Download as PDF, PPTX































![ Make sure it is available
module avail PrgEnv-cray
To access the Cray compiler
module load PrgEnv-cray
To target the various chip
module load xtpe-[barcelona,shanghi,mc8]
Once you have loaded the module “cc” and “ftn” are the Cray
compilers
Recommend just using default options
Use –rm (fortran) and –hlist=m (C) to find out what happened
man crayftn
2011 HPCMP User Group © Cray Inc. June 20, 2011 56](https://image.slidesharecdn.com/hpcmpug2011craytutorial-110620010019-phpapp01/85/HPCMPUG2011-cray-tutorial-52-320.jpg)


![ Cray compiler supports a full and growing set of directives
and pragmas
!dir$ concurrent
!dir$ ivdep
!dir$ interchange
!dir$ unroll
!dir$ loop_info [max_trips] [cache_na] ... Many more
!dir$ blockable
man directives
man loop_info
2011 HPCMP User Group © Cray Inc. June 20, 2011 59](https://image.slidesharecdn.com/hpcmpug2011craytutorial-110620010019-phpapp01/85/HPCMPUG2011-cray-tutorial-55-320.jpg)































![for ( i = 0; i < ELEMS_PER_THREAD; i+=1 ) {
local_data[i] += global_2d[i][target];
}
for ( i = 0; i < ELEMS_PER_THREAD; i+=1 ) {
temp = pgas_get(&global_2d[i]); // Initiate the get
pgas_fence(); // makes sure the get is complete
local_data[i] += temp; // Use the local location to complete the operation
}
The compiler must
Recognize you are referencing a shared location
Initiate the load of the remote data
Make sure the transfer has completed
Proceed with the calculation
Repeat for all iterations of the loop
2011 HPCMP User Group © Cray Inc. June 20, 2011 104](https://image.slidesharecdn.com/hpcmpug2011craytutorial-110620010019-phpapp01/85/HPCMPUG2011-cray-tutorial-97-320.jpg)
![for ( i = 0; i < ELEMS_PER_THREAD; i+=1 ) {
temp = pgas_get(&global_2d[i]); // Initiate the get
pgas_fence(); // makes sure the get is complete
local_data[i] += temp; // Use the local location to complete the operation
}
Simple translation results in
Single word references
Lots of fences
Little to no latency hiding
No use of special hardware
Nothing here says “fast”
2011 HPCMP User 105
June 20, 2011 Group © Cray Inc.](https://image.slidesharecdn.com/hpcmpug2011craytutorial-110620010019-phpapp01/85/HPCMPUG2011-cray-tutorial-98-320.jpg)



![15. shared long global_1d[MAX_ELEMS_PER_THREAD * THREADS];
…
83. 1 before = upc_ticks_now();
84. 1 r8------< for ( i = 0, j = target; i < ELEMS_PER_THREAD ;
85. 1 r8 i += 1, j += THREADS ) {
86. 1 r8 n local_data[i]= global_1d[j];
87. 1 r8------> }
88. 1 after = upc_ticks_now();
1D get BW= 0.027598 Gbytes/s
2011 HPCMP User 109
June 20, 2011 Group © Cray Inc.](https://image.slidesharecdn.com/hpcmpug2011craytutorial-110620010019-phpapp01/85/HPCMPUG2011-cray-tutorial-102-320.jpg)
![15. shared long global_1d[MAX_ELEMS_PER_THREAD * THREADS];
…
101. 1 before = upc_ticks_now();
102. 1 upc_memget(&local_data[0],&global_1d[target],8*ELEMS_PER_THREAD);
103. 1
104. 1 after = upc_ticks_now();
1D get BW= 0.027598 Gbytes/s
1D upc_memget BW= 4.972960 Gbytes/s
upc_memget is 184 times faster!!
2011 HPCMP User 110
June 20, 2011 Group © Cray Inc.](https://image.slidesharecdn.com/hpcmpug2011craytutorial-110620010019-phpapp01/85/HPCMPUG2011-cray-tutorial-103-320.jpg)
![16. shared long global_2d[MAX_ELEMS_PER_THREAD][THREADS];
…
121. 1 A-------< for ( i = 0; i < ELEMS_PER_THREAD; i+=1) {
122. 1 A local_data[i] = global_2d[i][target];
123. 1 A-------> }
1D get BW= 0.027598 Gbytes/s
1D upc_memget BW= 4.972960 Gbytes/s
2D get time BW= 4.905653 Gbytes/s
Pattern matching can give you the same
performance as if using upc_memget
2011 HPCMP User 111
June 20, 2011 Group © Cray Inc.](https://image.slidesharecdn.com/hpcmpug2011craytutorial-110620010019-phpapp01/85/HPCMPUG2011-cray-tutorial-104-320.jpg)









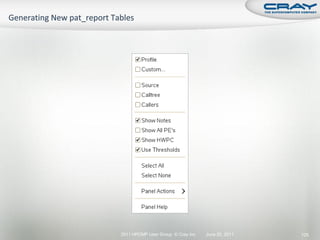


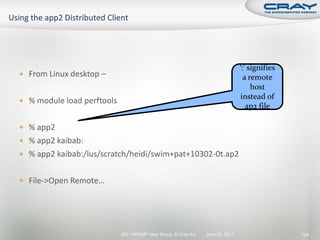

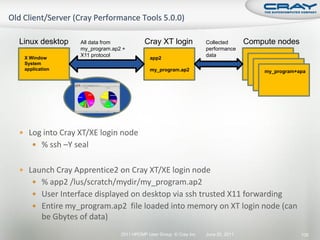
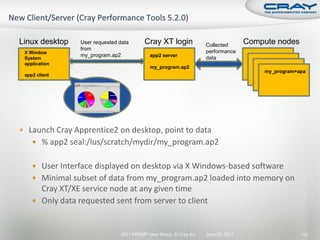
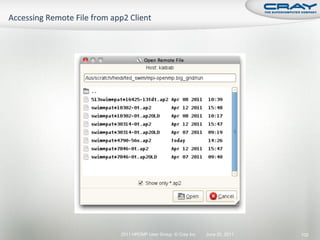














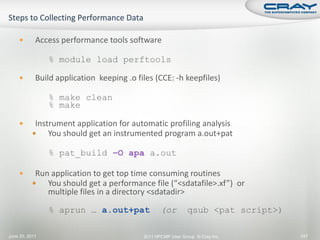
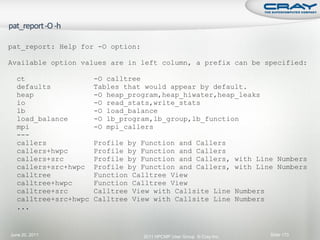
![ Generate report and .apa instrumentation file
% pat_report –o my_sampling_report [<sdatafile>.xf |
<sdatadir>]
Inspect .apa file and sampling report
Verify if additional instrumentation is needed
June 20, 2011 2011 HPCMP User Group © Cray Inc. Slide 148](https://image.slidesharecdn.com/hpcmpug2011craytutorial-110620010019-phpapp01/85/HPCMPUG2011-cray-tutorial-141-320.jpg)
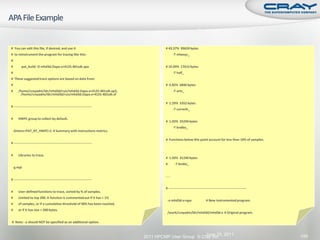



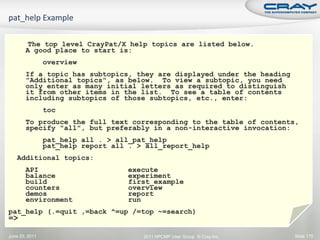
![ Instrument application for further analysis (a.out+apa)
% pat_build –O <apafile>.apa
Run application
% aprun … a.out+apa (or qsub <apa script>)
Generate text report and visualization file (.ap2)
% pat_report –o my_text_report.txt [<datafile>.xf |
<datadir>]
View report in text and/or with Cray Apprentice2
% app2 <datafile>.ap2
June 20, 2011 2011 HPCMP User Group © Cray Inc. Slide 154](https://image.slidesharecdn.com/hpcmpug2011craytutorial-110620010019-phpapp01/85/HPCMPUG2011-cray-tutorial-146-320.jpg)



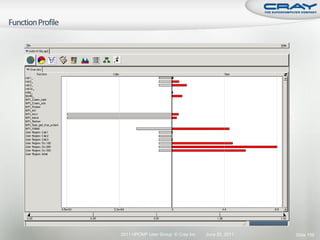
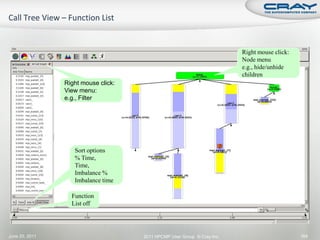
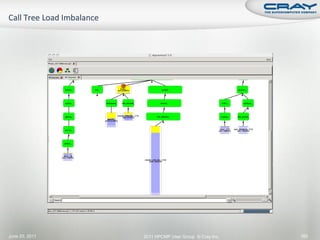
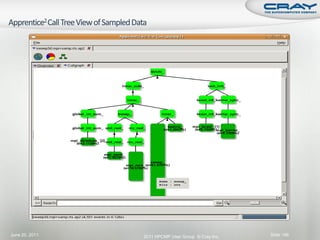
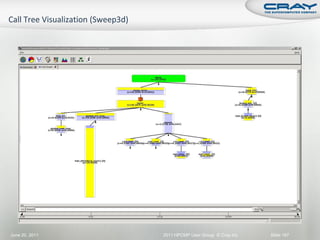







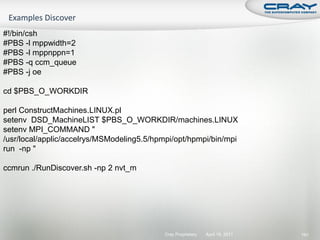
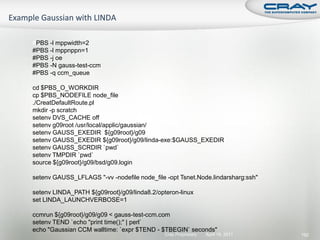
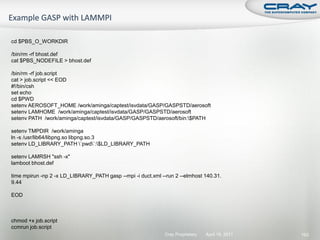
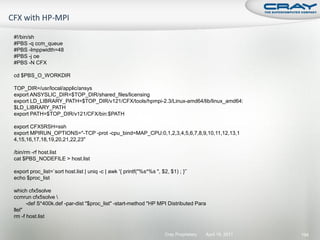












































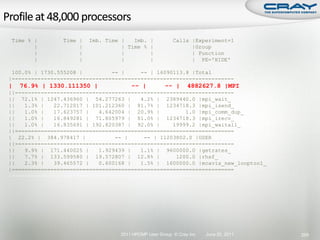

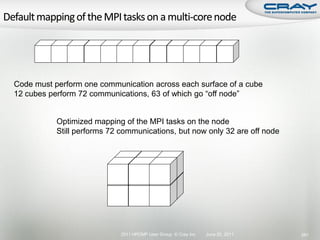
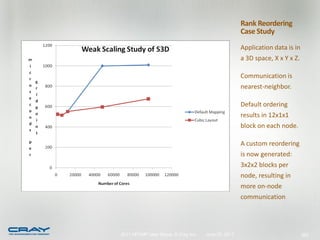
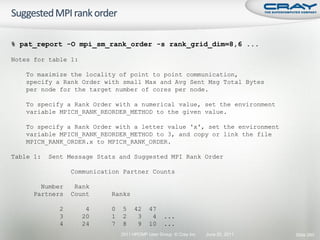













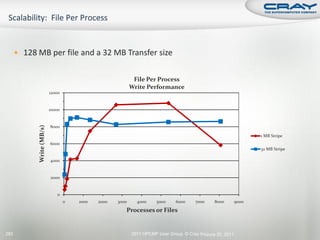
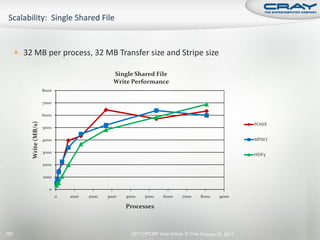


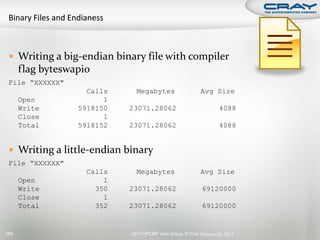

![int mode, ierr;
char tmps[24];
MPI_File fh;
MPI_Info info; Open a file across all ranks as read/write.
MPI_Status status; Hints can be set between
MPI_Info_create and MPI_File_open.
mode = MPI_MODE_CREATE|MPI_MODE_RDWR;
MPI_Info_create(&info);
MPI_File_open(comm, "output/test.dat", mode, info, &fh);
Set the “view” (offset) for each rank.
MPI_File_set_view(fh, commrank*iosize, MPI_DOUBLE, MPI_DOUBLE, "native",
info);
Collectively write from all ranks.
MPI_File_write_all(fh, dbuf, iosize/sizeof(double), MPI_DOUBLE, &status);
Close the file from all ranks.
MPI_File_close(&fh);
2011 HPCMP User Group © Cray Inc. June 20, 2011 290](https://image.slidesharecdn.com/hpcmpug2011craytutorial-110620010019-phpapp01/85/HPCMPUG2011-cray-tutorial-281-320.jpg)





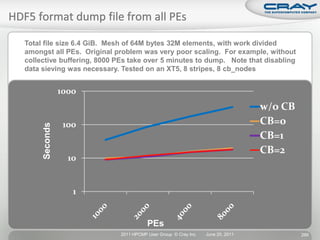




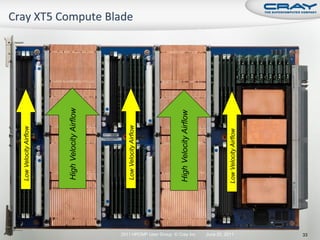
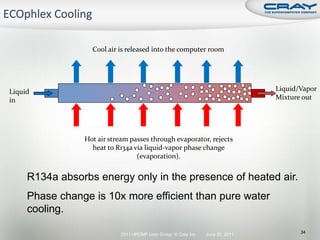
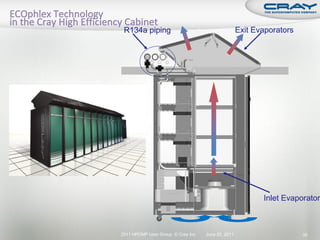
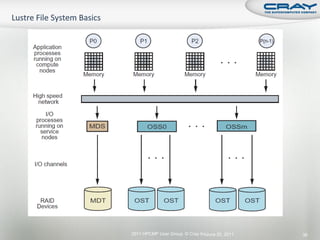
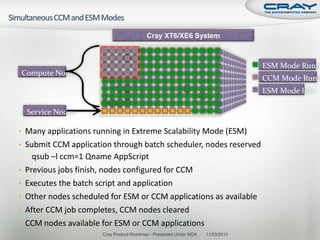
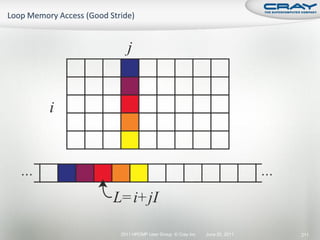
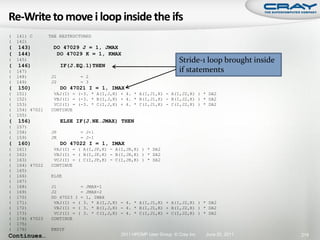
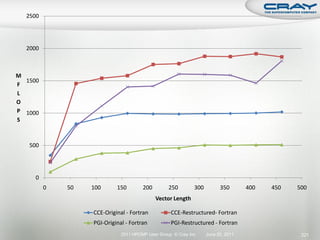
The document discusses the architecture of Cray XT and XE systems including the AMD Opteron processors, Cray interconnects like SeaStar and Gemini, and the Lustre parallel filesystem. It covers the programming environment, performance analysis tools, and optimization techniques for CPU, communication, and I/O. Diagrams and specifications are provided on the processor architecture, network topology, cooling system, and file system components.


















































































