

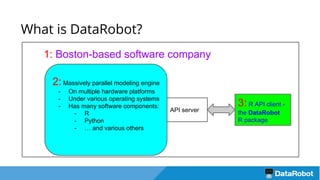
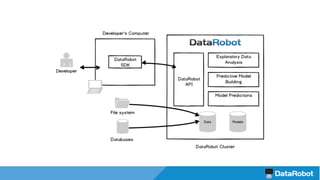



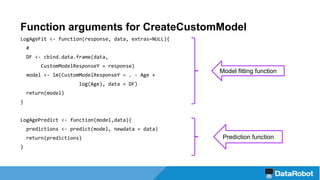



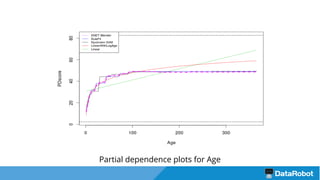
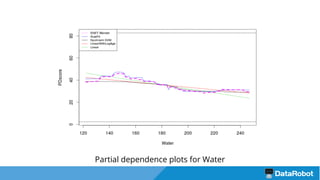
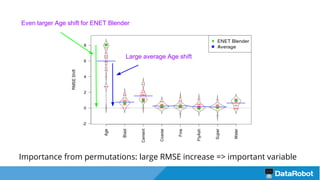

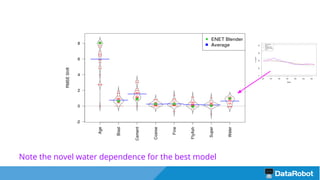



The document introduces the DataRobot R package, focusing on its capabilities as a modeling engine developed by a Boston-based company. It provides a practical example predicting the compressive strength of concrete while detailing steps for project setup, model fitting, and analysis of results using partial dependence plots. The package is nearing release and includes instructional vignettes for users.























































































