Download to read offline























![Data ingest with Globus Search
31
Search
Index
POST /index/{index_id}/ingest'
{
"ingest_type": "GMetaList",
"ingest_data": {
"gmeta": [
{
"id": "filetype",
"subject”: "https://search.api.globus.org/abc.txt",
"visible_to": ["public"],
"content": {
"metadata-schema/file#type": "file”
}
},
...
]
}
- Bulk create and update
- Task model for ingest at scale](https://image.slidesharecdn.com/211114sc21tutorialdiscoverability-211203055759/85/Enabling-Secure-Data-Discoverability-SC21-Tutorial-31-320.jpg)
![Data ingest with Globus Search
32
Search
Index
POST /index/{index_id}/ingest'
{
"ingest_type": "GMetaList",
"ingest_data": {
"gmeta": [
{
"id": ”weight",
"subject": "https://search.api.globus.org/abc.txt",
"visible_to": ["urn:globus:auth:identity:46bd0f56-
e24f-11e5-a510-131bef46955c"],
"content": {
"metadata-schema/file#size": ”37.6",
"metadata-schema/file#size_human": ”<50lb”
}
},
...
]
}
Visibility limited to Globus Auth identity
- Single user
- Globus Group
- Registered client application](https://image.slidesharecdn.com/211114sc21tutorialdiscoverability-211203055759/85/Enabling-Secure-Data-Discoverability-SC21-Tutorial-32-320.jpg)
![Data discovery with Globus Search
33
{
"@datatype": "GSearchResult",
"@version": "2017-09-01",
"count": 1,
"gmeta": [
{
"@datatype": "GMetaResult",
"@version": "2019-08-27",
"entries": [
{ ... }
],
"subject": "https://..."
}
],
"offset": 0,
"total": 1
}
GET /index/{index_id}/search?q=type%3Ahdf5
Search
Index
Simple query](https://image.slidesharecdn.com/211114sc21tutorialdiscoverability-211203055759/85/Enabling-Secure-Data-Discoverability-SC21-Tutorial-33-320.jpg)
![Data discovery with Globus Search
34
POST /index/{index_id}/search
Search
Index
Complex query
{
"filters": [
{
"type": "range",
"field_name": ”pubdate",
"values": [
{
"from": "*",
"to": "2020-12-31"
}
]
}
],
"facets": [
{
"name": "Publication Date",
"field_name": "pubdate",
...
}
]
}
Filter
Facets
Boosts
Sort
Limit](https://image.slidesharecdn.com/211114sc21tutorialdiscoverability-211203055759/85/Enabling-Secure-Data-Discoverability-SC21-Tutorial-34-320.jpg)


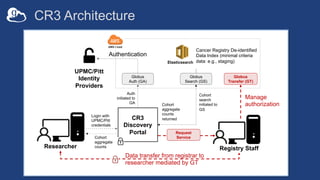












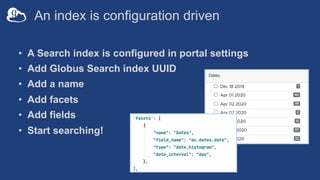


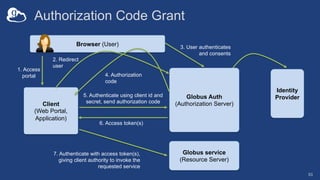
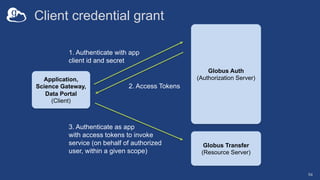








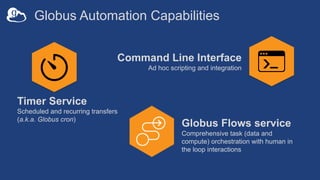

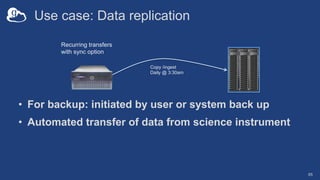

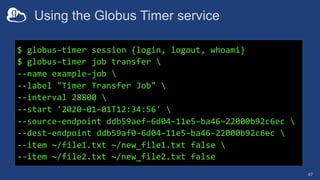
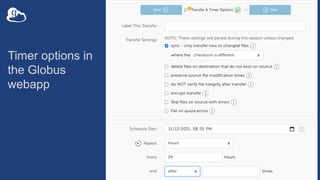





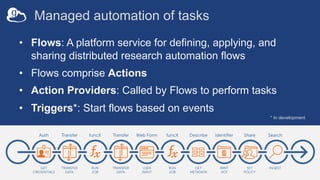

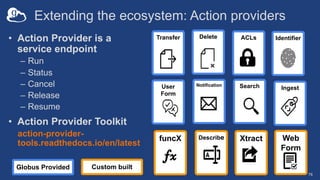
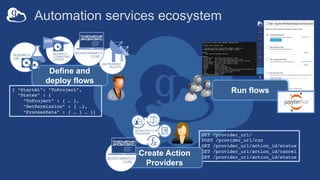




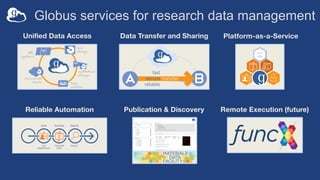
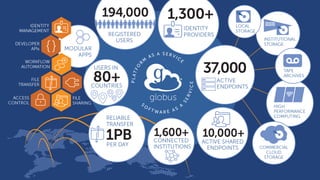
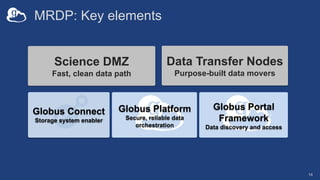
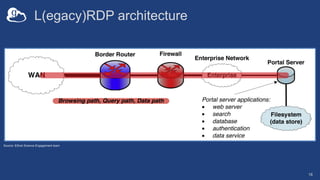
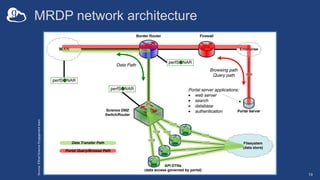
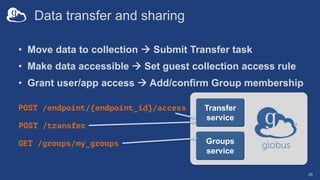
The document discusses the design and implementation of a modern research data portal using Globus services to enhance data discoverability and secure collaboration. Key features include data management, process automation, and user authentication to facilitate access and sharing of heterogeneous data in research environments. The presentation also covers various components of the Globus platform, automation capabilities, and the importance of making research data FAIR (Findable, Accessible, Interoperable, and Reusable).










































































![谷歌留痕技术教程[ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130173900-2eb784f9-thumbnail.jpg?width=640&height=640&fit=bounds)












