Download as PDF, PPTX




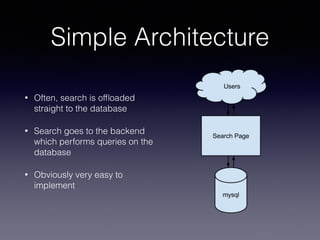
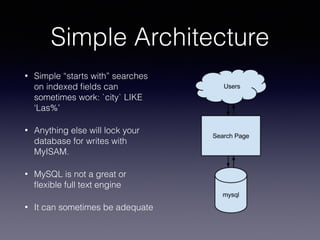
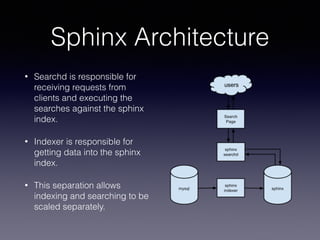
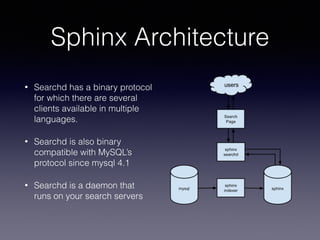
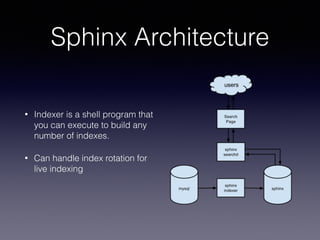
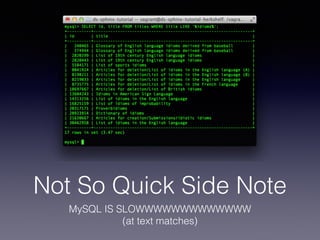
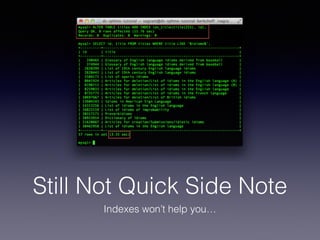
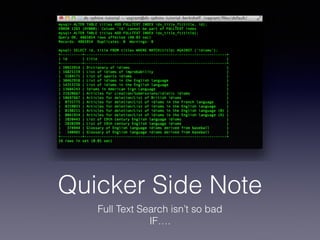






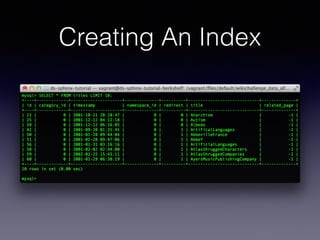

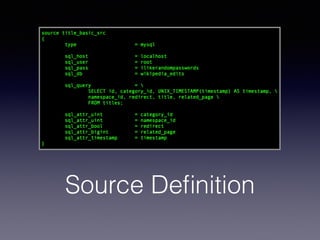


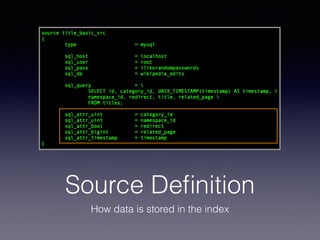





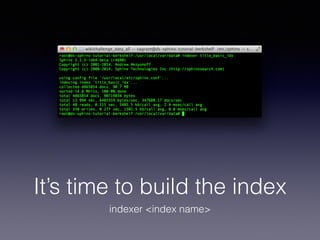

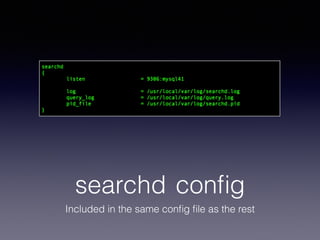
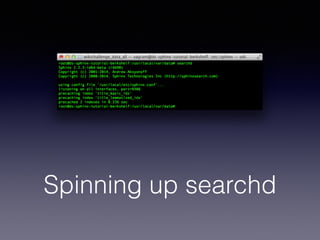















The document provides an overview of Sphinx, a full-text search engine designed for integration with SQL databases and capable of handling various data sources. It discusses Sphinx architecture, indexing processes, and querying methods, emphasizing its advantages over MySQL for search functionalities. Additionally, it outlines practical applications, configuration details, and features like auto-suggest and real-time indexing.



































































