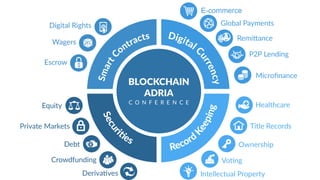




AI is the science and engineering of creating intelligent machines and software. It draws from fields like computer science, biology, psychology and linguistics. The goal is to develop systems that can perform tasks normally requiring human intelligence, like visual perception, decision making and language translation. Some key applications of AI include machine learning, expert systems, natural language processing and computer vision. As AI systems continue advancing, they are becoming better than humans at certain tasks like playing strategic games.


















































































