Download to read offline


















![Understanding Incentives is Critical
50
Meeting Award
Requirements
Smoothing
Dislocations
Increasing
Impact
• Increase paper citations1
• Add dataset citation capabilities
• [Distance] Enable simple sharing among
collaborators (near and far)
• [Personnel] Ease transitions between students
• [Format] Lessen need for ad hoc resource sharing
(e.g. via group websites)
• Simplify DMP compliance
1 Citation increase 30 (10.7717/peerj.175) - 60% (10.1371/journal.pone.0000308) [caveat bio research]](https://image.slidesharecdn.com/20160922-mdf-nist-webinar-f-160927144535/75/20160922-Materials-Data-Facility-TMS-Webinar-42-2048.jpg)
![Lessons Learned
51
• The demand is there from researchers and
institutions
• Lots of cross-over with centers and projects
§ (NIST) CHiMaD
§ (DOE) ElectroCat, MICCoM, JCESR, PRISMS, Argonne IT, Integrated Imaging Institute
§ (NSF) T2C2 [DIBBS], AMI-CFP (PIRE), HV/TMS (I/UCRC), BD Hubs, IMaD BD Spoke*
• Data Heterogeneity is a challenge
§ Metadata is the major sticking point
• Friction points
§ Need more flexible data objects e.g. {“temperature”:100, “unit”:“K”}
§ Need file or directory based metadata
§ Immutable datasets alone is not enough à Versioning
§ Data gathering in retrospect
§ Schema generation and interoperability
§ Working with and following developments at NIST, RDA, Citrine et al.
§ Differing institutional approval processes
§ Lack of programmatic interface (planned).
• Support for data interactivity and visualization
• Smart versioning for large file-based datasets](https://image.slidesharecdn.com/20160922-mdf-nist-webinar-f-160927144535/75/20160922-Materials-Data-Facility-TMS-Webinar-43-2048.jpg)


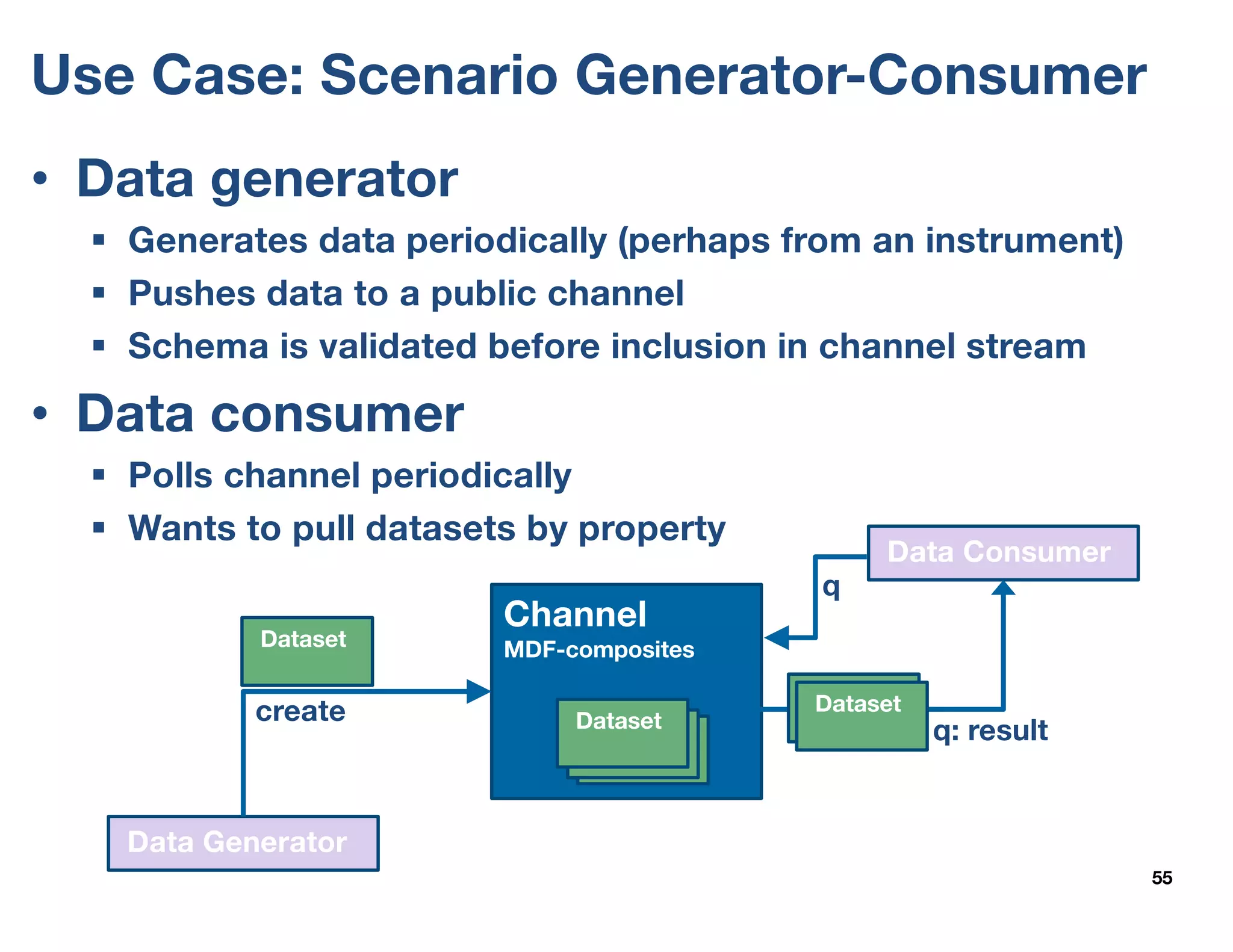
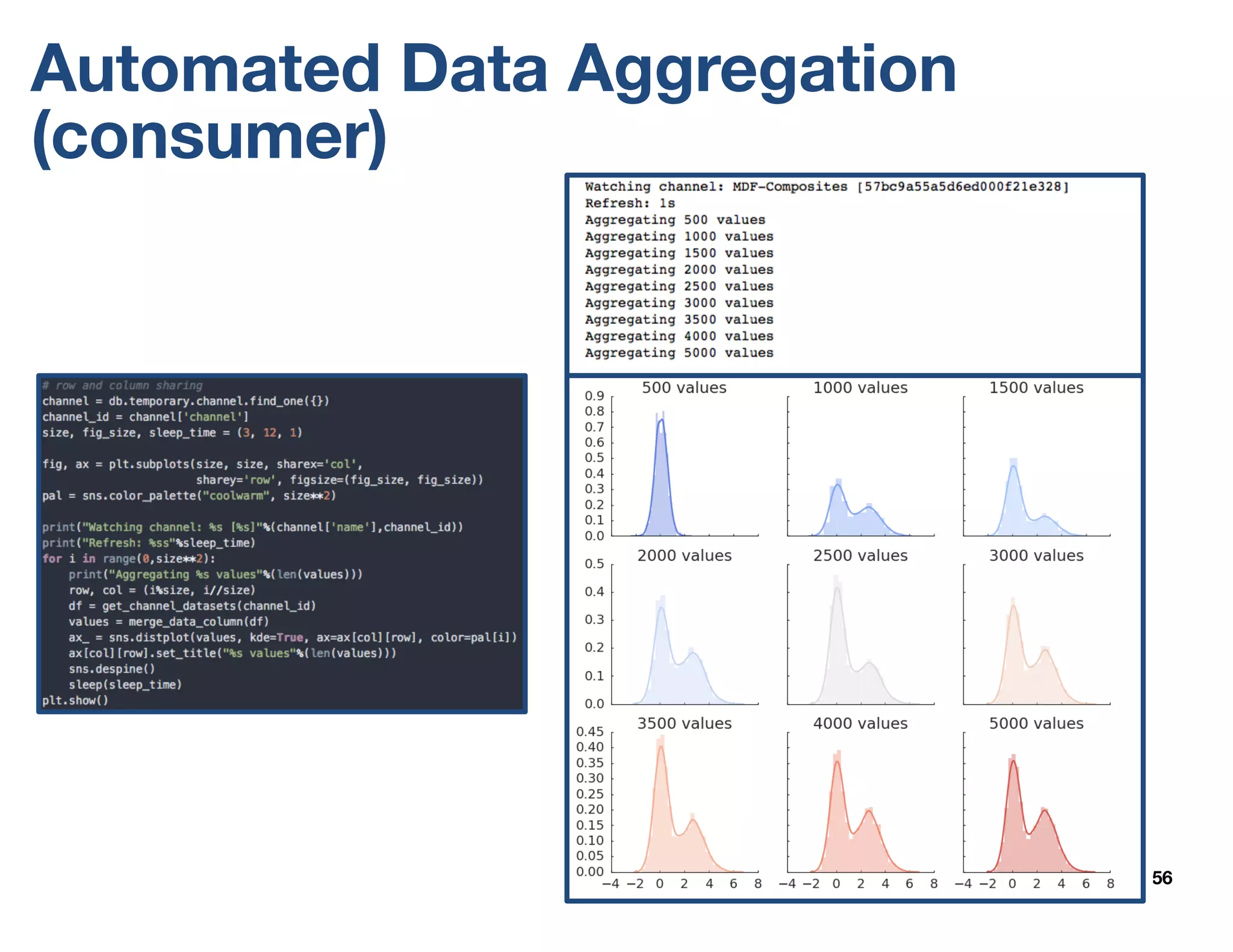

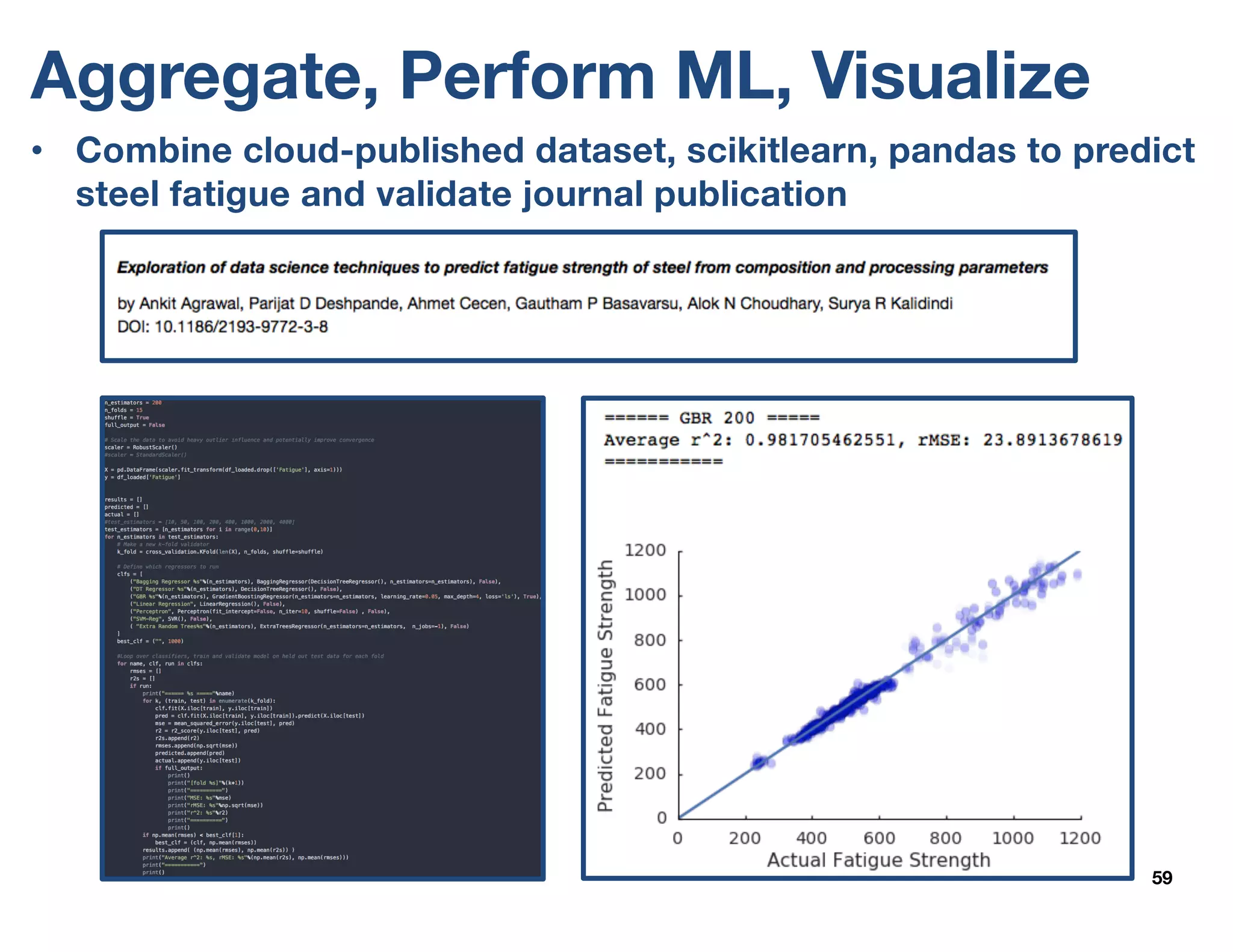





The document outlines the development and features of the Materials Data Facility (MDF), which aims to simplify the publication, discovery, and use of materials datasets through a series of APIs and cloud-hosted services. It discusses the challenges of materials data publication, including the need for unique identifiers, metadata schemas, and automated curation workflows. Furthermore, the MDF is positioned as a valuable resource for researchers, promoting data accessibility and collaboration in the materials science community.













































































