



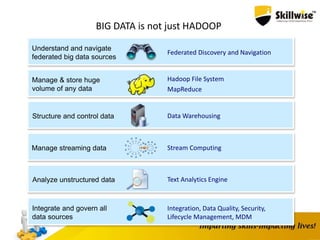
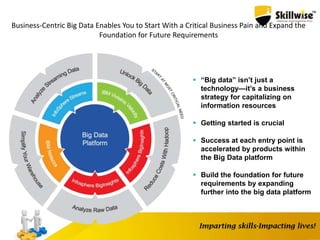

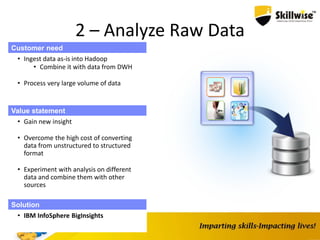
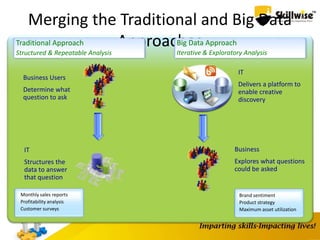
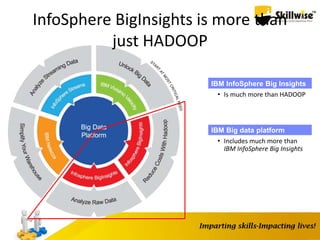



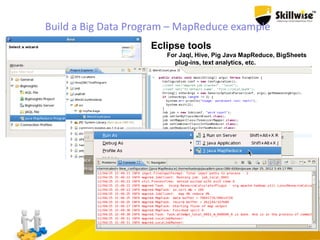
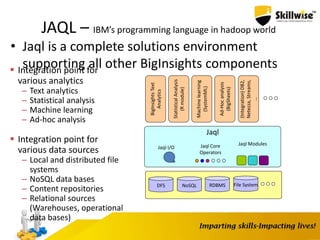
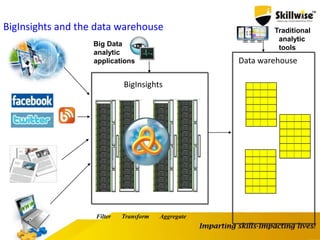














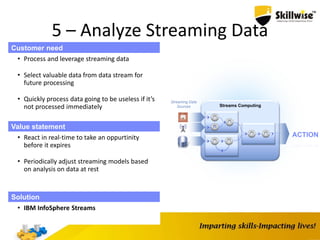

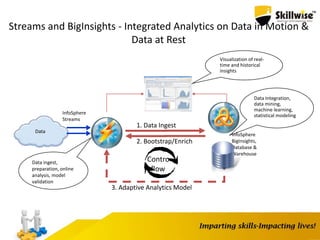
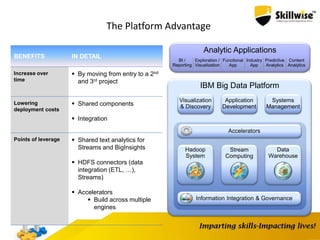


IBM's Big Data platform provides tools for managing and analyzing large volumes of data from various sources. It allows users to cost effectively store and process structured, unstructured, and streaming data. The platform includes products like Hadoop for storage, MapReduce for processing large datasets, and InfoSphere Streams for analyzing real-time streaming data. Business users can start with critical needs and expand their use of big data over time by leveraging different products within the IBM Big Data platform.





























































































