Downloaded 55 times





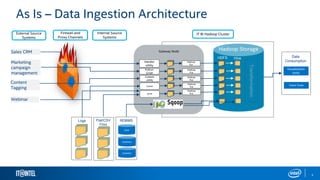



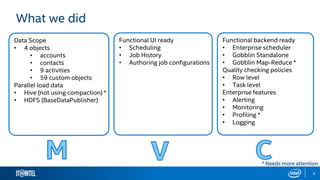
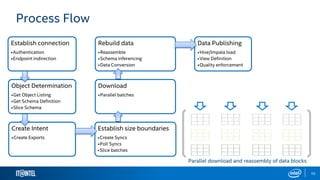





The document outlines Gobblin, a data integration framework developed by Intel, addressing the challenges of data ingestion from various sources. It highlights the framework's capabilities in ensuring data quality and enterprise readiness while identifying areas for improvement such as usability and documentation. The presentation emphasizes Gobblin's vision of empowering customers to make informed decisions through connected data and analytics.























































































