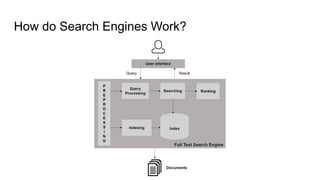
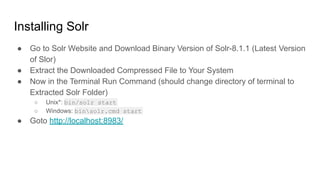
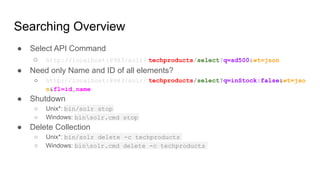
The document is a comprehensive guide on Apache Solr, covering its features, installation, and basic concepts such as inverted indexing and schema definition. It includes details on adding documents, performing searches, and advanced query techniques, as well as custom field types and analyzers. The document also highlights the schemaless approach for collection creation and document management.


![Introduction [Recall]
● Search Platform
● Open-Source
● Search Applications
● Built on top of Lucene
● Why…
○ Enterprise-ready
○ Fast
○ Highly Scalable
● Search + NoSQL
○ Non Relational Data Storage](https://image.slidesharecdn.com/solrworkshop-200224190336/85/Solr-workshop-2-320.jpg)
![Features of Apache Solr [Recall]
● Restful APIs
○ No Java programming skills Required
● Full text search
○ tokens, phrases, spell check, wildcard, and auto-complete
● Enterprise ready
● Flexible and Extensible
● NoSQL database
● Admin Interface
● Highly Scalable
● Text-Centric and Sorted by Relevance](https://image.slidesharecdn.com/solrworkshop-200224190336/85/Solr-workshop-3-320.jpg)



![Basic Solr Concepts [Contd..]
● Field Types
○ float
○ long
○ double
○ date
○ Text
● Define new field types!
<fieldtype name="phonetic" stored="false" indexed="true" class="solr.TextField" >
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.DoubleMetaphoneFilterFactory" inject="false"/>
</analyzer>
</fieldtype>](https://image.slidesharecdn.com/solrworkshop-200224190336/85/Solr-workshop-10-320.jpg)
![Basic Solr Concepts [Contd..]
● Defining a Field
○ name: Name of the field
○ type: Field type
○ indexed: Should this field be added to the inverted index?
○ stored: Should the original value of this field be stored?
○ multiValued: Can this field have multiple values
<field name="id" type="text" indexed="true" stored="true" multiValued="true"/>](https://image.slidesharecdn.com/solrworkshop-200224190336/85/Solr-workshop-11-320.jpg)



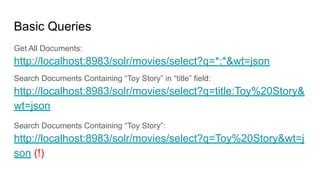






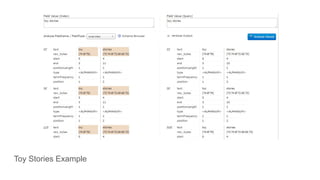
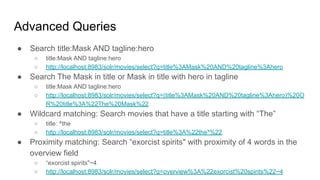
![● Range Queries
○ Inclusive Range Query: Square brackets [ & ]
■ budget:[500000 TO *]
○ Exclusive Range Query: Curly brackets { & }
■ budget:{500000 TO *}
● Boosting a Term with ^
○ Want a term to be more relevant?
■ toy^4 story
● For more about Queries:
○ https://lucene.apache.org/solr/guide/6_6/the-standard-query-parser.html
Advanced Queries](https://image.slidesharecdn.com/solrworkshop-200224190336/85/Solr-workshop-25-320.jpg)

























































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)

















