Download as PDF, PPTX







![Classification and Regression Trees [Breiman et al, 1984]
MedInc <= 5.04
MedInc <= 3.07
AveRooms <= 4.31
1.62
1.16
MedInc <= 6.82
AveOccup <= 2.37
AveOccup <= 2.74
2.79
1.88
3.39
2.56
sklearn.tree.DecisionTreeClassifier|Regressor
MedInc <= 7.82
3.73
4.57](https://image.slidesharecdn.com/slides-140224130205-phpapp02/75/Gradient-Boosted-Regression-Trees-in-scikit-learn-8-2048.jpg)
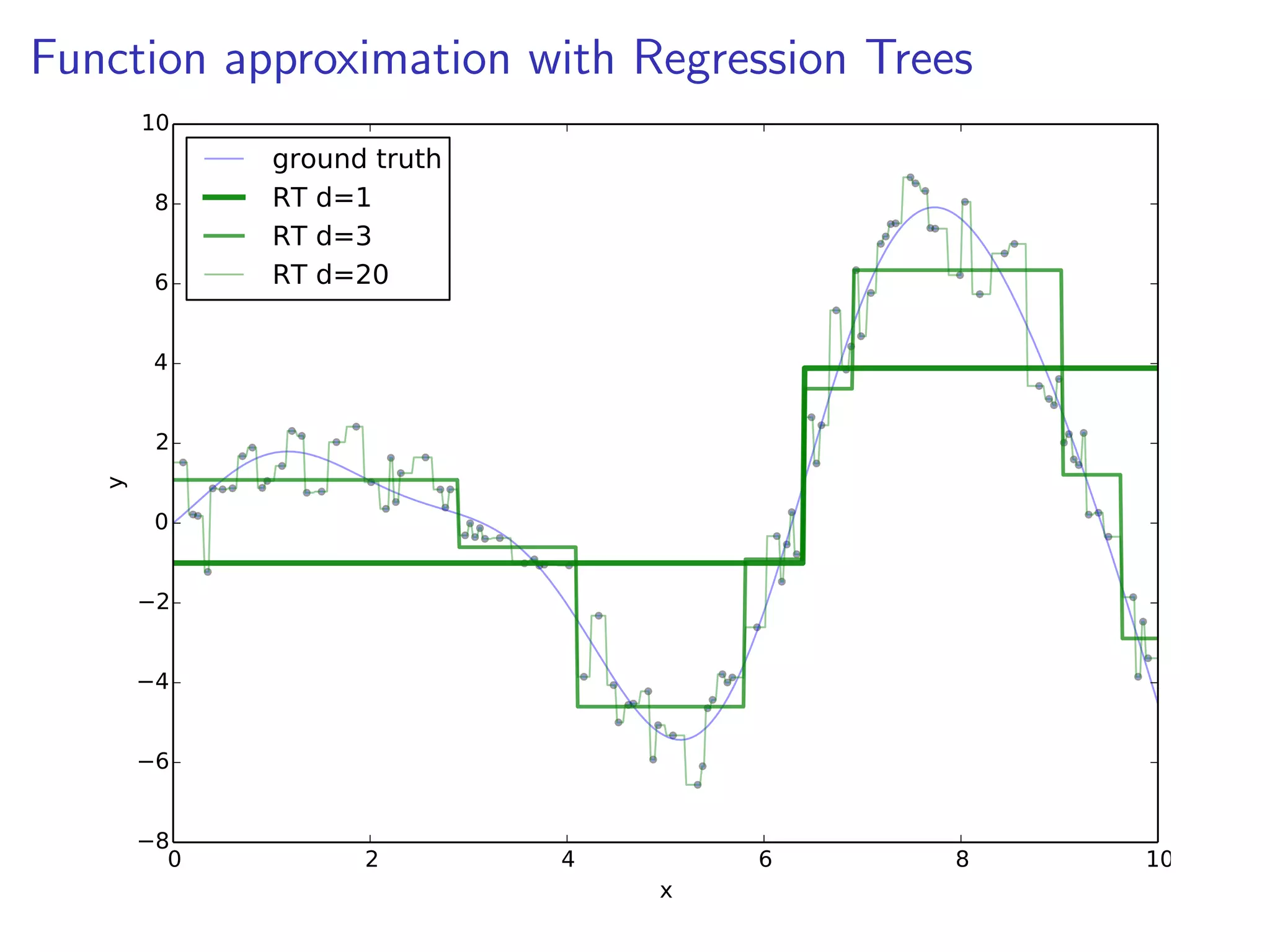

![Boosting
AdaBoost [Y. Freund & R. Schapire, 1995]
• Ensemble: each member is an expert on the errors of its
predecessor
• Iteratively re-weights training examples based on errors
2
x1
1
0
1
2
2
1
0
x0
1
2
3
2
1
0
x0
1
2
3
2
1
0
x0
1
2
sklearn.ensemble.AdaBoostClassifier|Regressor
3
2
1
0
x0
1
2
3](https://image.slidesharecdn.com/slides-140224130205-phpapp02/75/Gradient-Boosted-Regression-Trees-in-scikit-learn-13-2048.jpg)
![Boosting
Huge success
AdaBoost [Y. Freund & R. Schapire, 1995]
• Viola-Jones Face Detector (2001)
• Ensemble: each member is an expert on the errors of its
predecessor
• Iteratively re-weights training examples based on errors
2
x1
1
0
1
2
2
1
0
x0
1
2
3
2
1
0
x0
1
2
3
2
1
0
x0
1
2
3
2
1
• Freund & Schapire won the G¨del prize 2003
o
sklearn.ensemble.AdaBoostClassifier|Regressor
0
x0
1
2
3](https://image.slidesharecdn.com/slides-140224130205-phpapp02/75/Gradient-Boosted-Regression-Trees-in-scikit-learn-14-2048.jpg)
![Gradient Boosting [J. Friedman, 1999]
Statistical view on boosting
• ⇒ Generalization of boosting to arbitrary loss functions](https://image.slidesharecdn.com/slides-140224130205-phpapp02/75/Gradient-Boosted-Regression-Trees-in-scikit-learn-15-2048.jpg)
![Gradient Boosting [J. Friedman, 1999]
Statistical view on boosting
• ⇒ Generalization of boosting to arbitrary loss functions
y
Residual fitting
2.5
2.0
1.5
1.0
0.5
0.0
0.5
1.0
1.5
2.0
Ground truth
tree 1
+
∼
2
x
6
10
tree 2
2
x
6
10
tree 3
+
2
x
6
10
2
sklearn.ensemble.GradientBoostingClassifier|Regressor
x
6
10](https://image.slidesharecdn.com/slides-140224130205-phpapp02/75/Gradient-Boosted-Regression-Trees-in-scikit-learn-16-2048.jpg)


![GBRT in scikit-learn
How to use it
>>> from sklearn.ensemble import GradientBoostingClassifier
>>> from sklearn.datasets import make_hastie_10_2
>>> X, y = make_hastie_10_2(n_samples=10000)
>>> est = GradientBoostingClassifier(n_estimators=200, max_depth=3)
>>> est.fit(X, y)
...
>>> # get predictions
>>> pred = est.predict(X)
>>> est.predict_proba(X)[0] # class probabilities
array([ 0.67, 0.33])
Implementation
• Written in pure Python/Numpy (easy to extend).
• Builds on top of sklearn.tree.DecisionTreeRegressor (Cython).
• Custom node splitter that uses pre-sorting (better for shallow trees).](https://image.slidesharecdn.com/slides-140224130205-phpapp02/75/Gradient-Boosted-Regression-Trees-in-scikit-learn-20-2048.jpg)
![Example
from sklearn.ensemble import GradientBoostingRegressor
est = GradientBoostingRegressor(n_estimators=2000, max_depth=1).fit(X, y)
for pred in est.staged_predict(X):
plt.plot(X[:, 0], pred, color=’r’, alpha=0.1)
10
8
6
ground truth
RT d=1
RT d=3
GBRT d=1
High bias - low variance
4
y
2
0
2
4
Low bias - high variance
6
8
0
2
4
x
6
8
10](https://image.slidesharecdn.com/slides-140224130205-phpapp02/75/Gradient-Boosted-Regression-Trees-in-scikit-learn-21-2048.jpg)
![Model complexity & Overfitting
test_score = np.empty(len(est.estimators_))
for i, pred in enumerate(est.staged_predict(X_test)):
test_score[i] = est.loss_(y_test, pred)
plt.plot(np.arange(n_estimators) + 1, test_score, label=’Test’)
plt.plot(np.arange(n_estimators) + 1, est.train_score_, label=’Train’)
2.0
Test
Train
Error
1.5
1.0
Lowest test error
0.5
train-test gap
0.0
0
200
400
n_estimators
600
800
1000](https://image.slidesharecdn.com/slides-140224130205-phpapp02/75/Gradient-Boosted-Regression-Trees-in-scikit-learn-22-2048.jpg)
![Model complexity & Overfitting
test_score = np.empty(len(est.estimators_))
for i, pred in enumerate(est.staged_predict(X_test)):
test_score[i] = est.loss_(y_test, pred)
plt.plot(np.arange(n_estimators) + 1, test_score, label=’Test’)
plt.plot(np.arange(n_estimators) + 1, est.train_score_, label=’Train’)
2.0
Test
Train
Regularization
1.5
GBRT provides a number of knobs to control
overfitting
Error
Lowest test
•1.0Tree structure error
• Shrinkage
• Stochastic Gradient Boosting
0.5
train-test gap
0.0
0
200
400
n_estimators
600
800
1000](https://image.slidesharecdn.com/slides-140224130205-phpapp02/75/Gradient-Boosted-Regression-Trees-in-scikit-learn-23-2048.jpg)
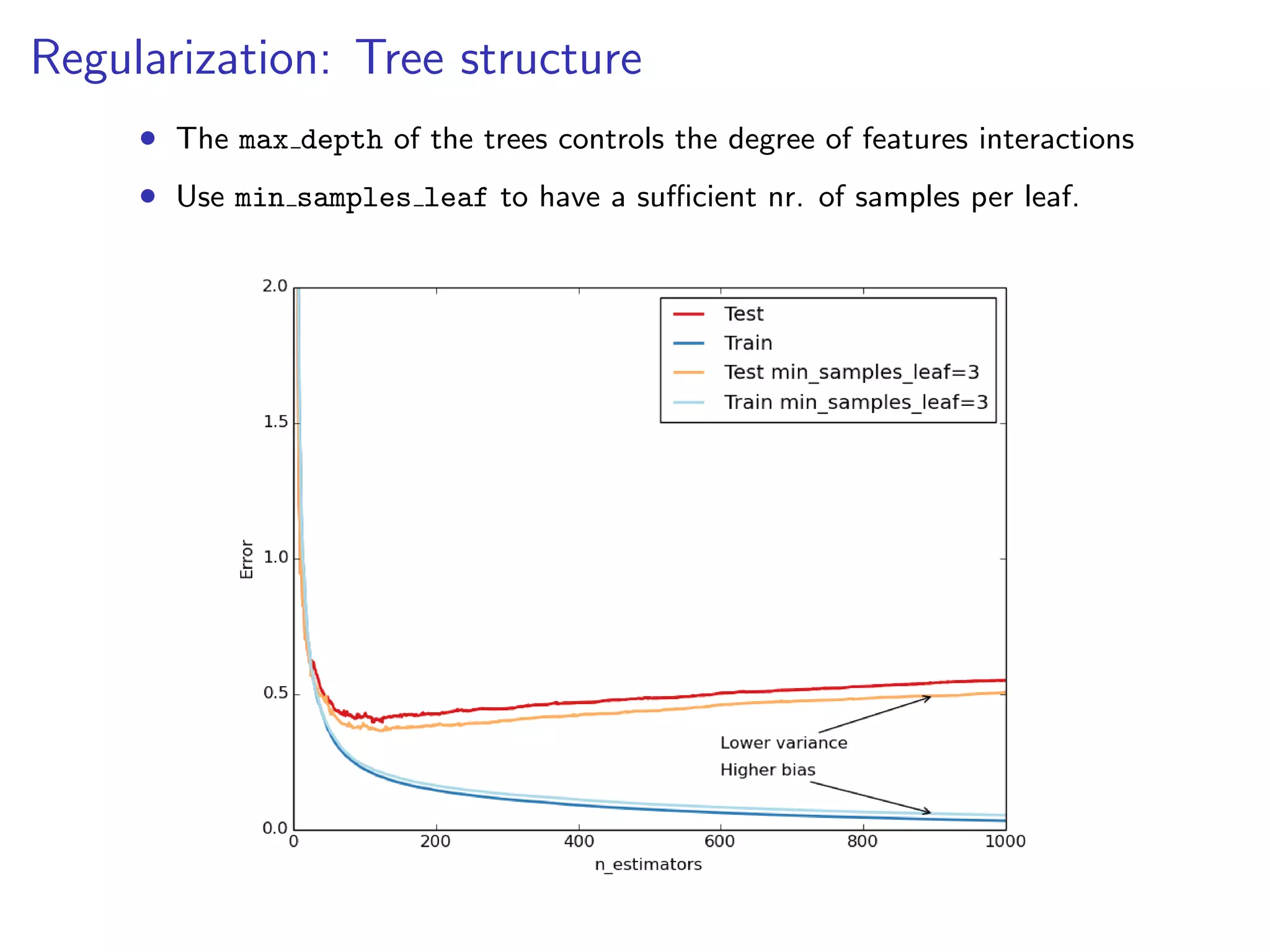

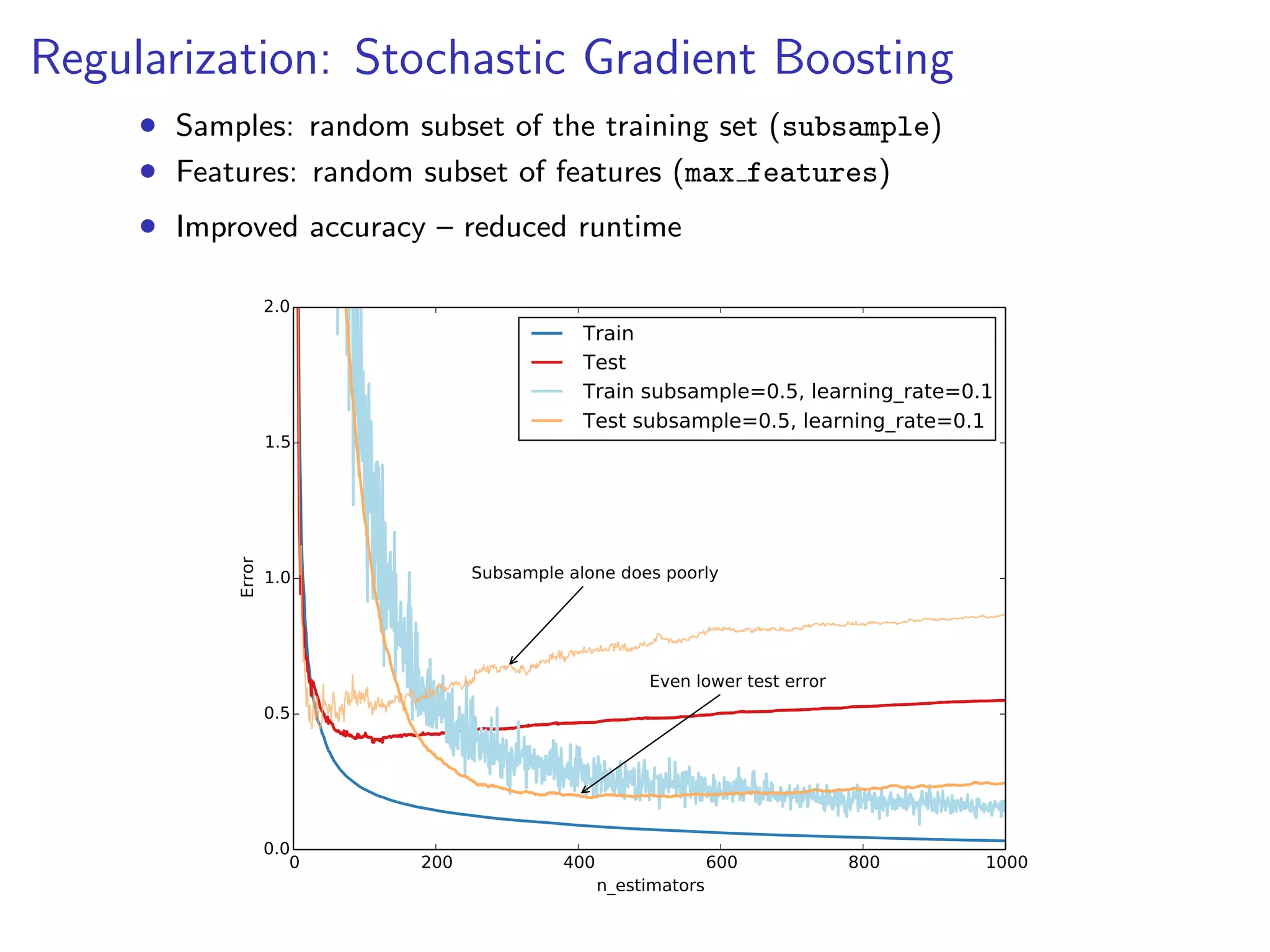
![Hyperparameter tuning
1. Set n estimators as high as possible (eg. 3000)
2. Tune hyperparameters via grid search.
from sklearn.grid_search import GridSearchCV
param_grid = {’learning_rate’: [0.1, 0.05, 0.02, 0.01],
’max_depth’: [4, 6],
’min_samples_leaf’: [3, 5, 9, 17],
’max_features’: [1.0, 0.3, 0.1]}
est = GradientBoostingRegressor(n_estimators=3000)
gs_cv = GridSearchCV(est, param_grid).fit(X, y)
# best hyperparameter setting
gs_cv.best_params_
3. Finally, set n estimators even higher and tune
learning rate.](https://image.slidesharecdn.com/slides-140224130205-phpapp02/75/Gradient-Boosted-Regression-Trees-in-scikit-learn-27-2048.jpg)

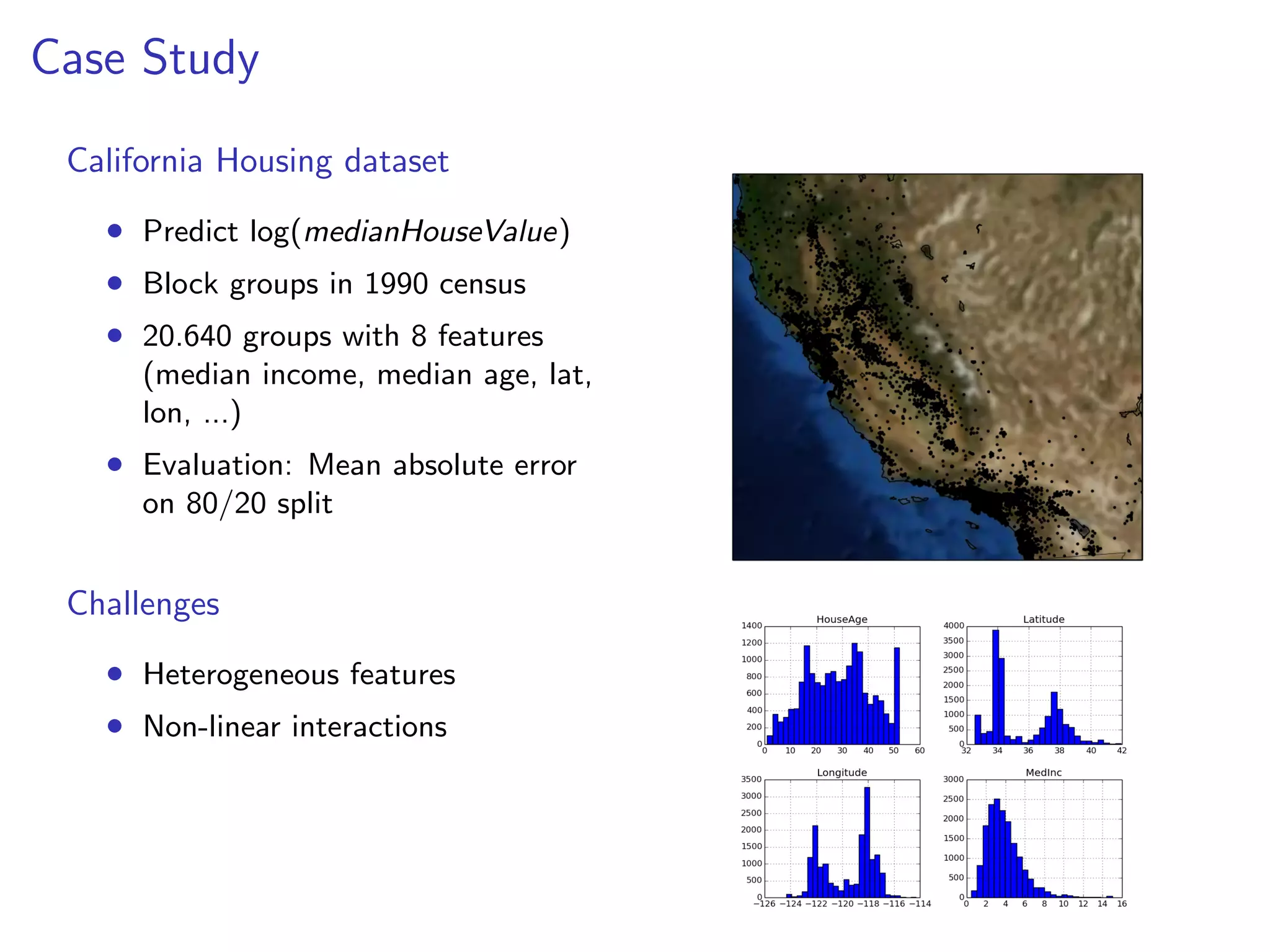
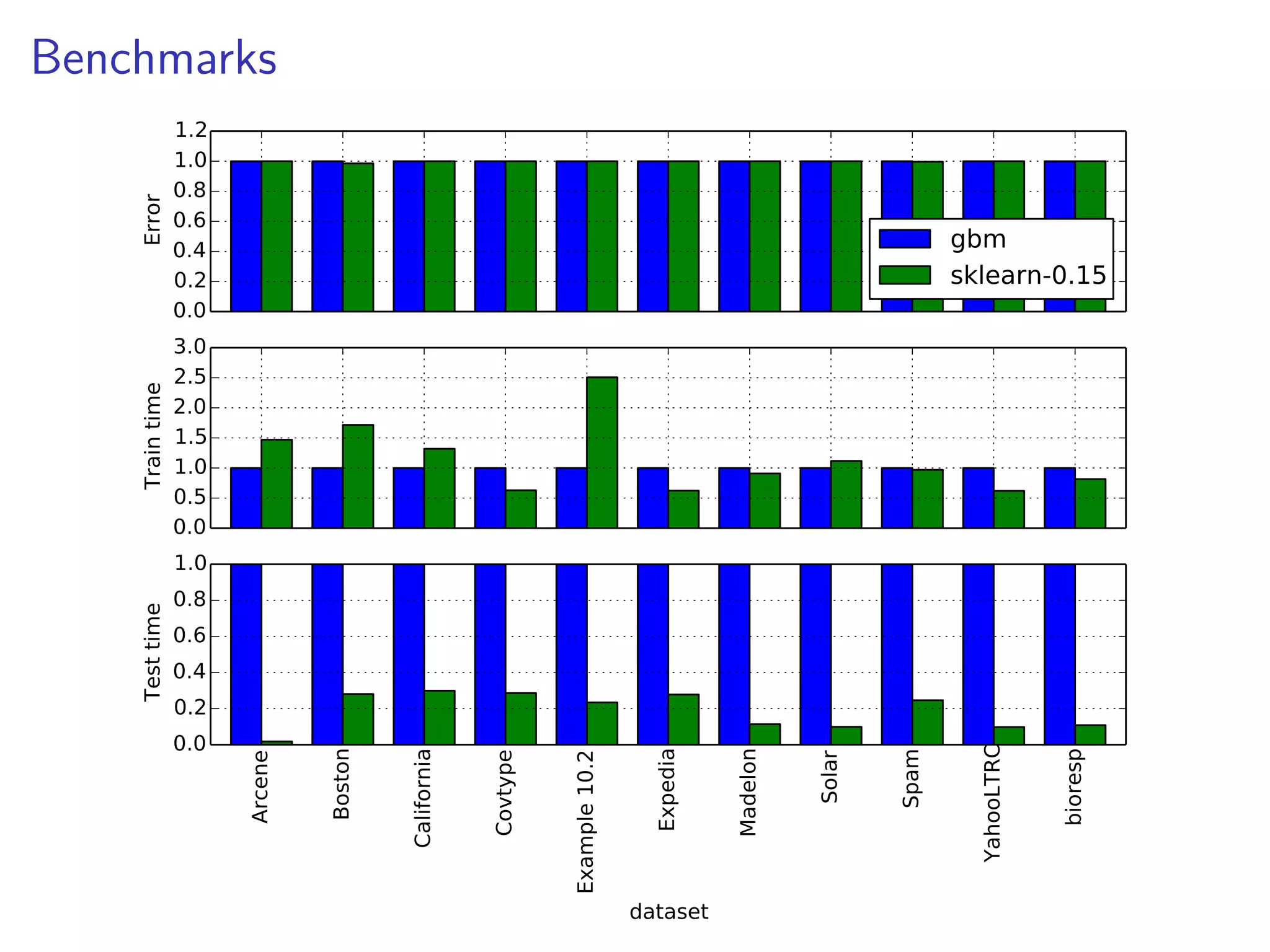
![Predictive accuracy & runtime
Mean
Ridge
SVR
RF
GBRT
Train time [s]
0.006
28.0
26.3
192.0
Test time [ms]
0.11
2000.00
605.00
439.00
MAE
0.4635
0.2756
0.1888
0.1620
0.1438
0.5
Test
Train
0.4
error
0.3
0.2
0.1
0.0
0
500
1000
1500
n_estimators
2000
2500
3000](https://image.slidesharecdn.com/slides-140224130205-phpapp02/75/Gradient-Boosted-Regression-Trees-in-scikit-learn-30-2048.jpg)
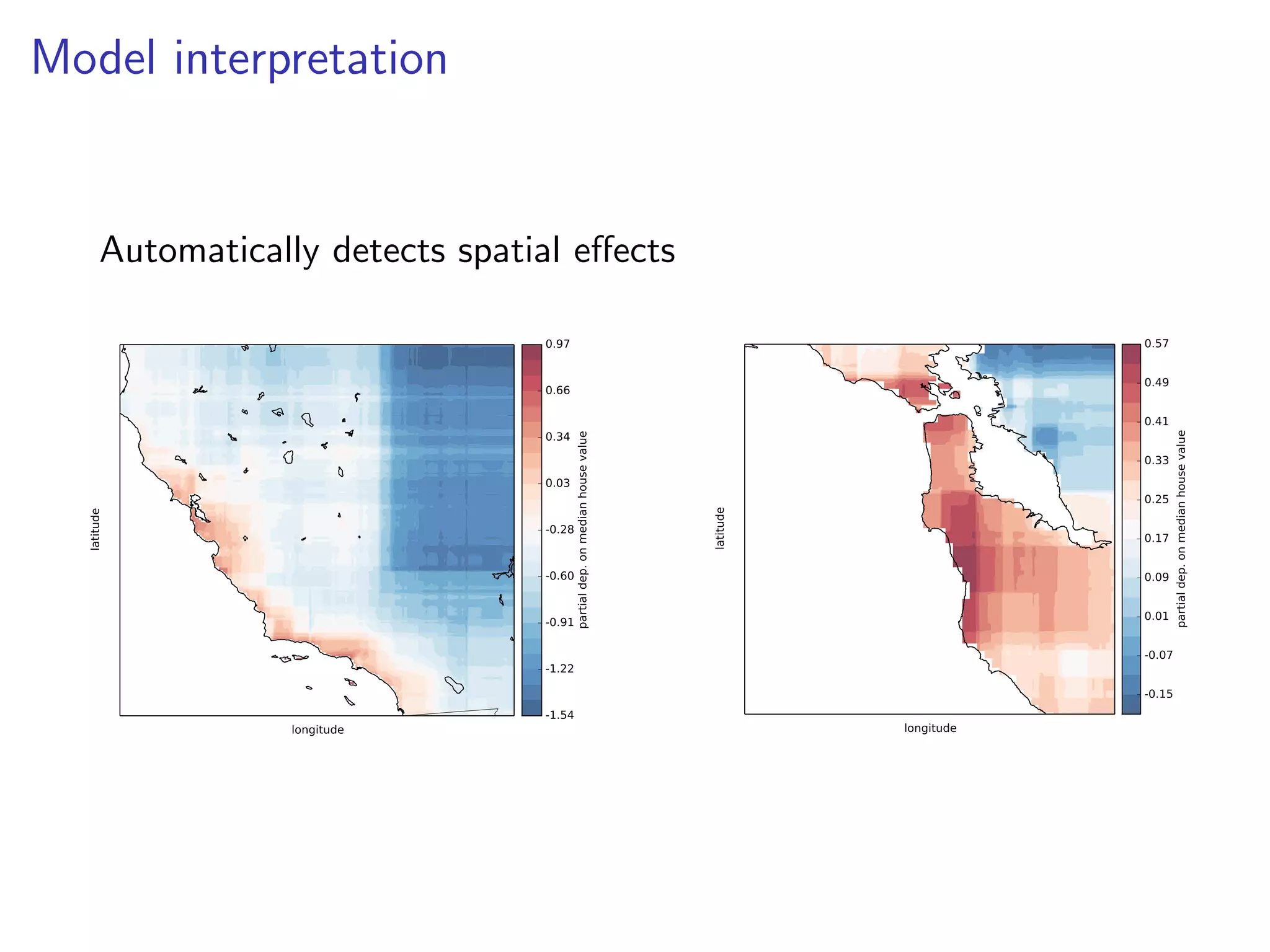
![Model interpretation
Which features are important?
>>> est.feature_importances_
array([ 0.01, 0.38, ...])
MedInc
AveRooms
Longitude
AveOccup
Latitude
AveBedrms
Population
HouseAge
0.00
0.02
0.04
0.06
0.08 0.10 0.12
Relative importance
0.14
0.16
0.18](https://image.slidesharecdn.com/slides-140224130205-phpapp02/75/Gradient-Boosted-Regression-Trees-in-scikit-learn-31-2048.jpg)
![Model interpretation
What is the effect of a feature on the response?
from sklearn.ensemble import partial_dependence import as pd
Partial dependence
-0.12
0.09
0.2
3
0.02
0.16
-0.05
Partial dependence
Partial dependence of house value on nonlocation features
for the California housing dataset
0.6
0.6
0.4
0.4
0.2
0.2
0.0
0.0
0.2
0.2
0.4
0.4
1.5 3.0 4.5 6.0 7.5
2.0 2.5 3.0 3.5 4.0 4.5
10 20 30 40 50 60
MedInc
AveOccup
HouseAge
0.6
50
0.4
40
0.2
30
0.0
20
0.2
0.4
10
4 5 6 7 8
2.0 2.5 3.0 3.5 4.0
AveRooms
AveOccup
0.6
0.4
0.2
0.0
0.2
0.4
HouseAge
Partial dependence
Partial dependence
features = [’MedInc’, ’AveOccup’, ’HouseAge’, ’AveRooms’,
(’AveOccup’, ’HouseAge’)]
fig, axs = pd.plot_partial_dependence(est, X_train, features,
feature_names=names)](https://image.slidesharecdn.com/slides-140224130205-phpapp02/75/Gradient-Boosted-Regression-Trees-in-scikit-learn-32-2048.jpg)



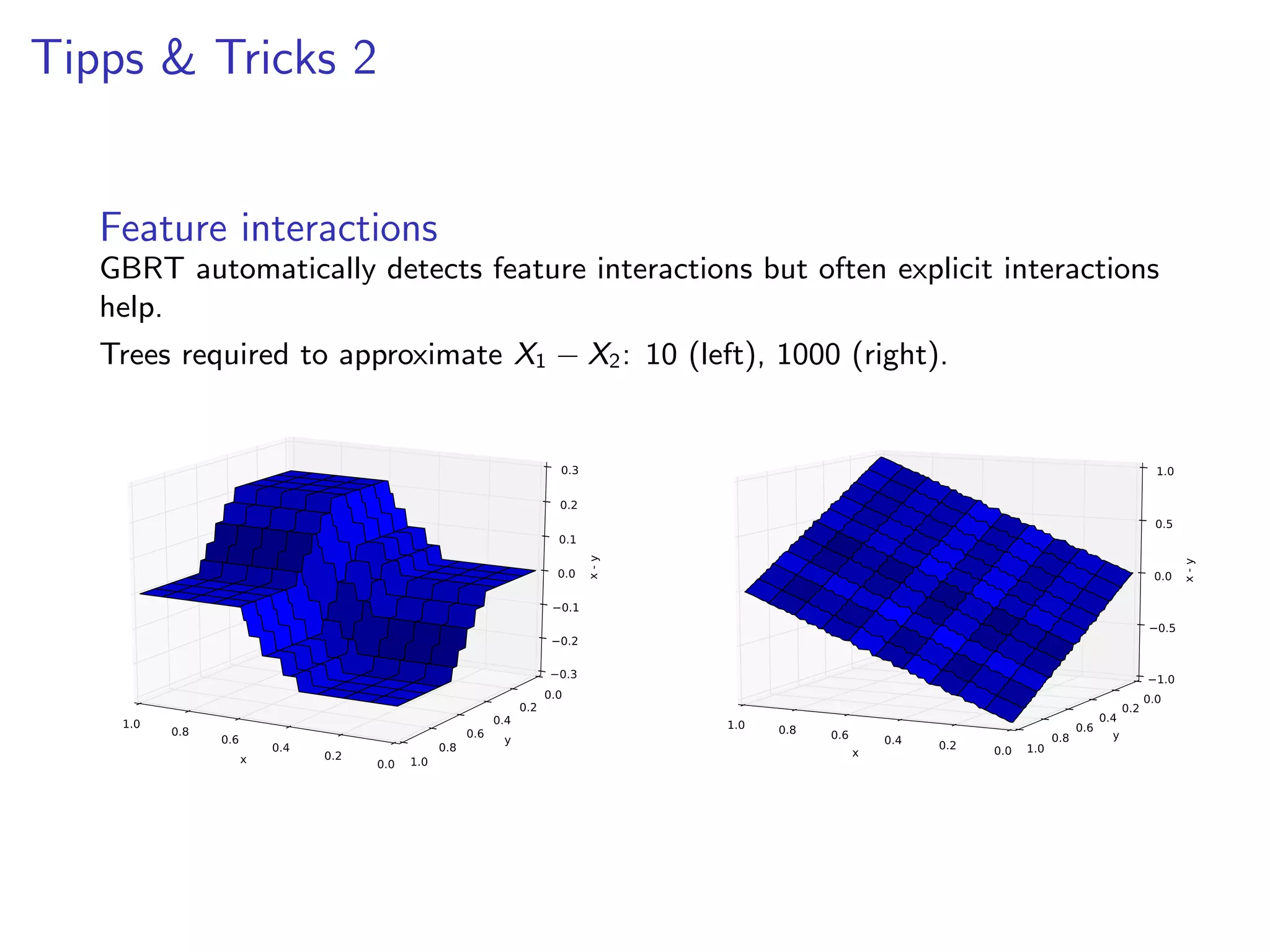
![Tipps & Tricks 3
Categorical variables
Sklearn requires that categorical variables are encoded as numerics. Tree-based
methods work well with ordinal encoding:
df = pd.DataFrame(data={’icao’: [’CRJ2’, ’A380’, ’B737’, ’B737’]})
# ordinal encoding
df_enc = pd.DataFrame(data={’icao’: np.unique(df.icao,
return_inverse=True)[1]})
X = np.asfortranarray(df_enc.values, dtype=np.float32)](https://image.slidesharecdn.com/slides-140224130205-phpapp02/75/Gradient-Boosted-Regression-Trees-in-scikit-learn-39-2048.jpg)

The document discusses the application of gradient boosted regression trees (GBRT) using the scikit-learn library, emphasizing its advantages and disadvantages in machine learning. It provides a detailed overview of gradient boosting techniques, how to implement them in scikit-learn, and includes a case study on California housing data to illustrate practical usage and challenges. Additionally, it covers hyperparameter tuning, model interpretation, and techniques for avoiding overfitting.























































































