





















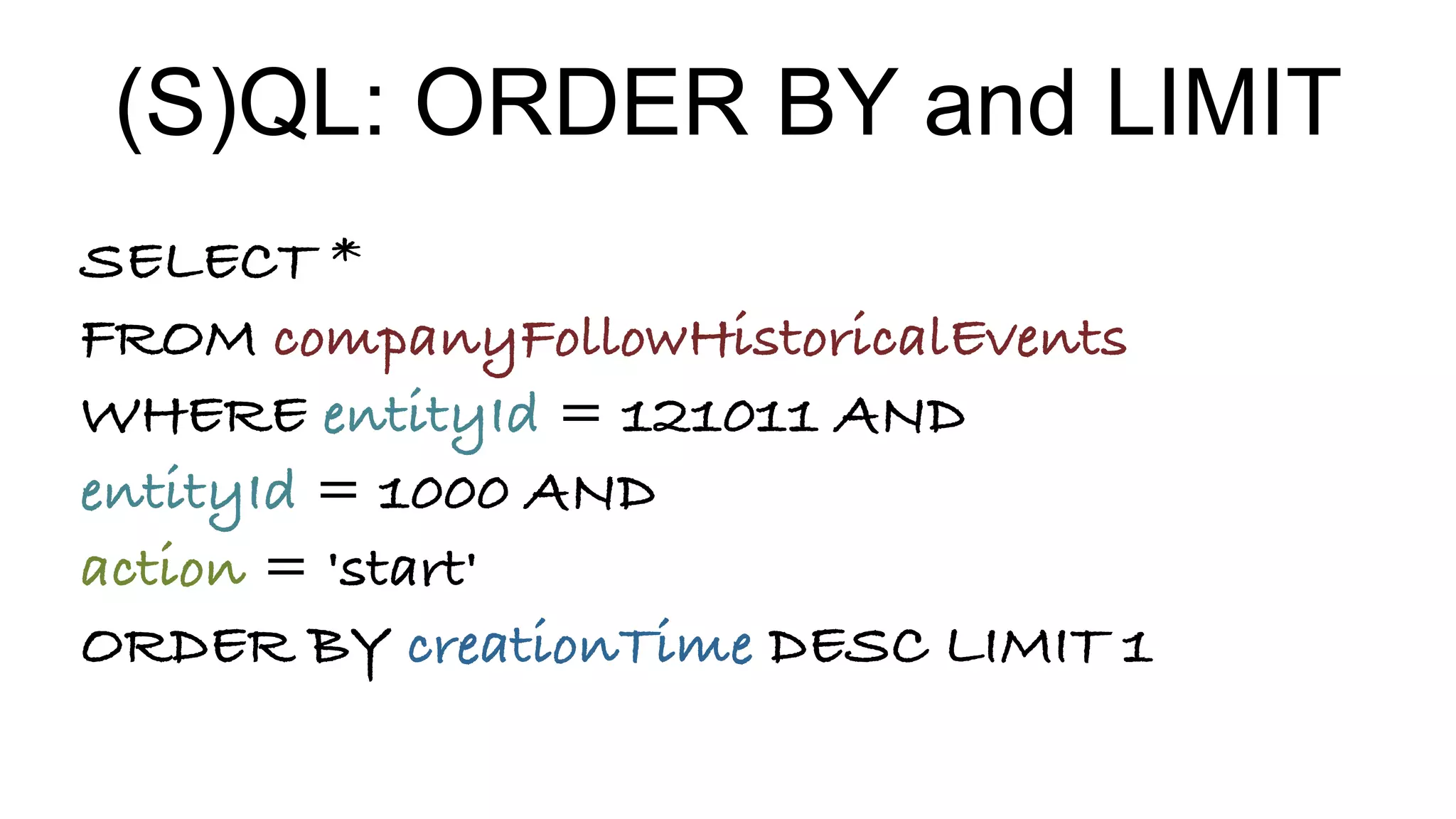










This document discusses technologies for data ingestion, transformation, and analytics. It introduces Gobblin for scalable data ingestion from diverse sources, Cubert for converting data formats, WhereHows for data lineage tracking, and Pinot for real-time analytics. Gobblin provides a framework for extracting, converting, validating data in parallel tasks. Cubert allows converting data between formats using a domain-specific language. WhereHows tracks lineage metadata to answer questions about where data came from and how it flows. Pinot is a real-time distributed OLAP store for interactive queries on fresh data using a SQL-like interface.
Introduction to the Data Driven Network concept presented by Kapil Surlaker and Shirshanka Das at Hadoop Summit 2015.
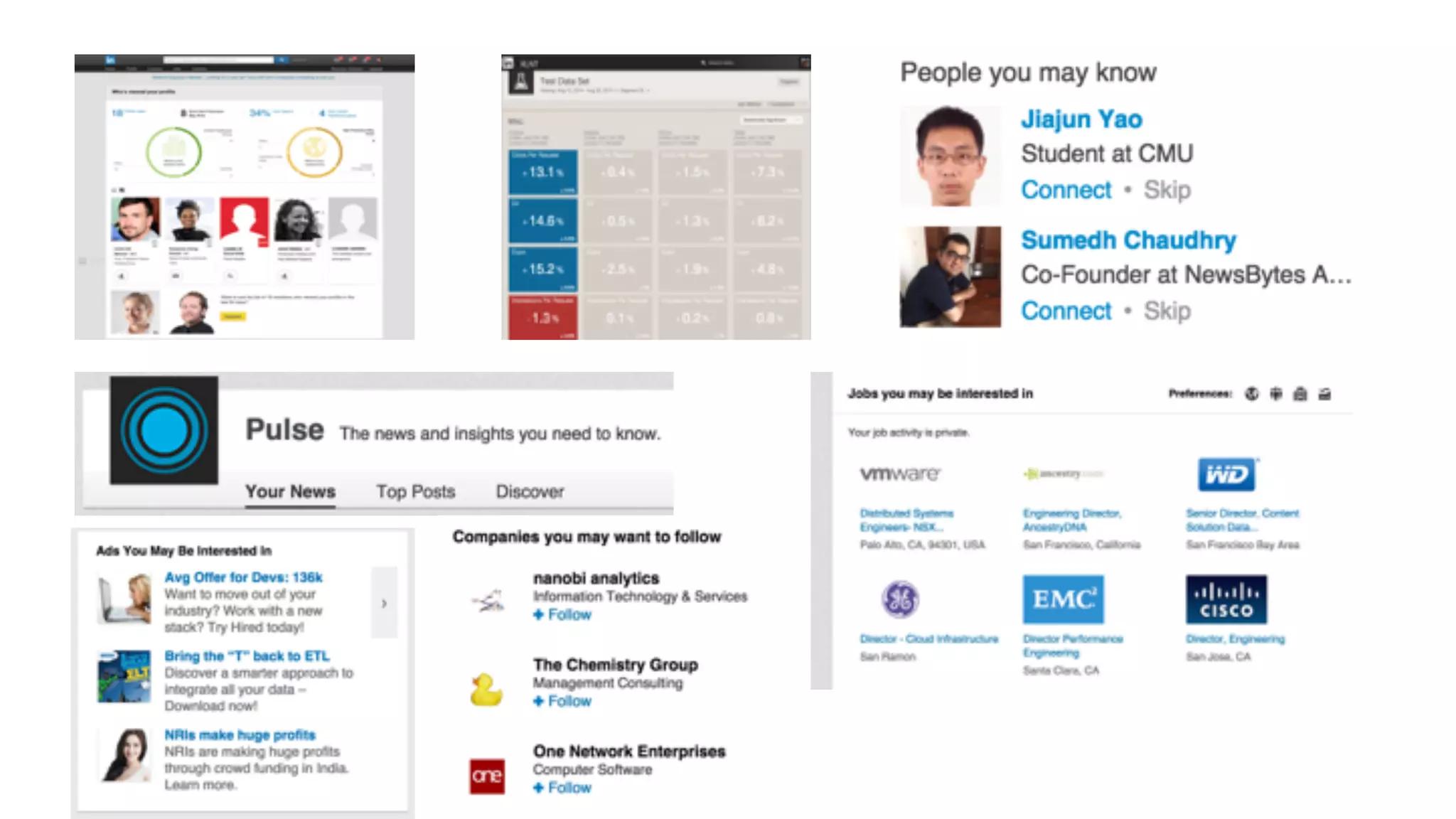
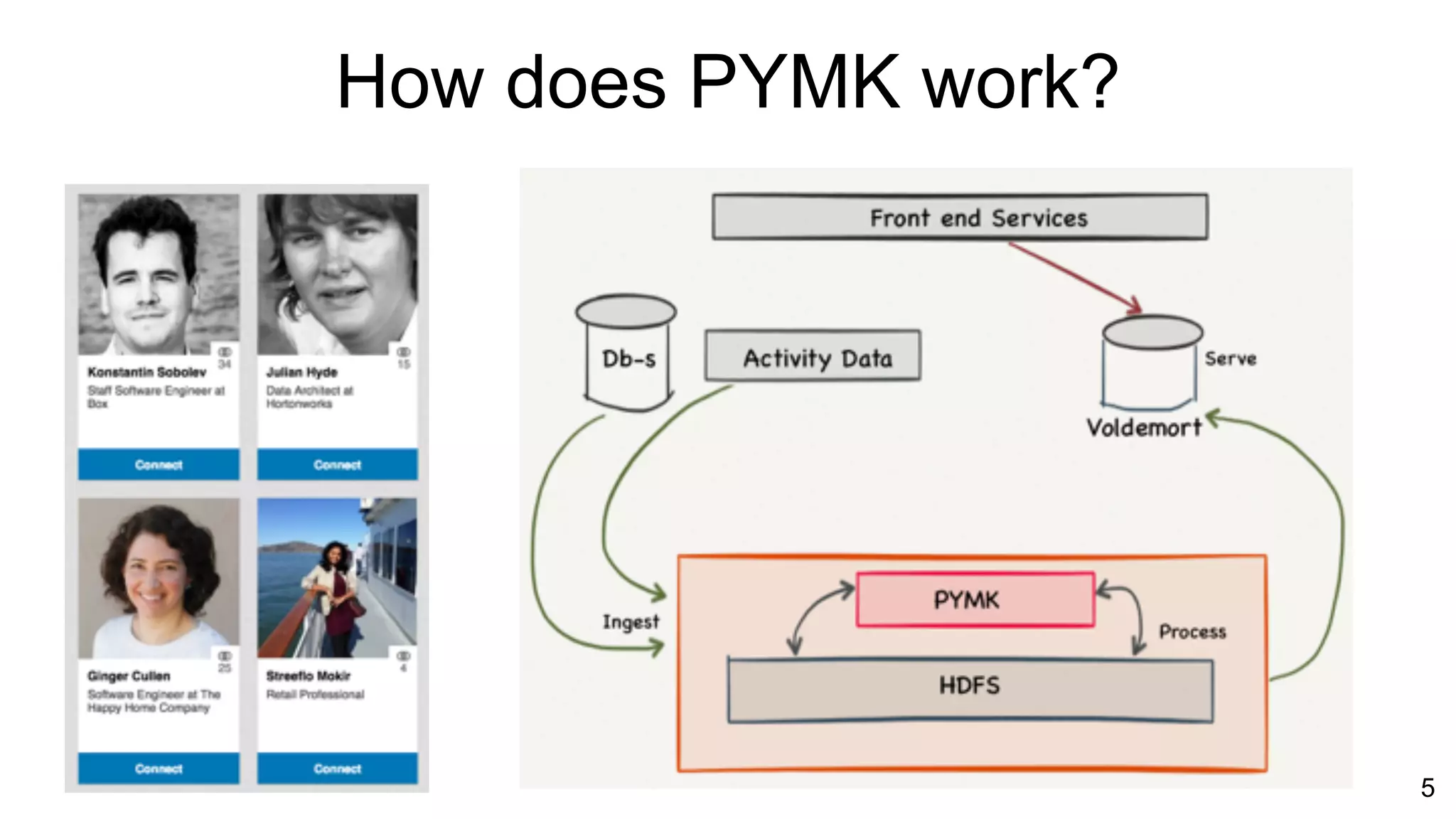
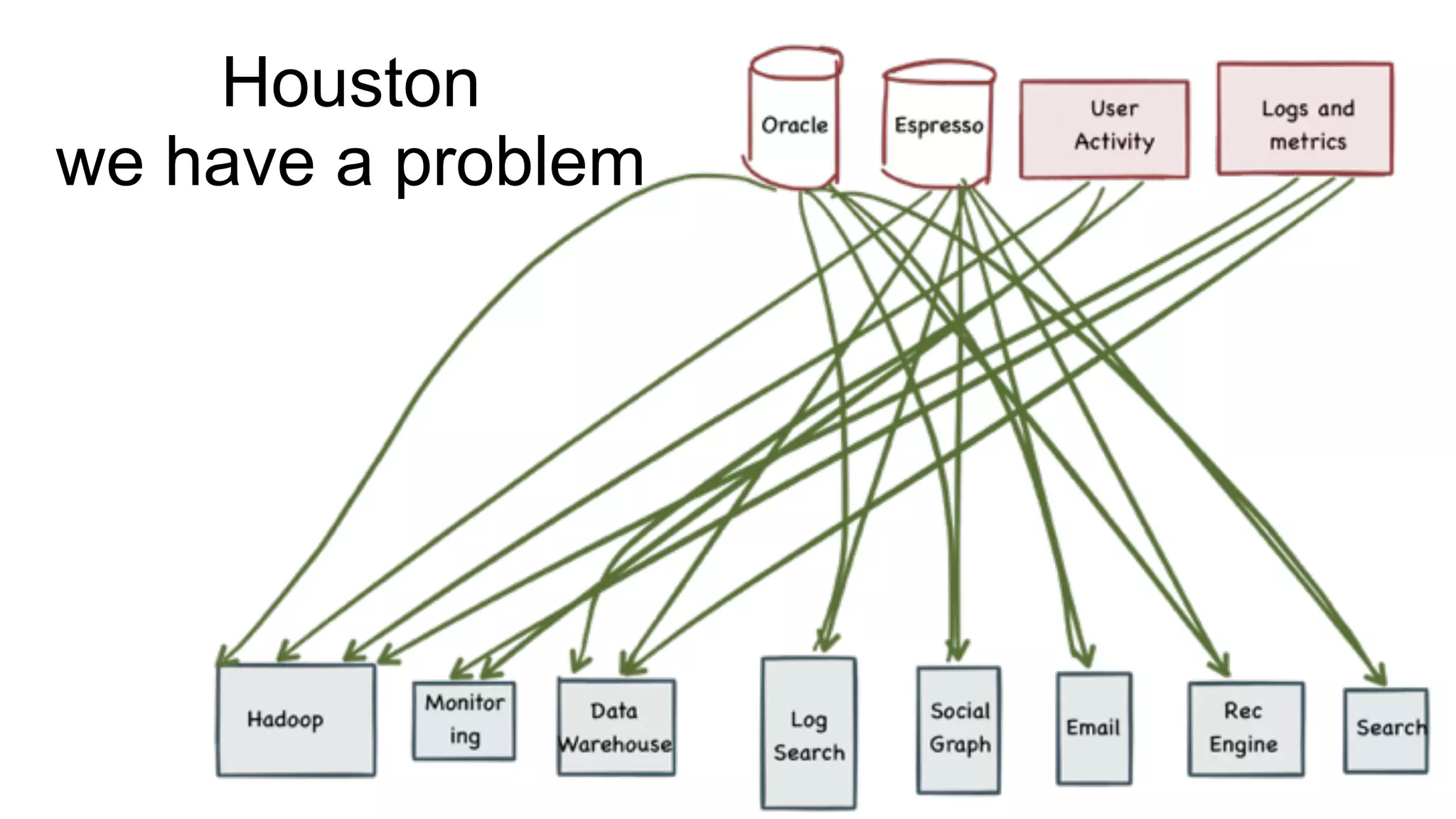
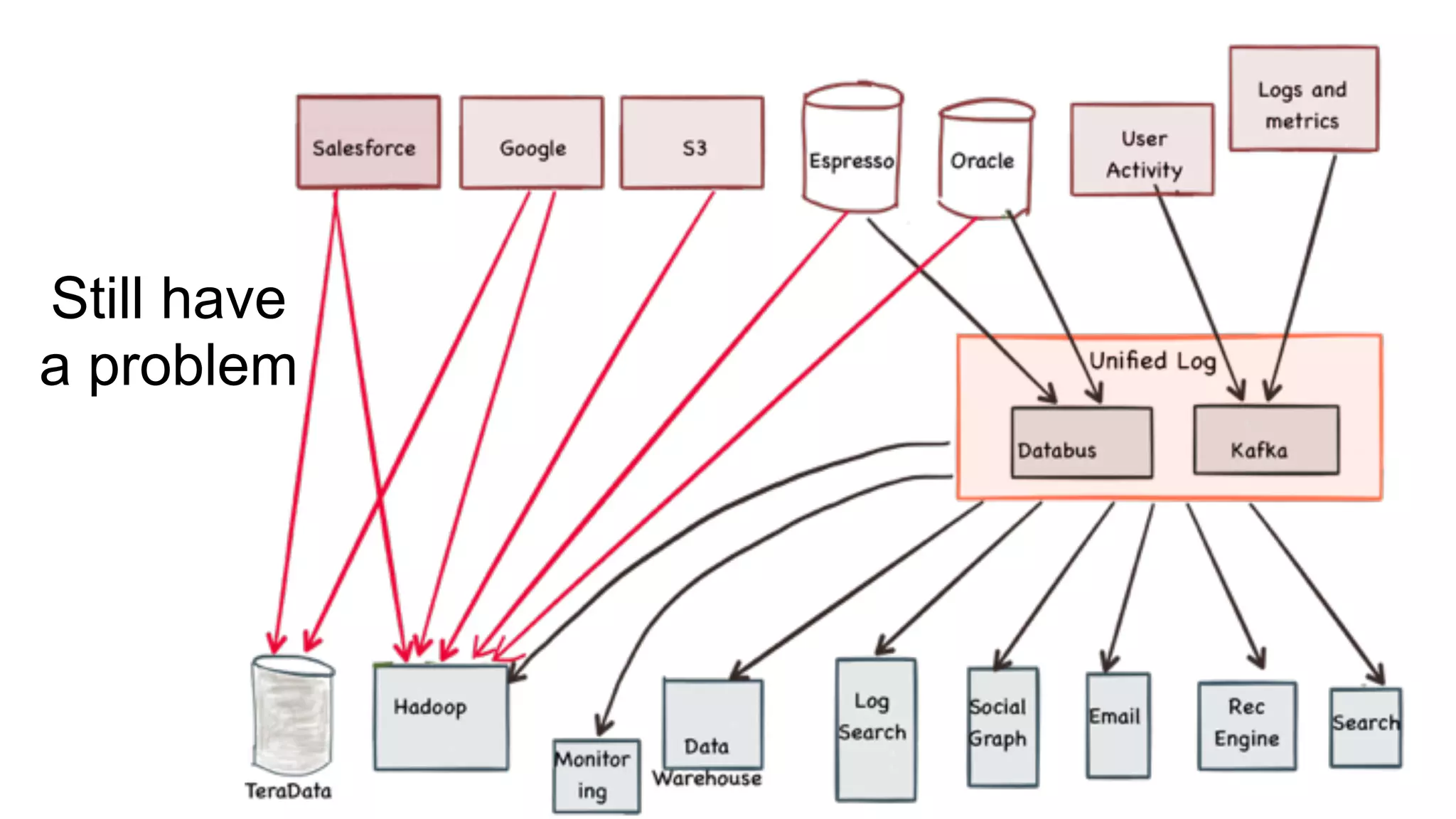
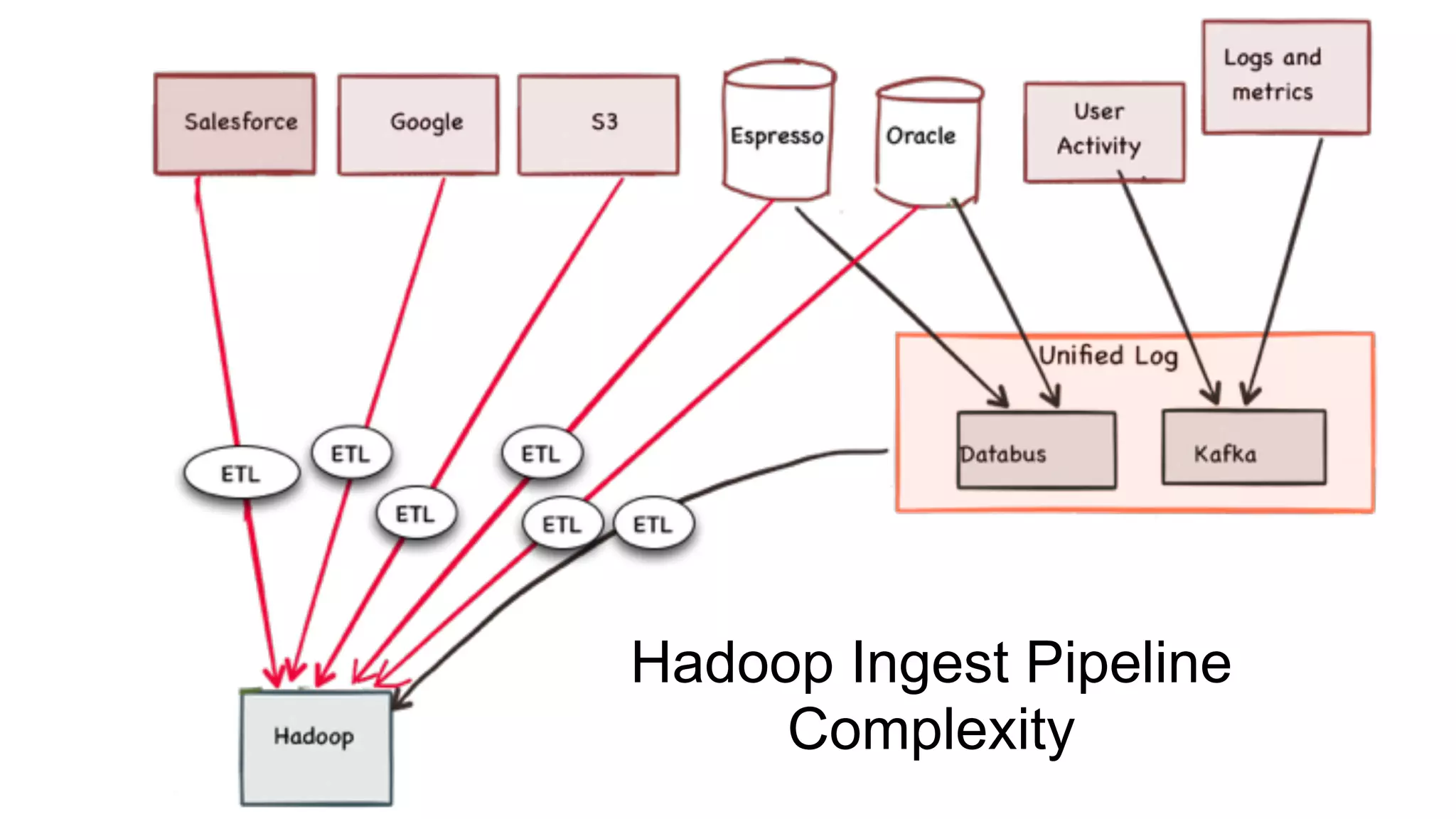
Overview of the PYMK (People You May Know) process and the complexities of the Hadoop Ingest Pipeline.
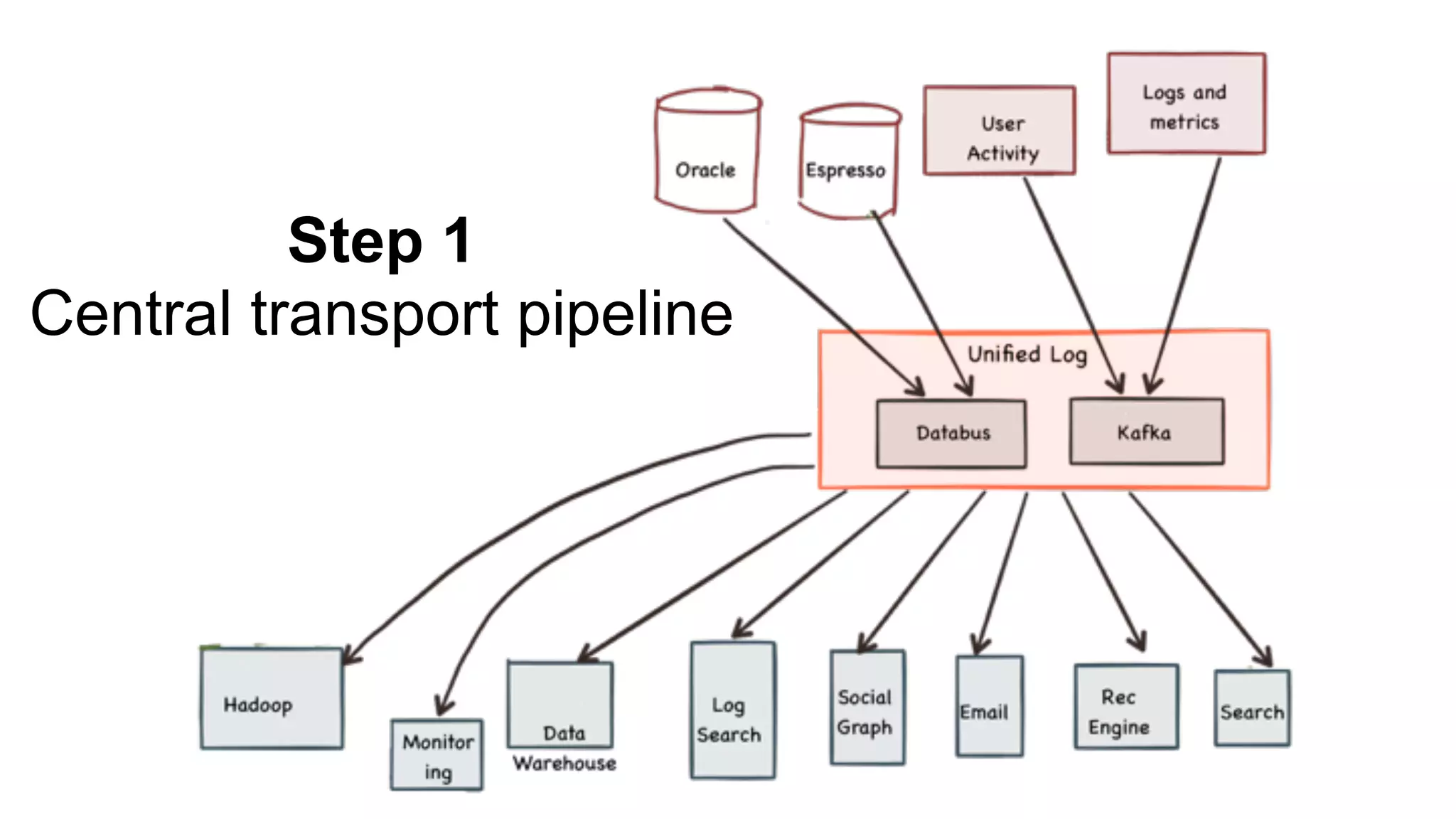
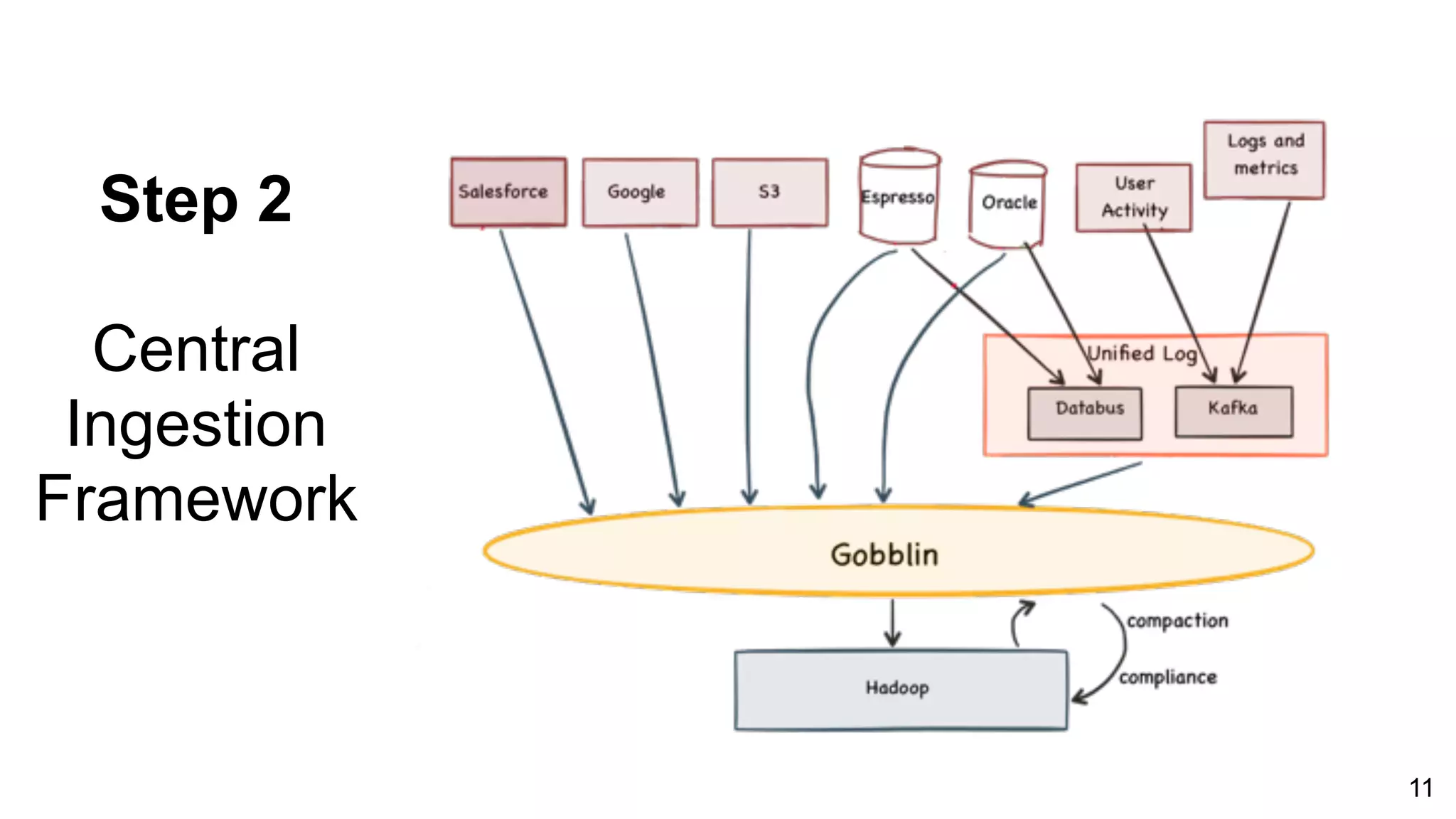
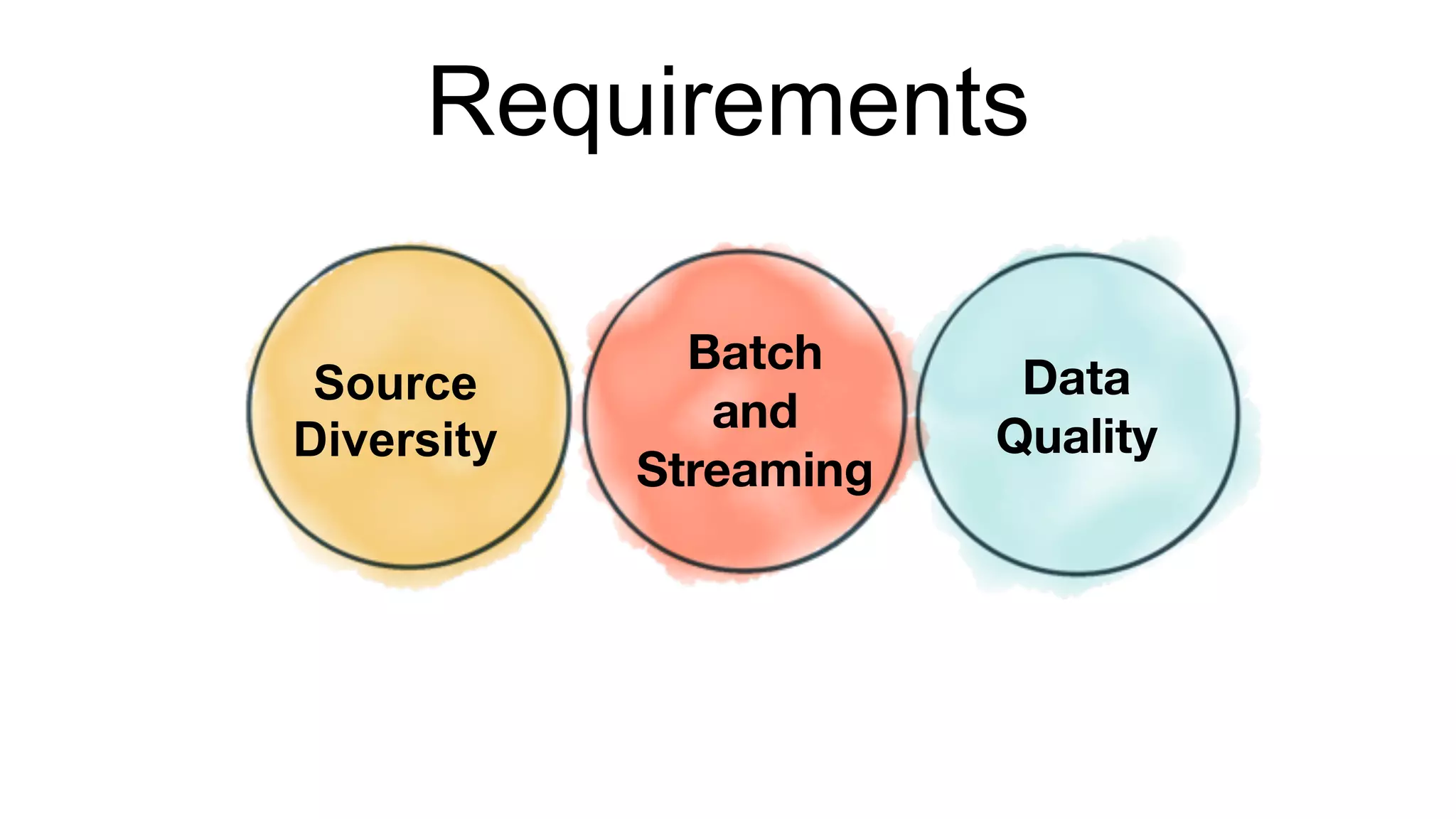
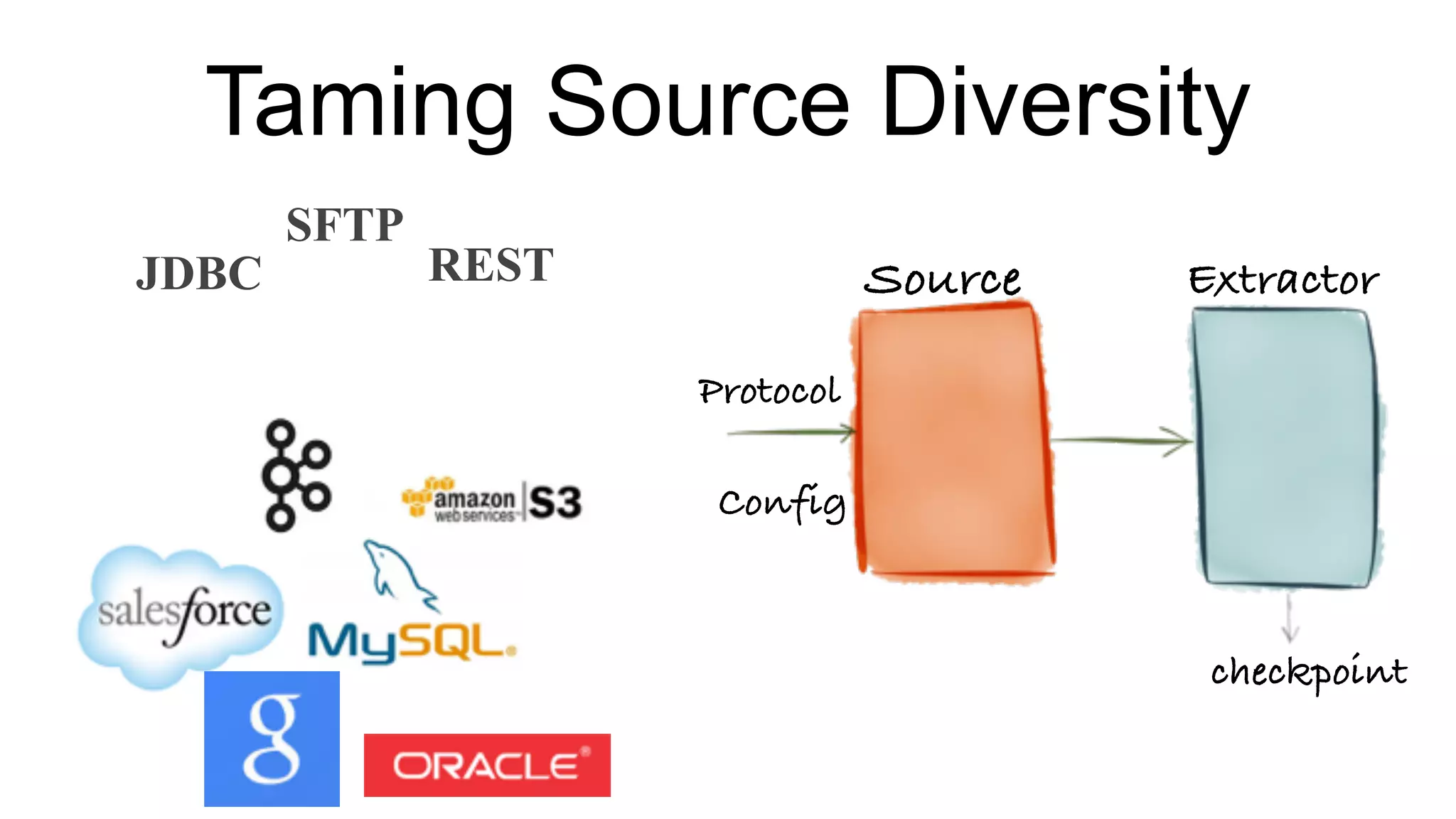
Step-by-step process of the Central Ingestion Framework focusing on source diversity and data quality.
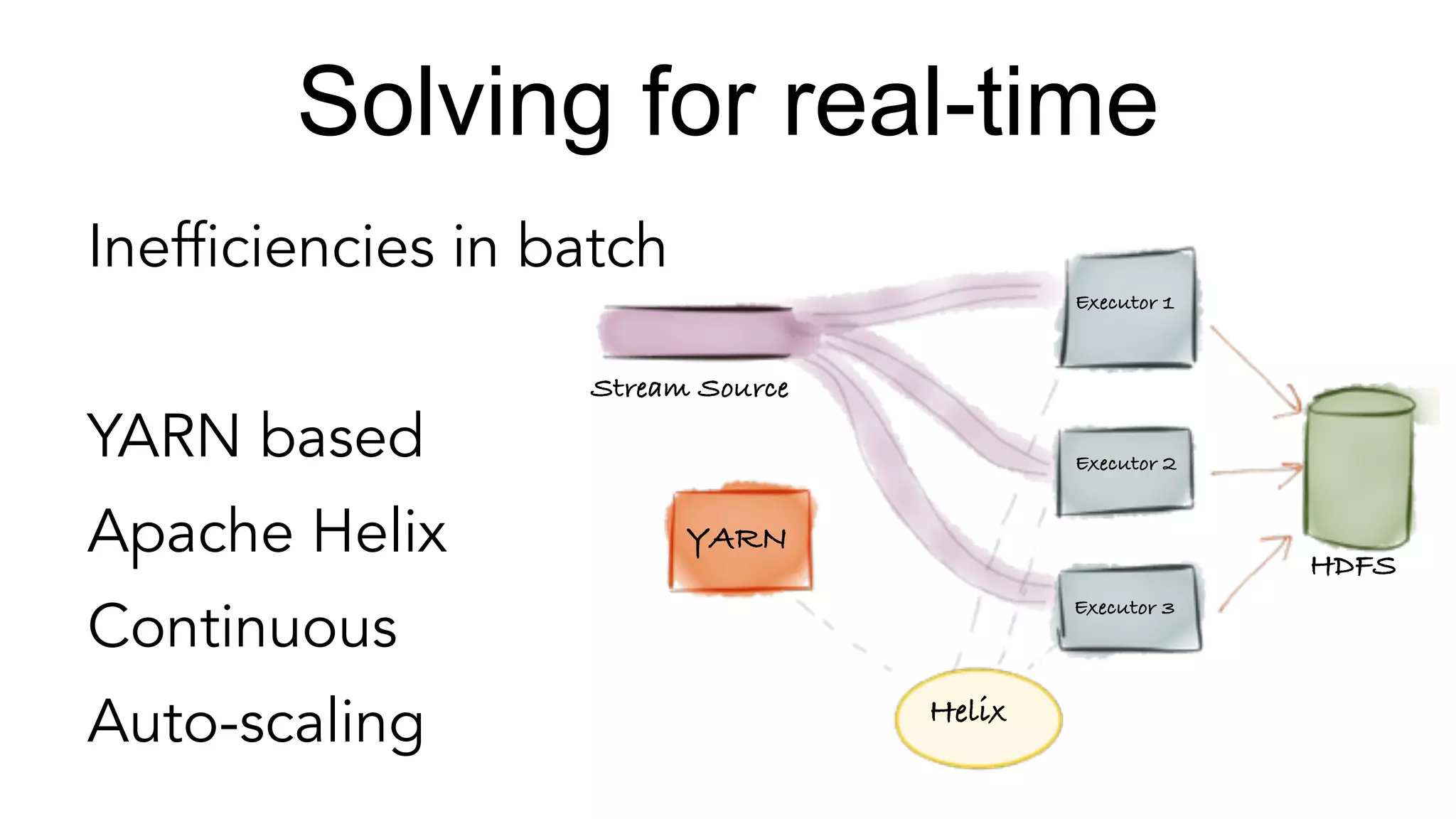
Addressing inefficiencies in real-time data processing with YARN and Apache Helix, emphasizing data quality.
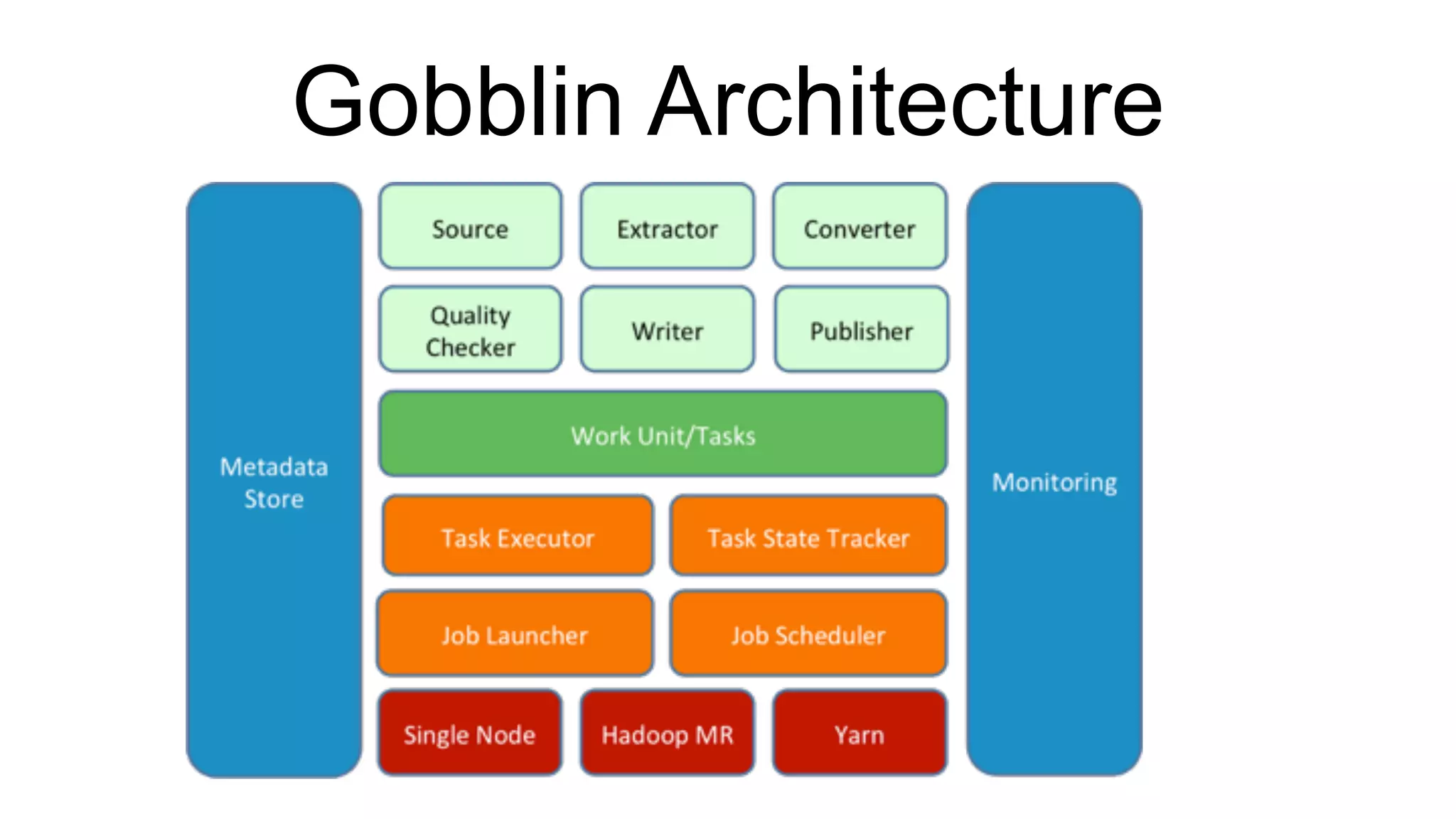
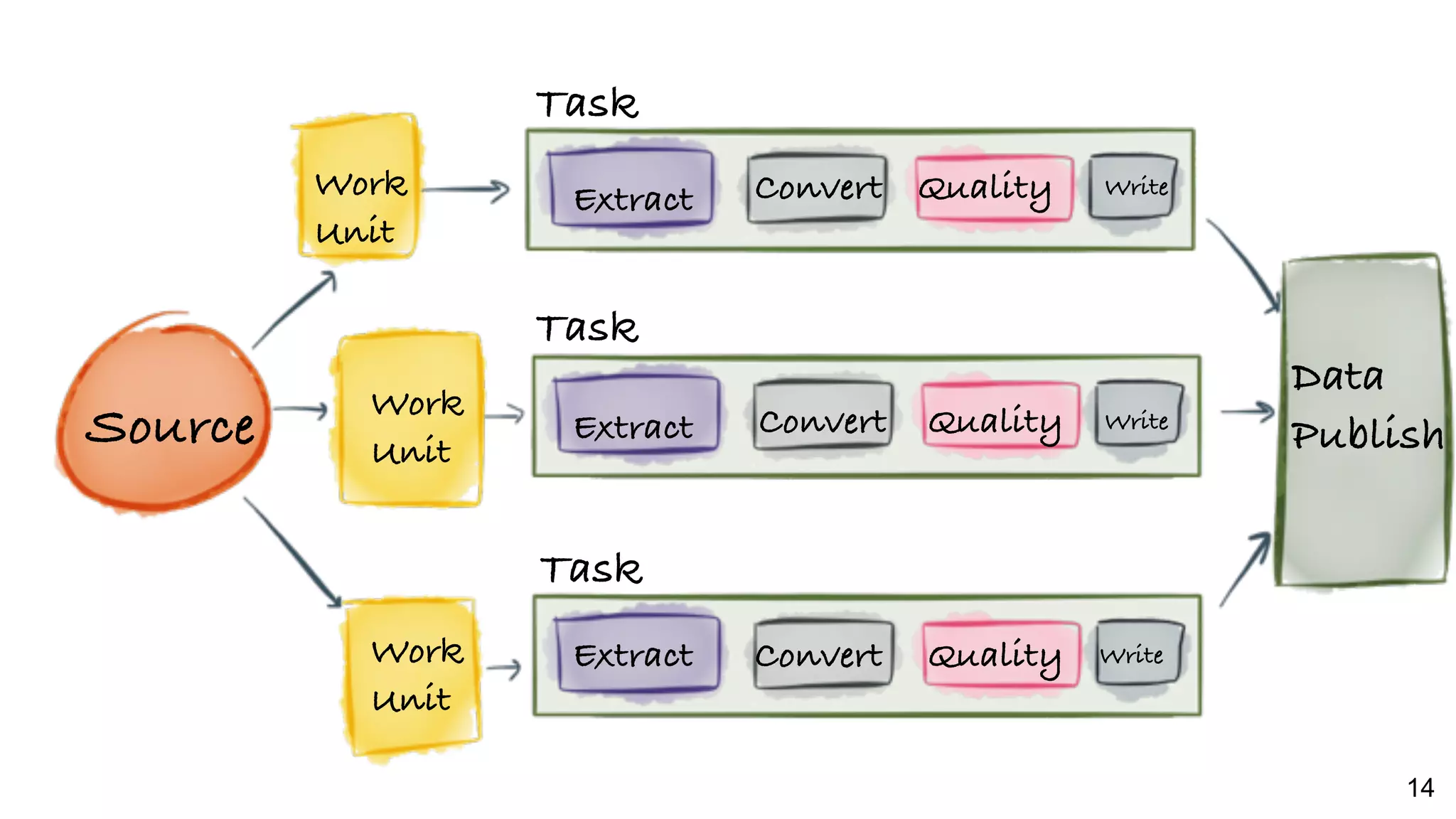
Current Gobblin architecture used at LinkedIn for data ingestion that manages tens of TBs daily from multiple sources.
Transformation strategies in data processing, introducing Cubert for enhanced efficiency.
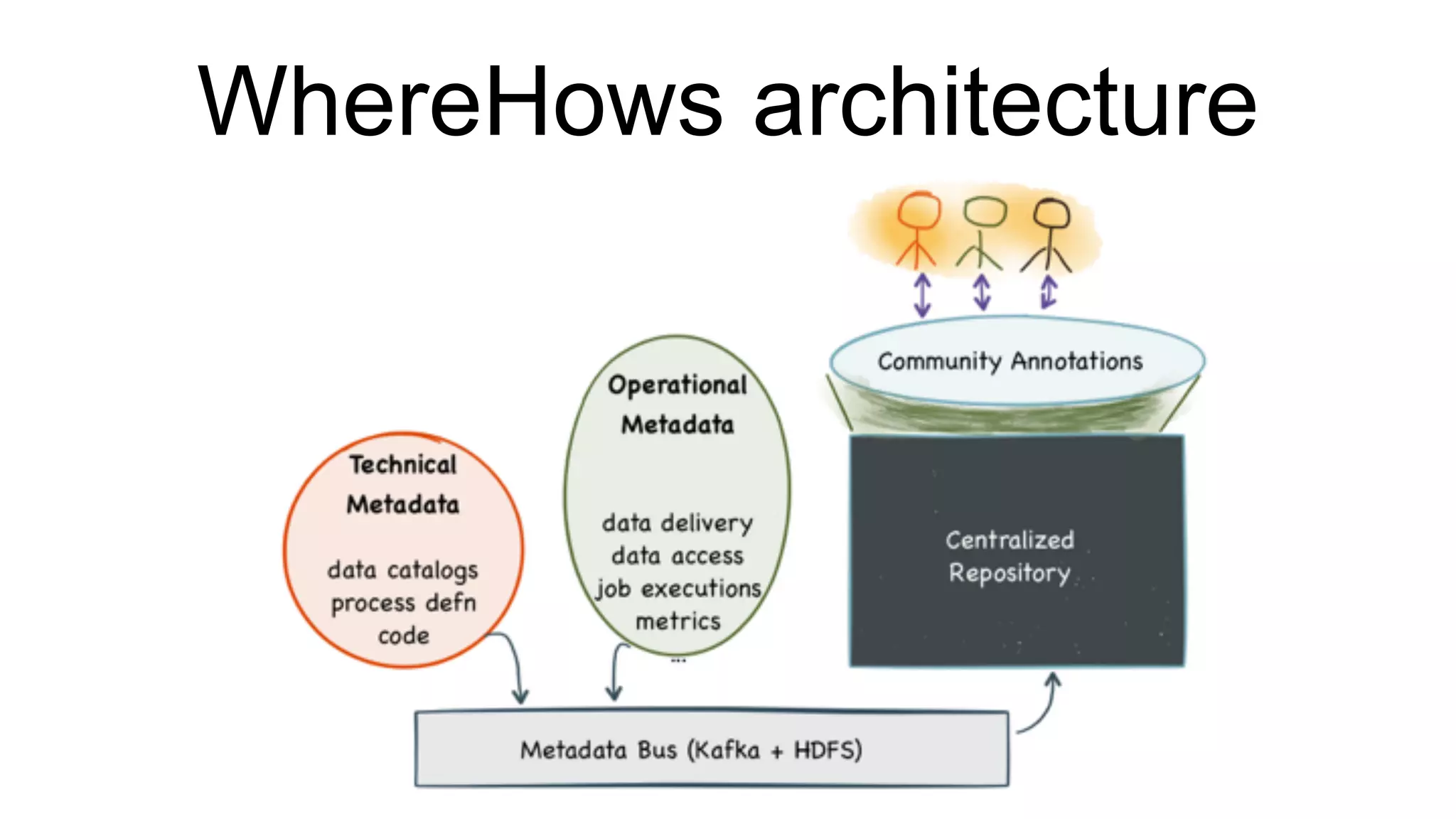
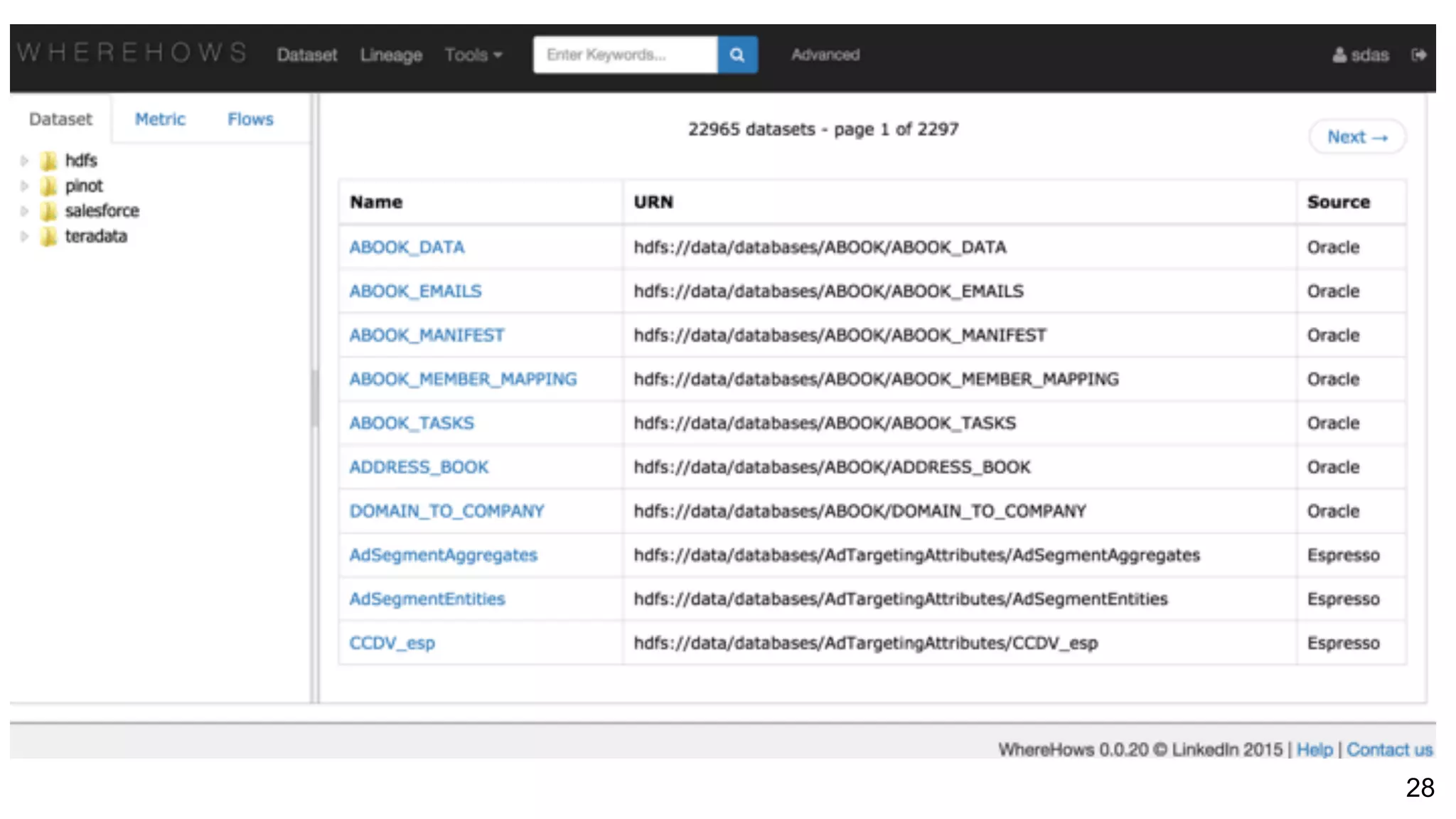
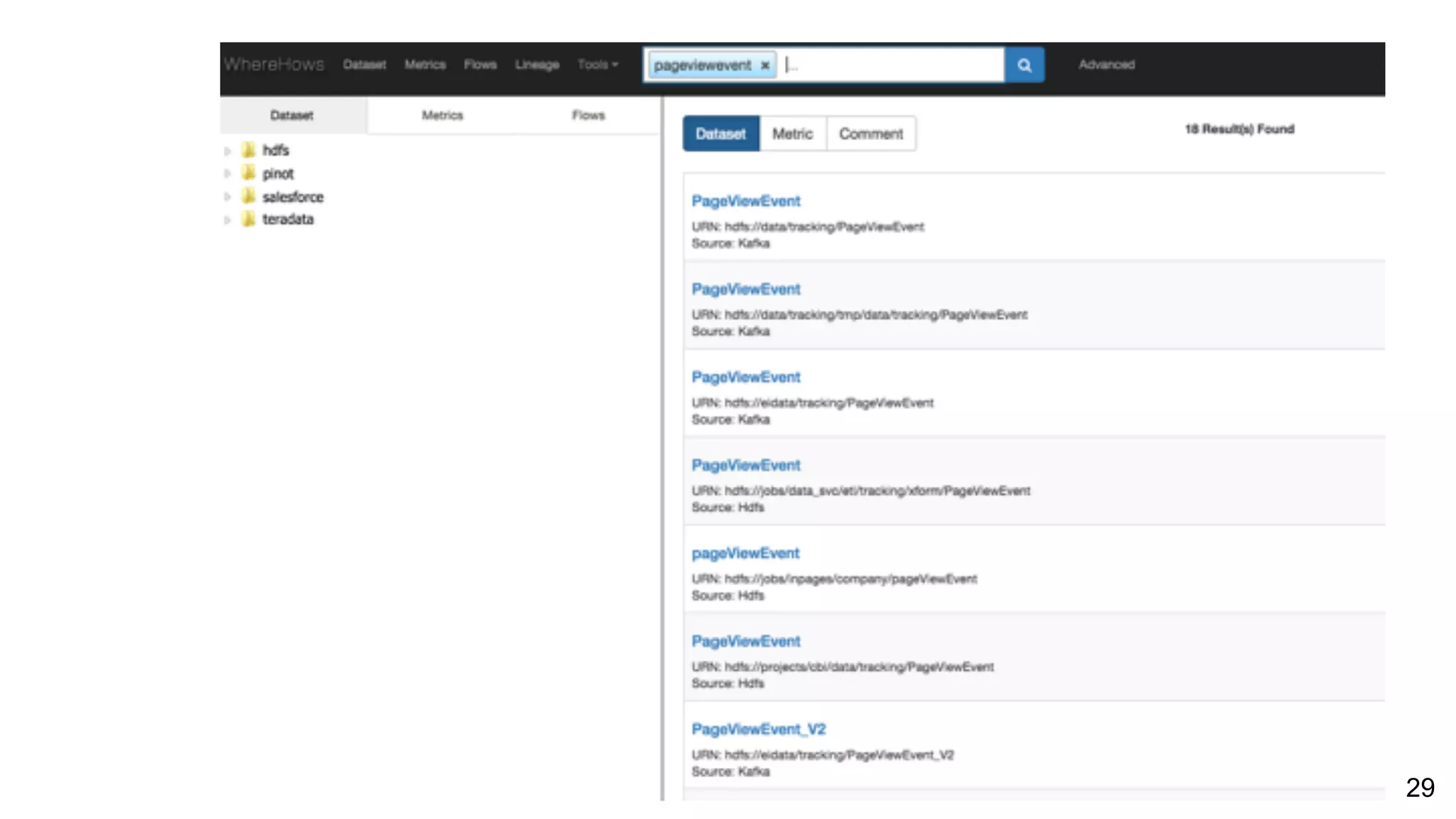
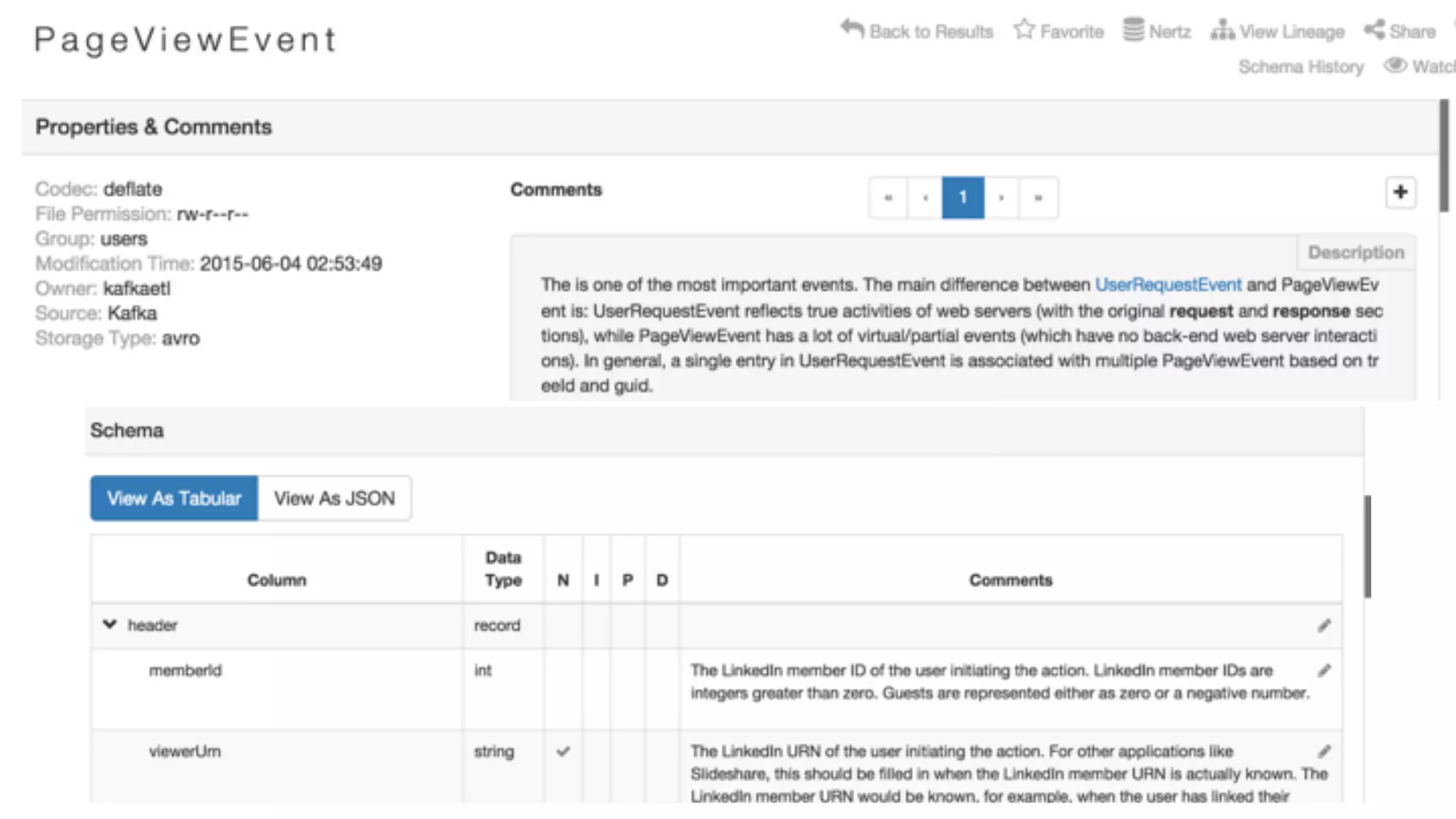
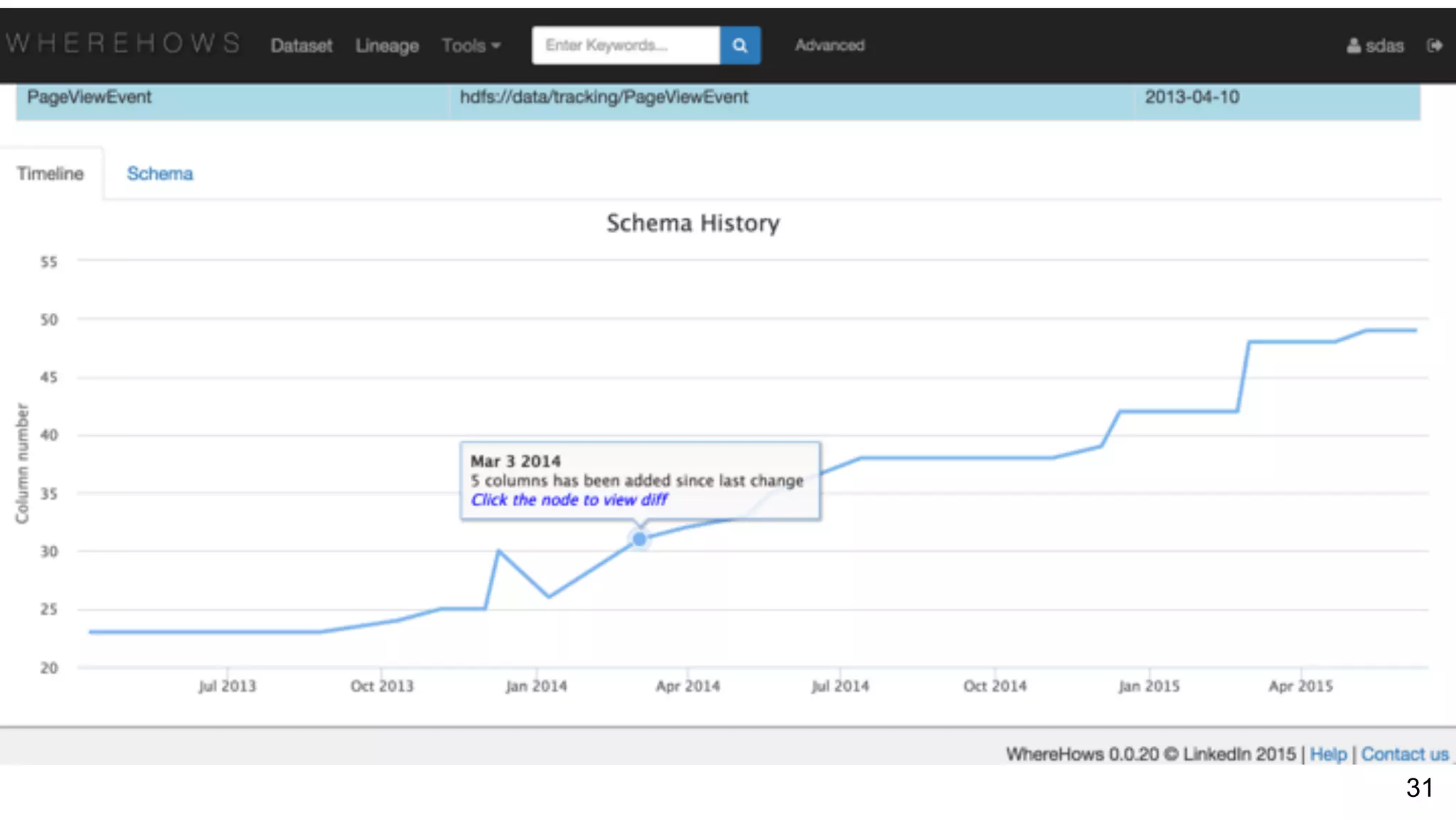
Asking questions about data flow and management, addressing data lineage and using WhereHows for tracking. Architecture of WhereHows and its future roadmap, including integration with streaming ecosystems like Kafka.
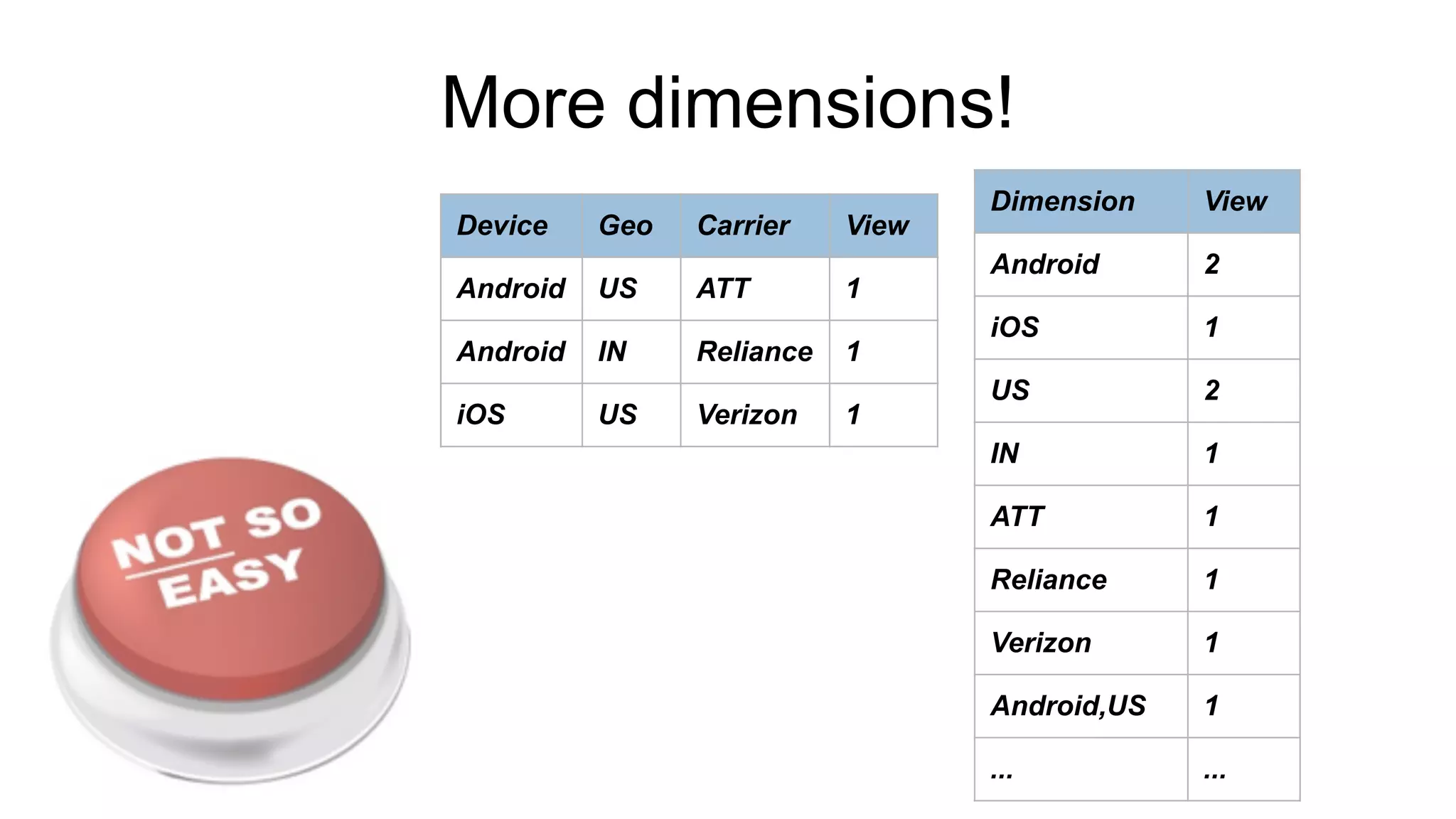
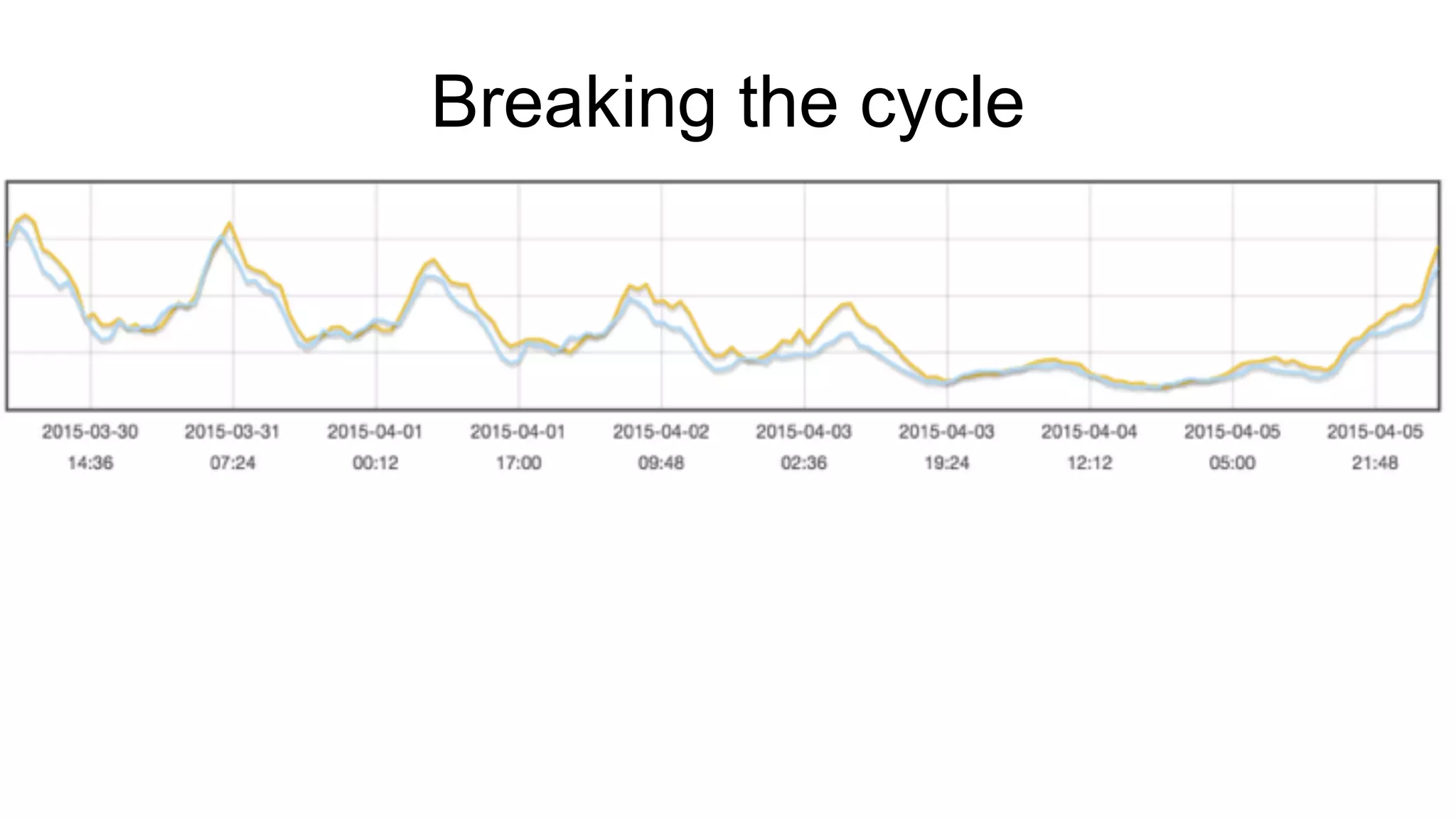
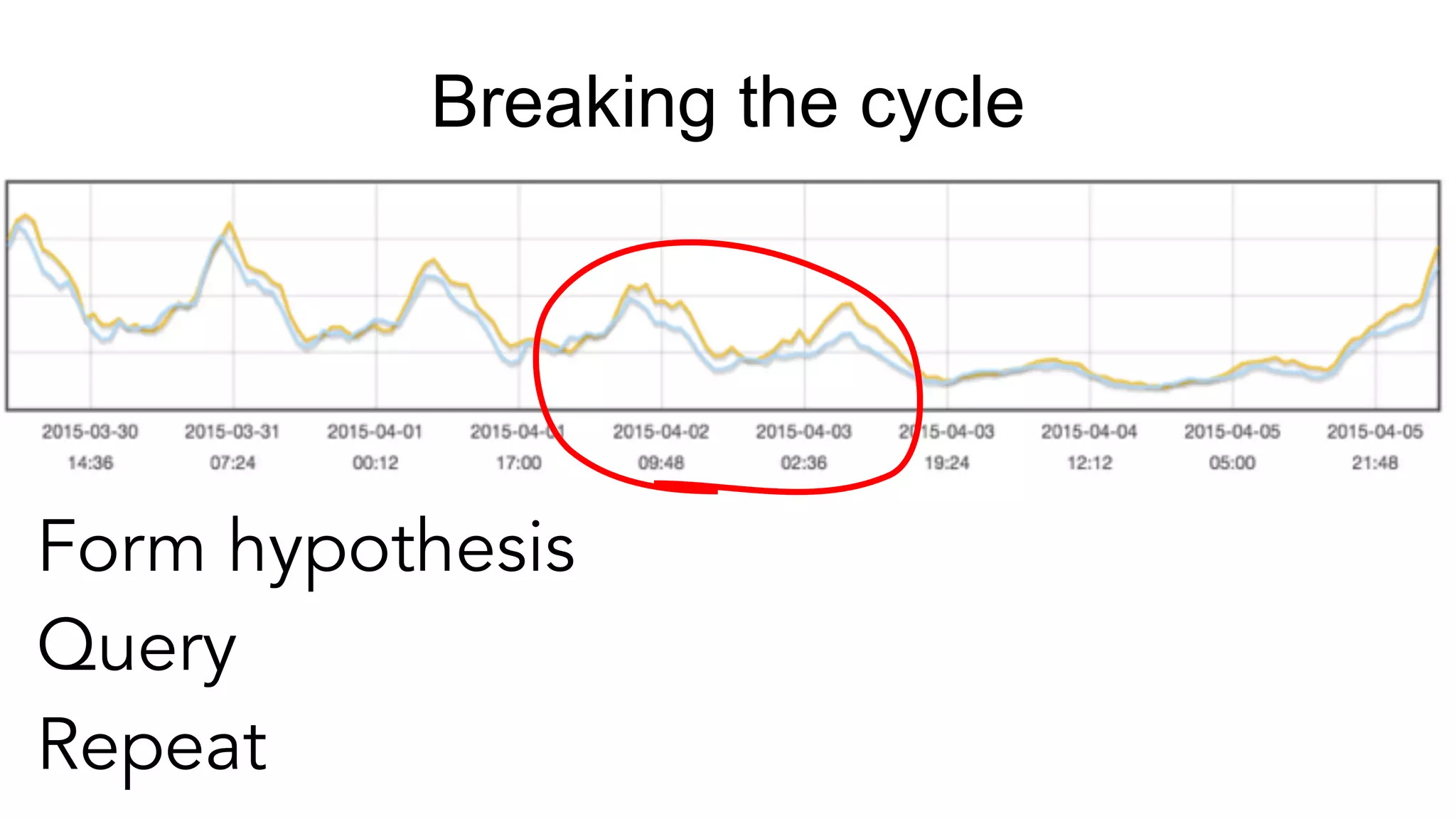
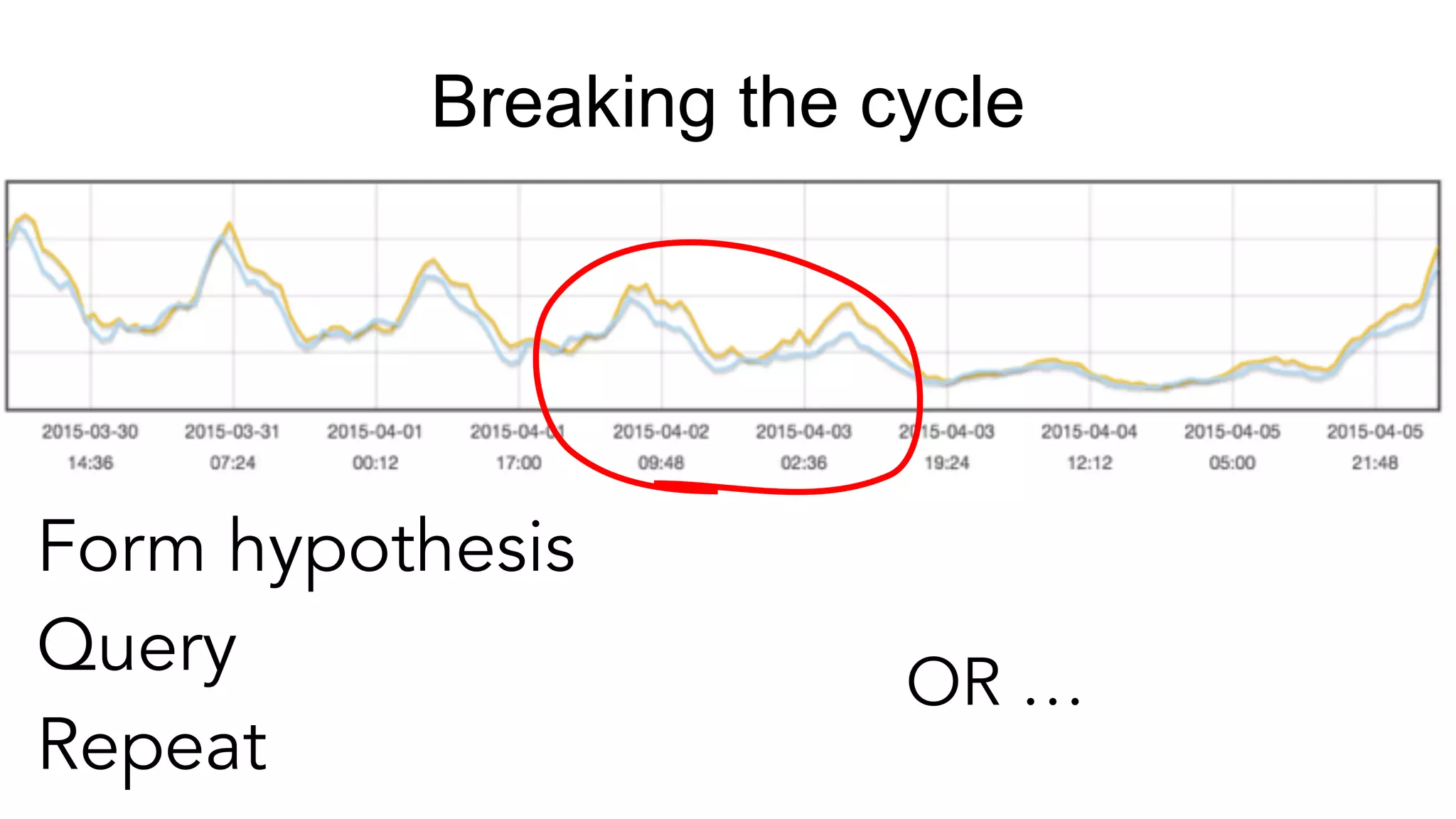
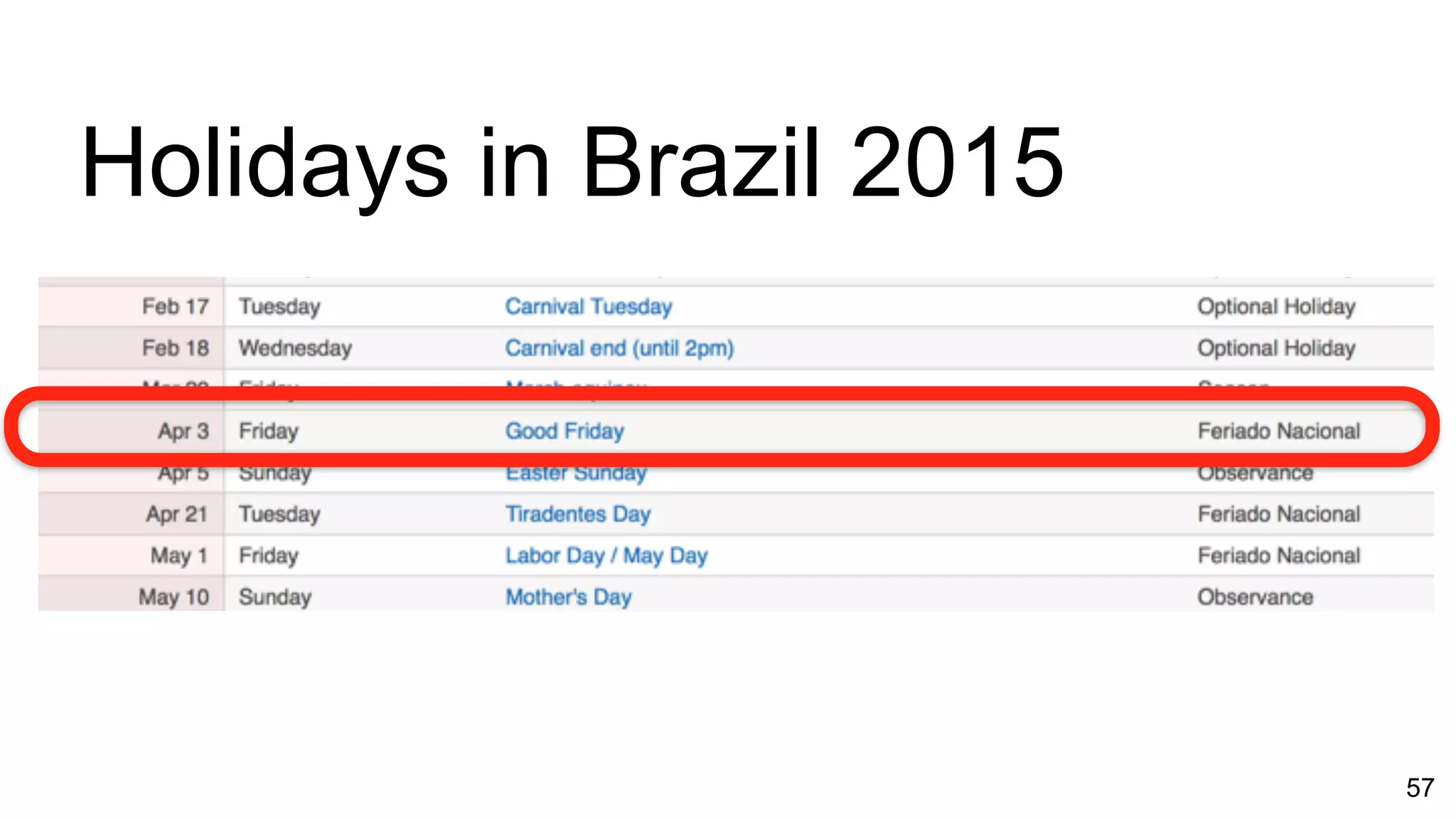
Exploring real-time and interactive metrics with focus on device geographical views and preprocessing.
Identifying challenges in data management such as scalability and latency; introduction of Pinot.
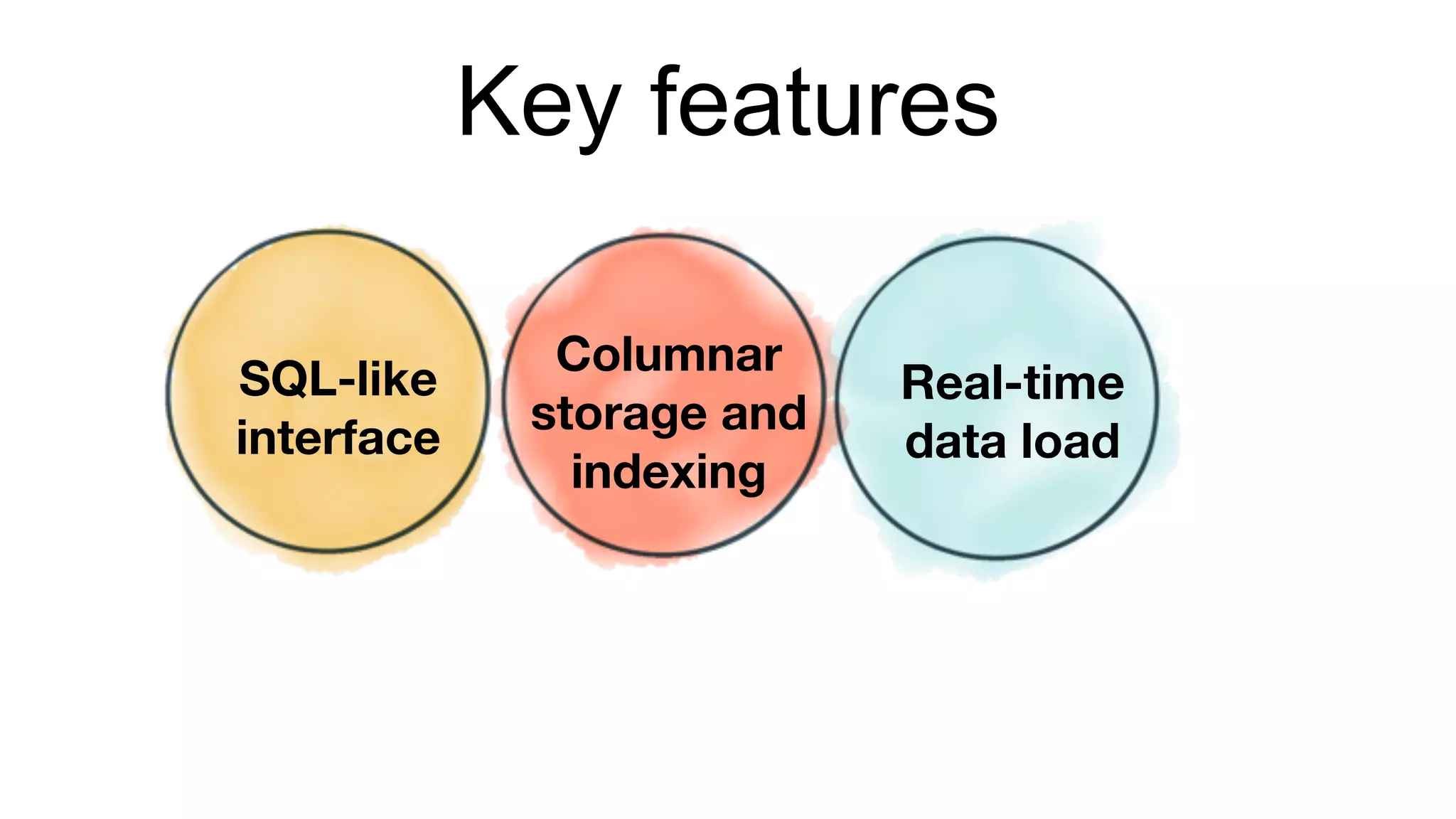
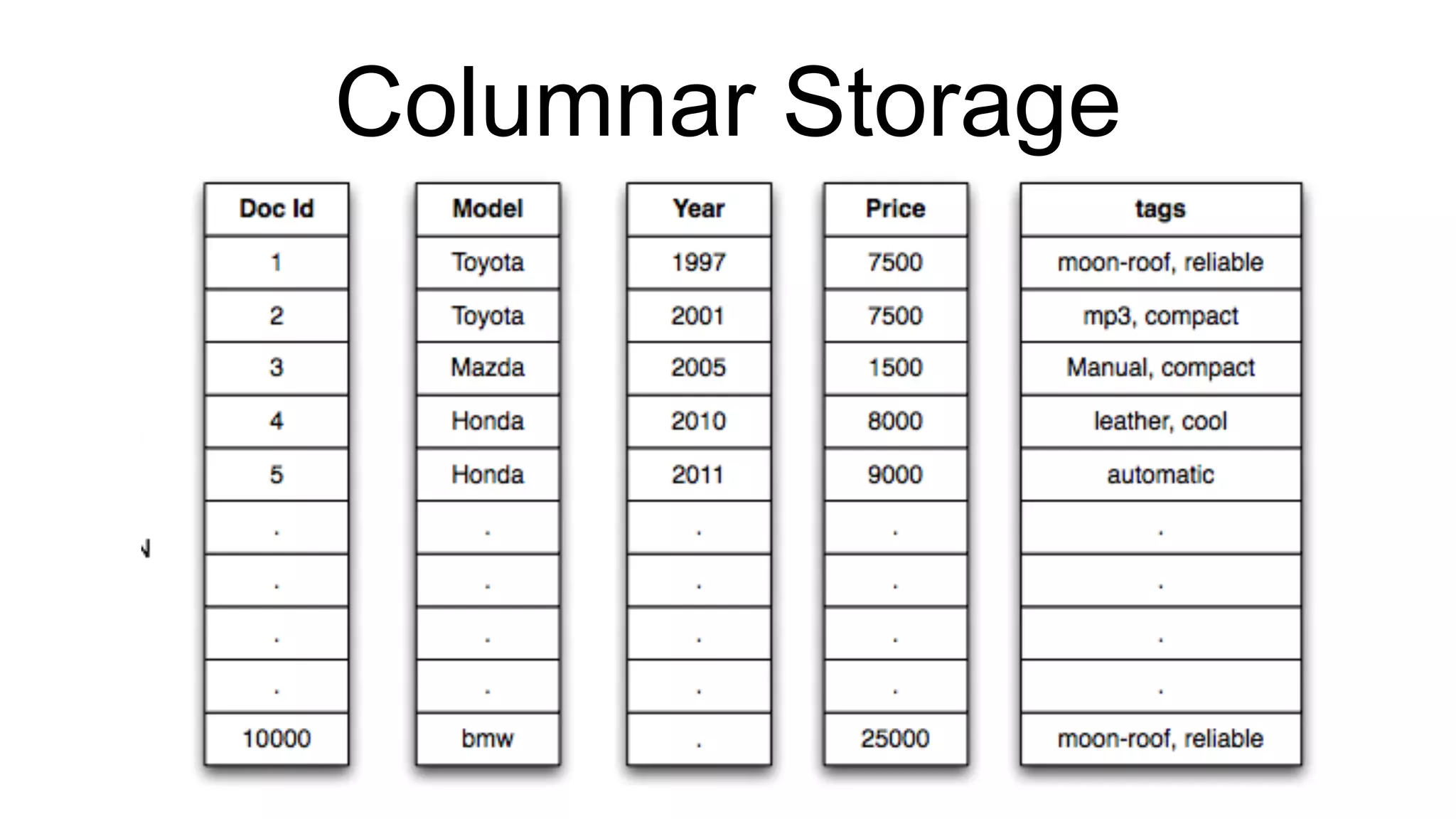
Details on querying capabilities in Pinot, showcasing SQL-like interfaces and data handling methods.
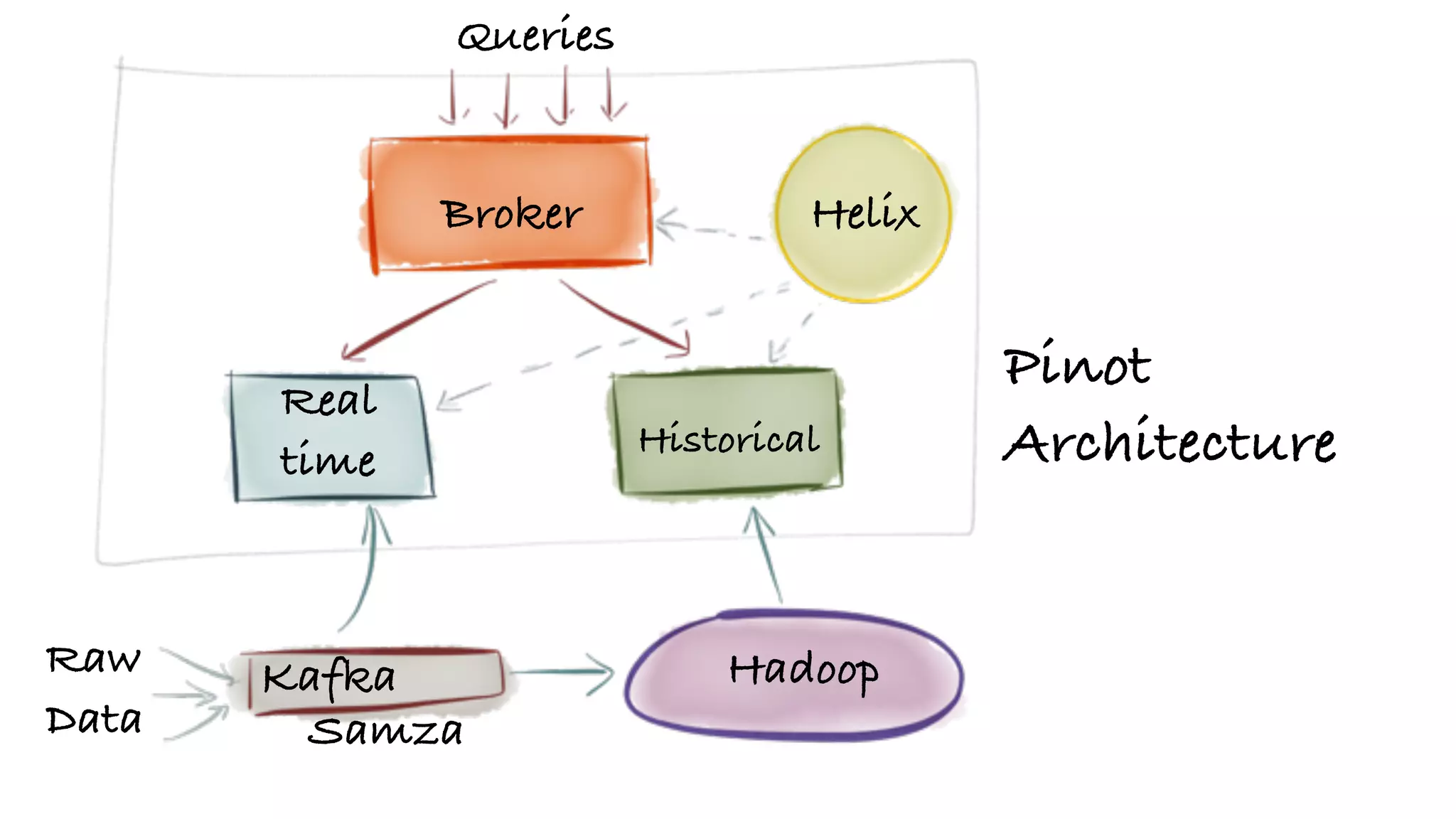
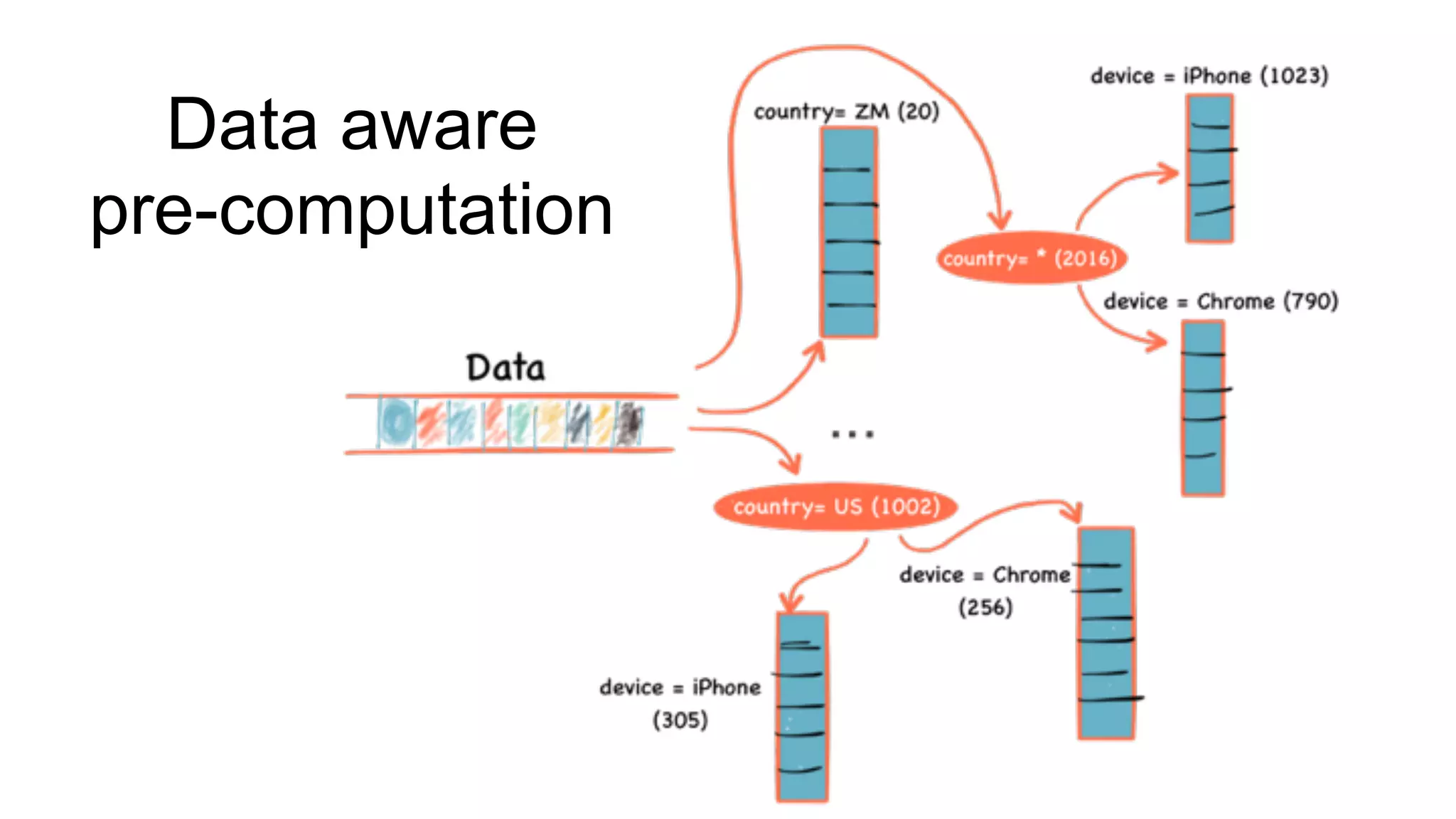
Explanation of the Pinot architecture merging real-time data with historical queries and pre-computation strategies.
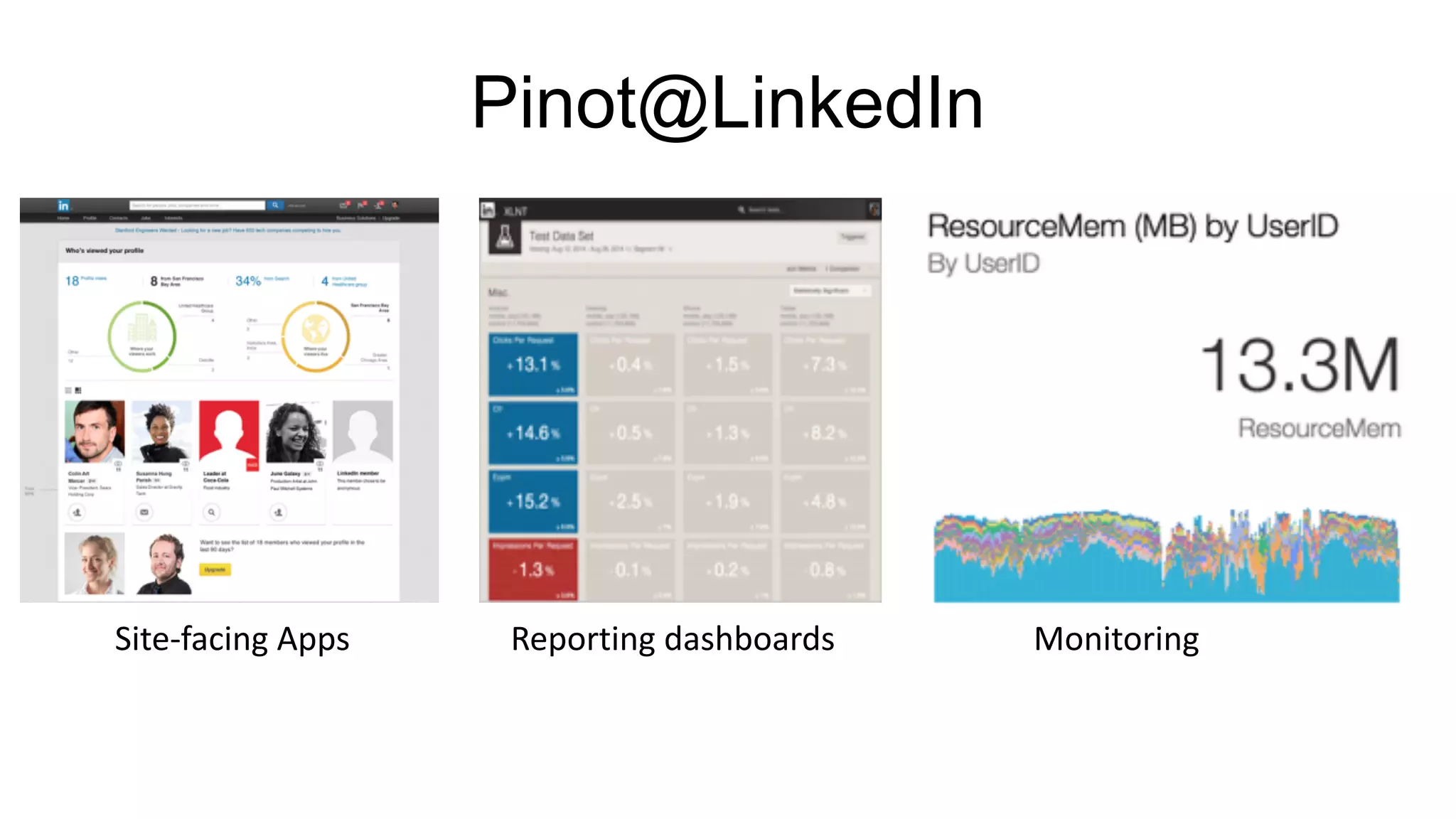
Use cases for Pinot at LinkedIn, future developments, and open-source contributions by Kapil Surlaker.






















































































