Download to read offline







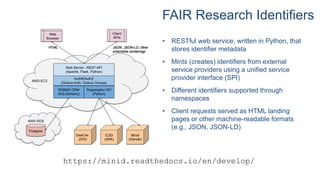

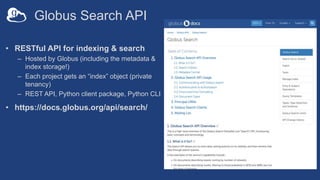
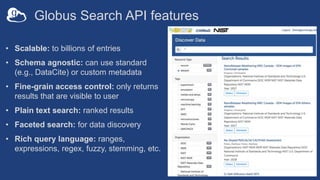



The document outlines automated data ingestion processes for science gateways using Globus, emphasizing challenges such as transferring large datasets and managing metadata effectively. Key components include the use of Globus Connect Server for data storage, persistent identifiers through a fair research identifier service, and the implementation of a RESTful API for metadata management. It also details the Globus Search API features that facilitate scalable indexing and search capabilities for indexed metadata.























































































