Download to read offline

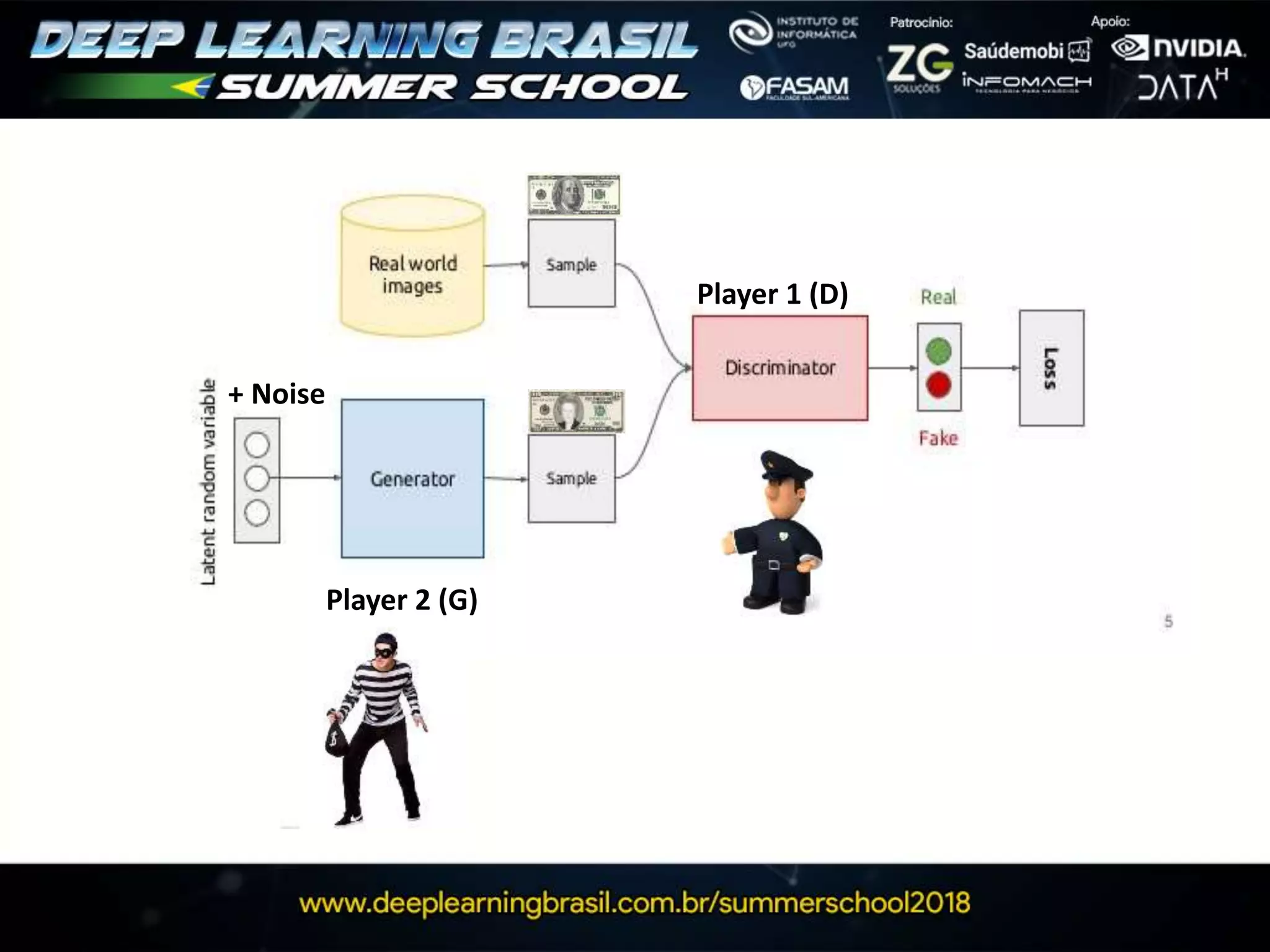










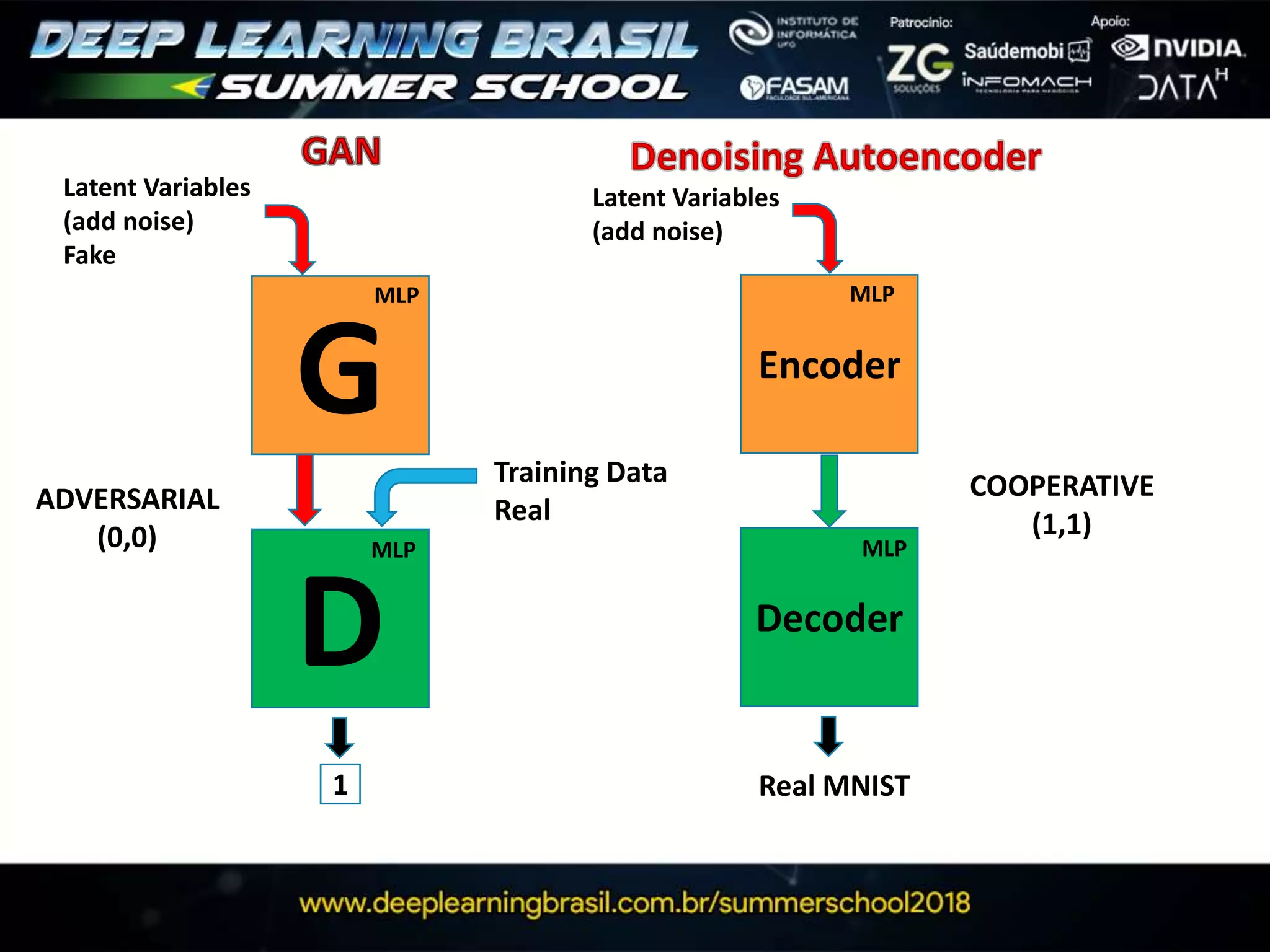

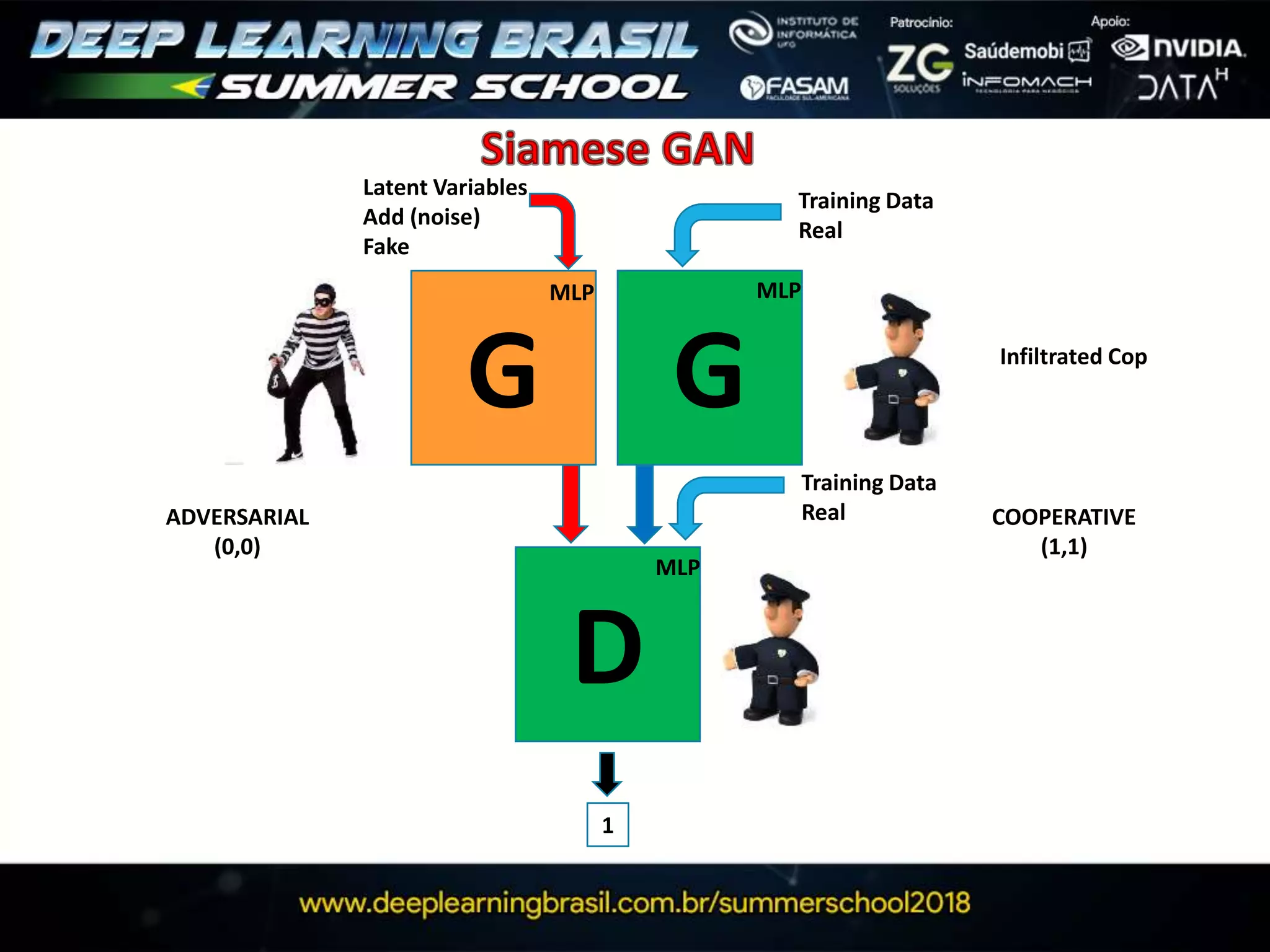




















![G
D
Latent Variables
(add noise)
Fake
Training Data
Real
MLP
MLP
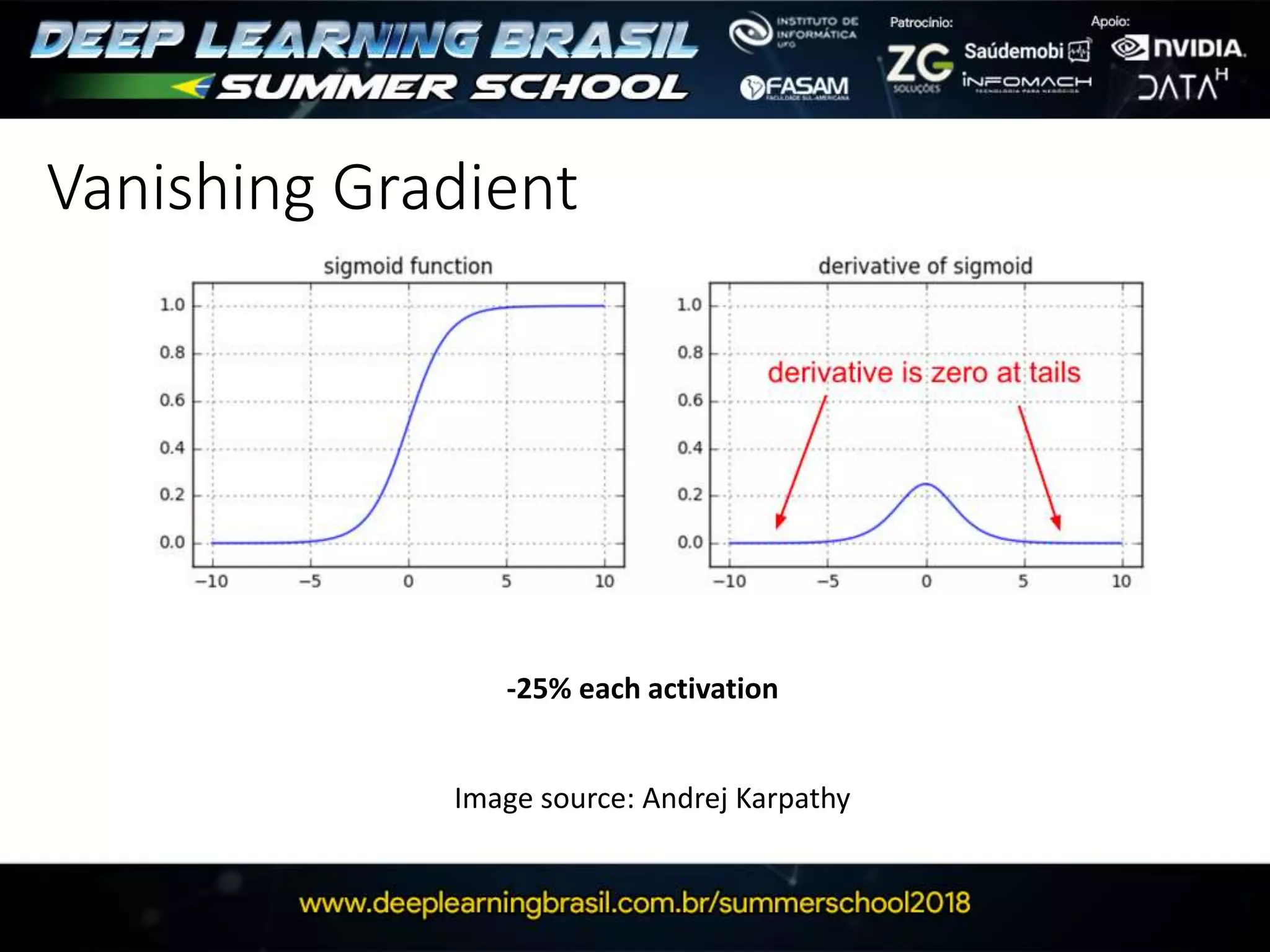
Relu
B
A
b b=[1,1,1,1,1,1,1,1,1,1] N=10
B=[0,0,0,0,0,1,1,1,1,1]
P(B=b) = 0.5
H(B)=-SumP(B=b).logP(B=b)
H(B)=-0.5.log(0.5)
H(B)=-0.15
H(A|B=b)=-0.8.log(0.8)
H(A|B=b)=-0.04
B=[0,0,0,0,0,1,1,1,1,1]
A=[0,0,0,0,0,0,1,1,1,1]
P(A|B=b) = 4/5= 0.8 (subsample)](https://image.slidesharecdn.com/ganssummerschool14layout-190223151115/75/GANs-Deep-Learning-Summer-School-55-2048.jpg)

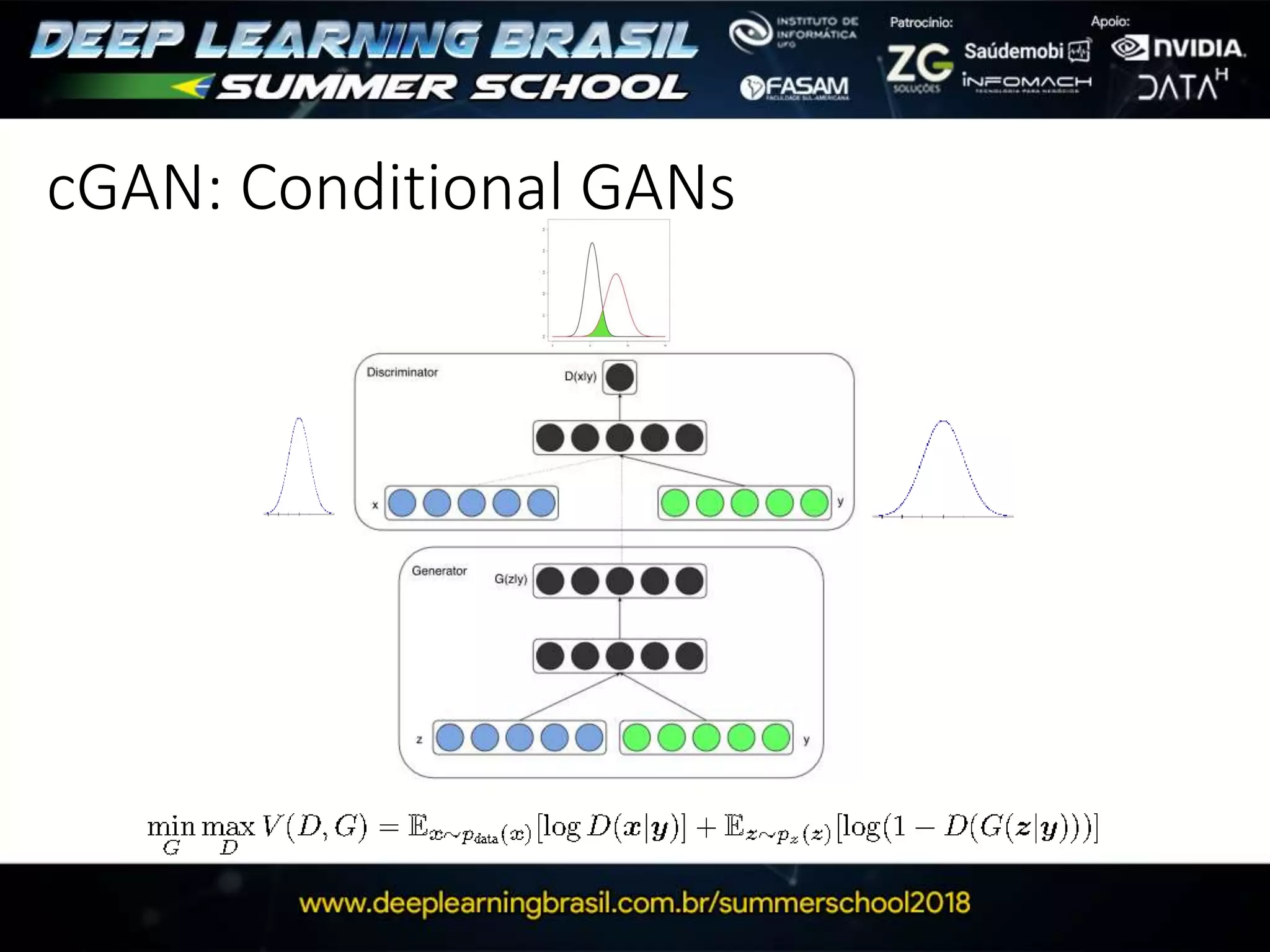


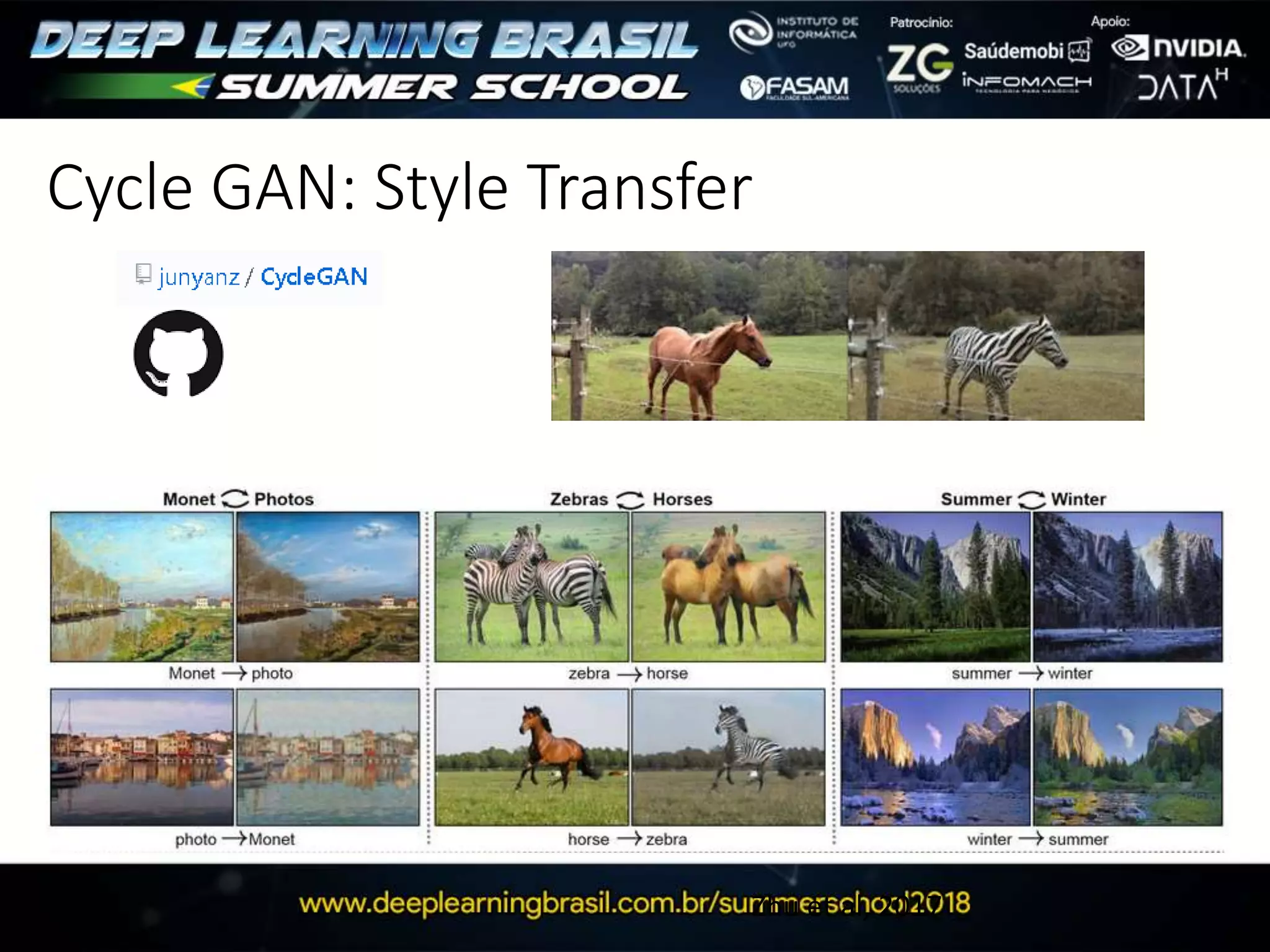





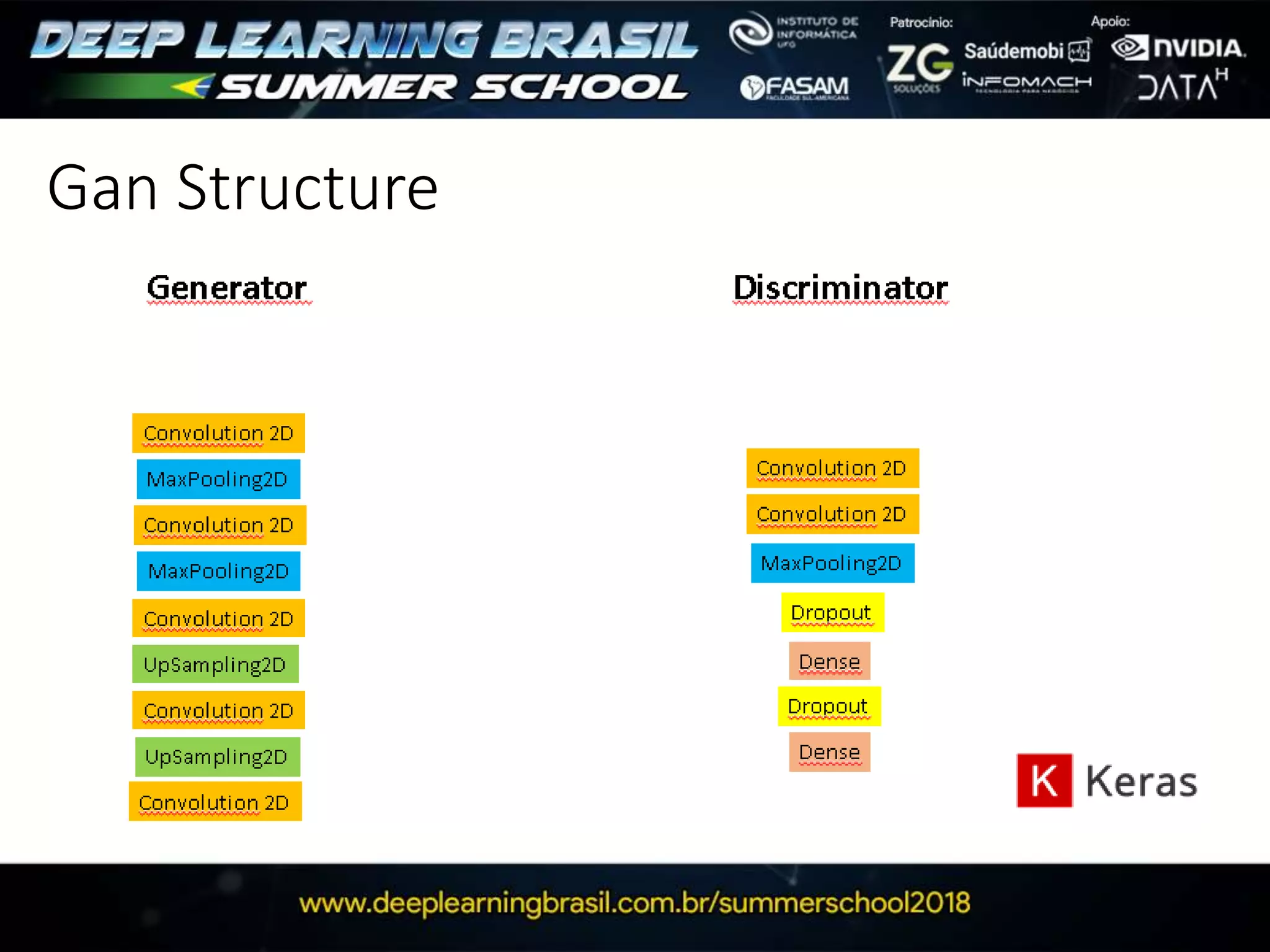

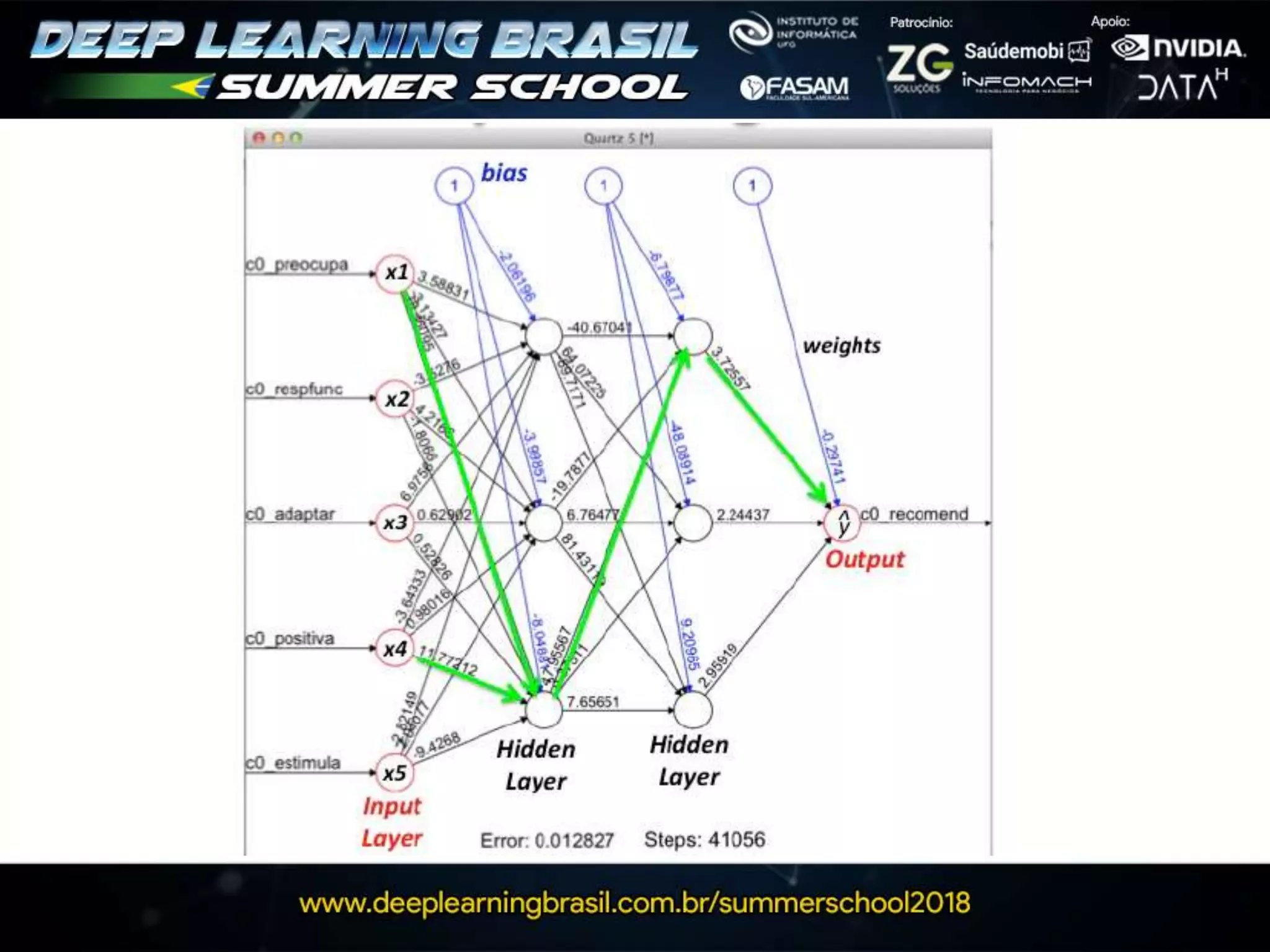




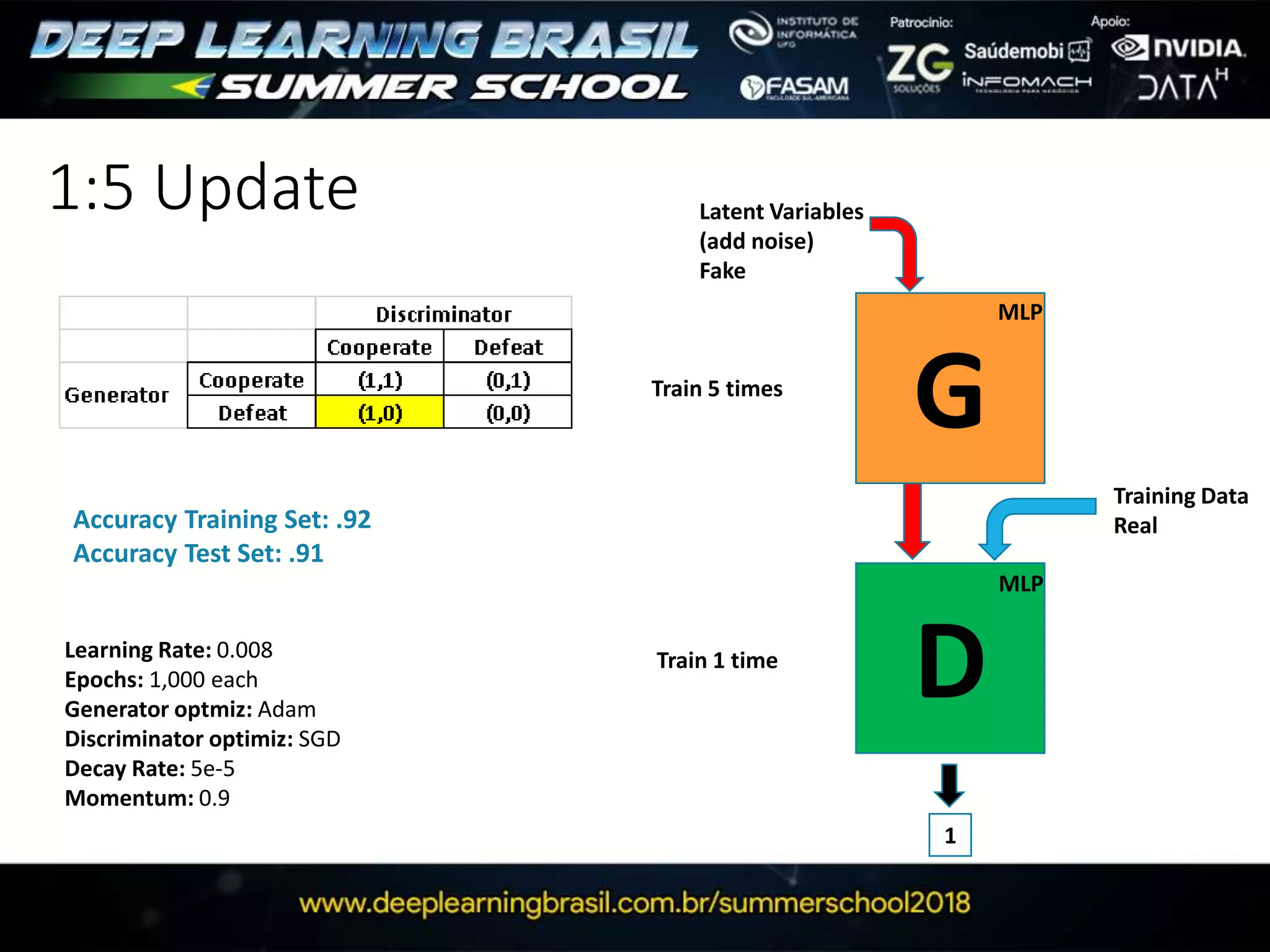
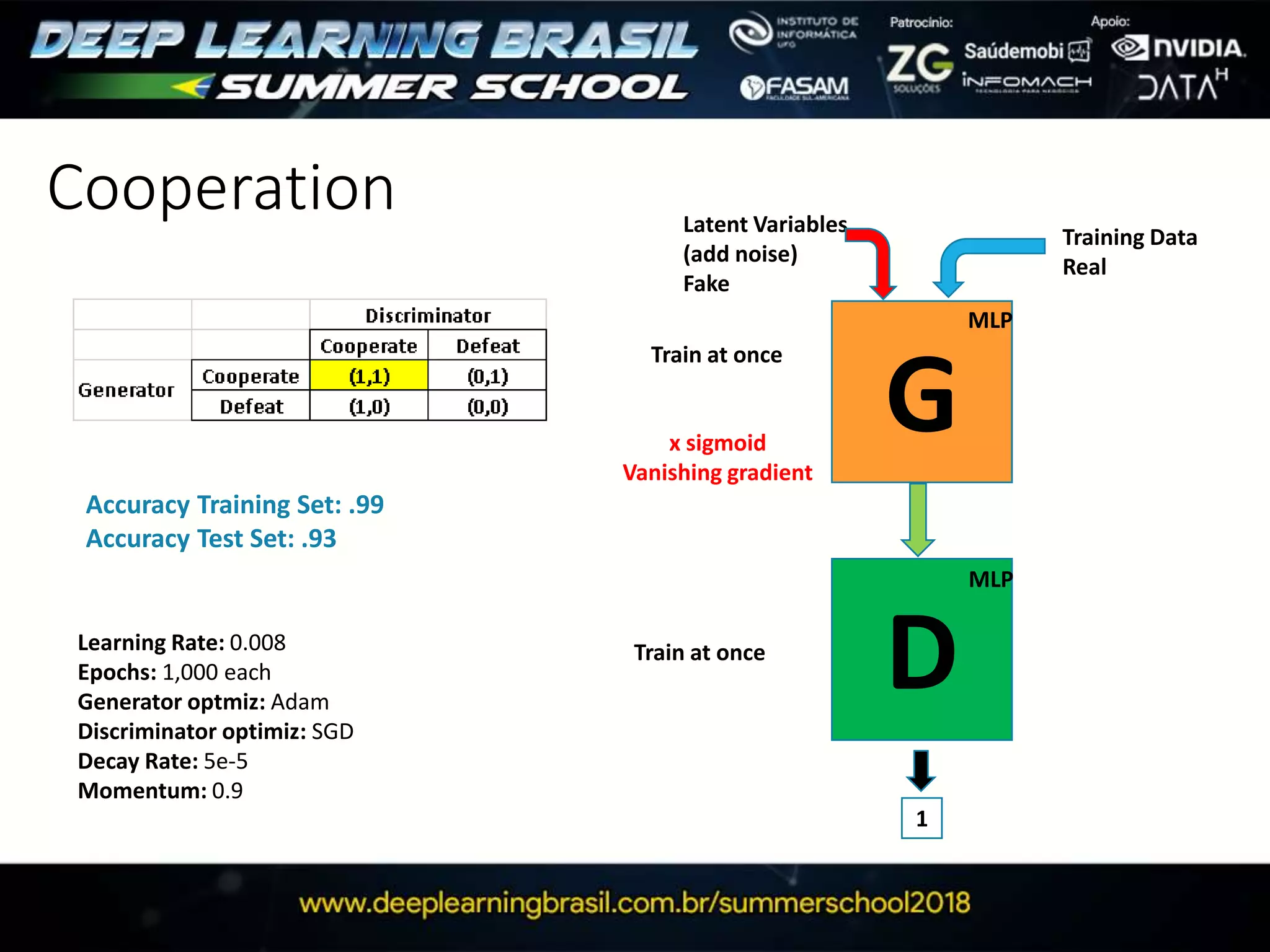
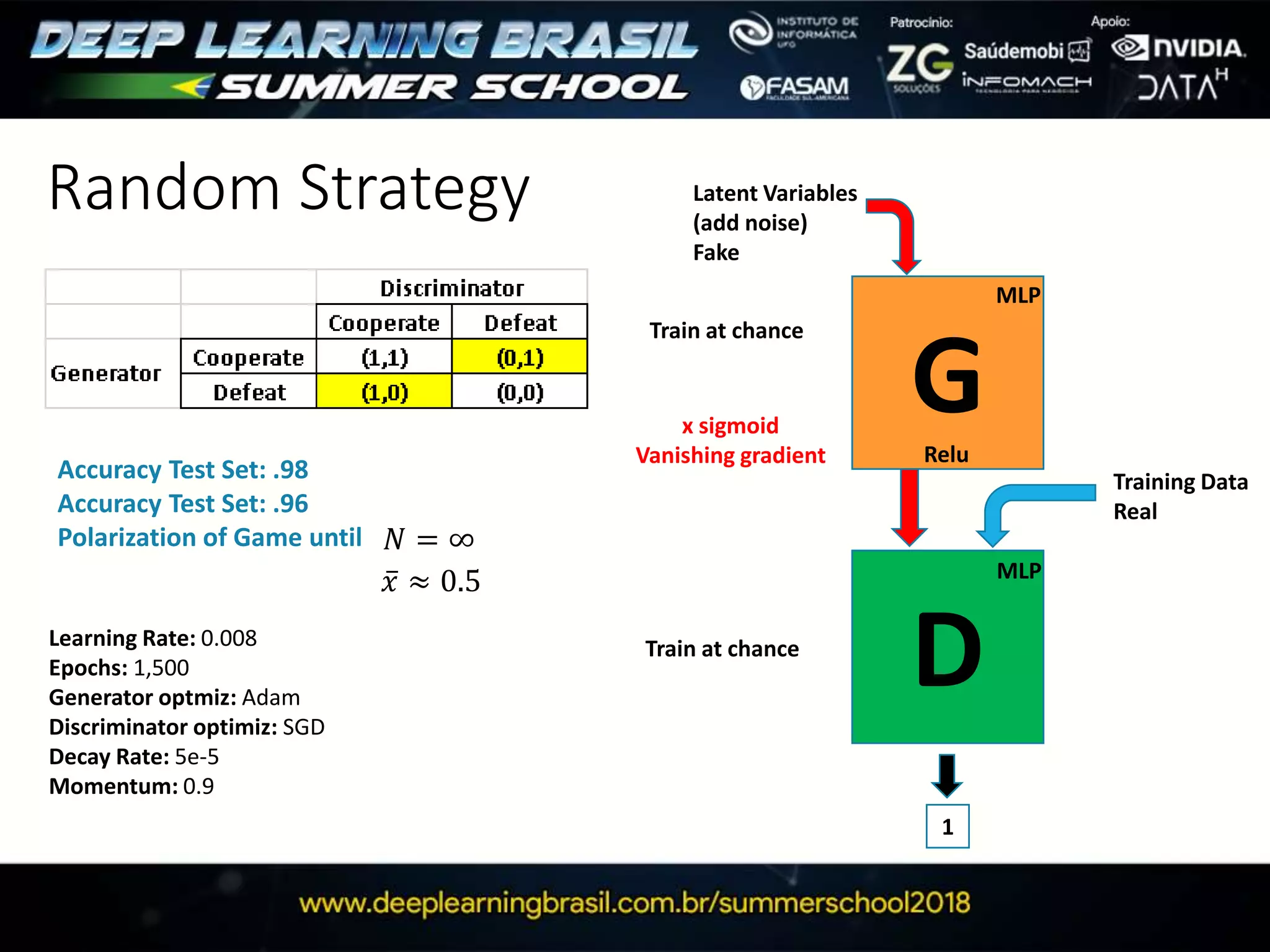
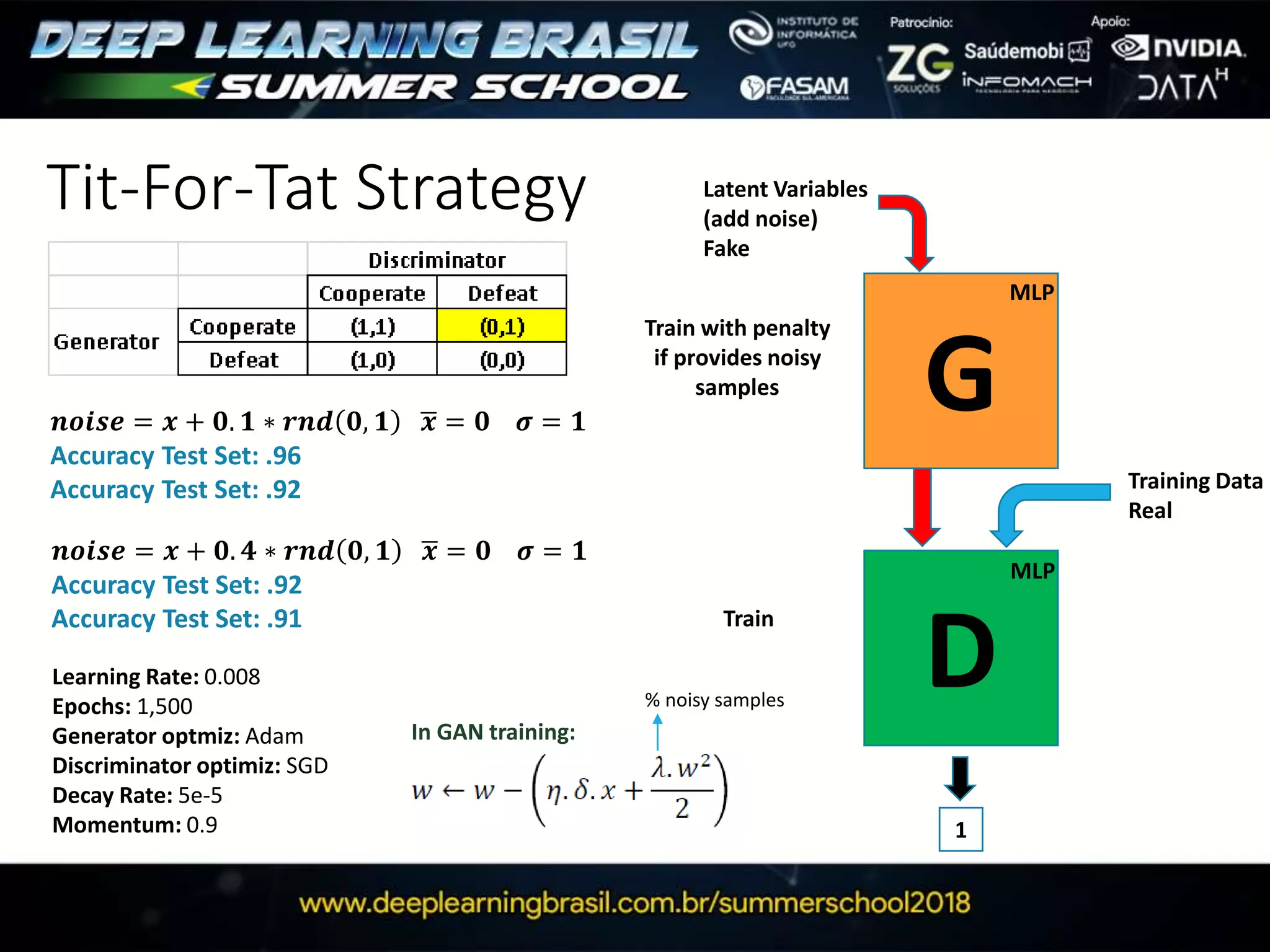
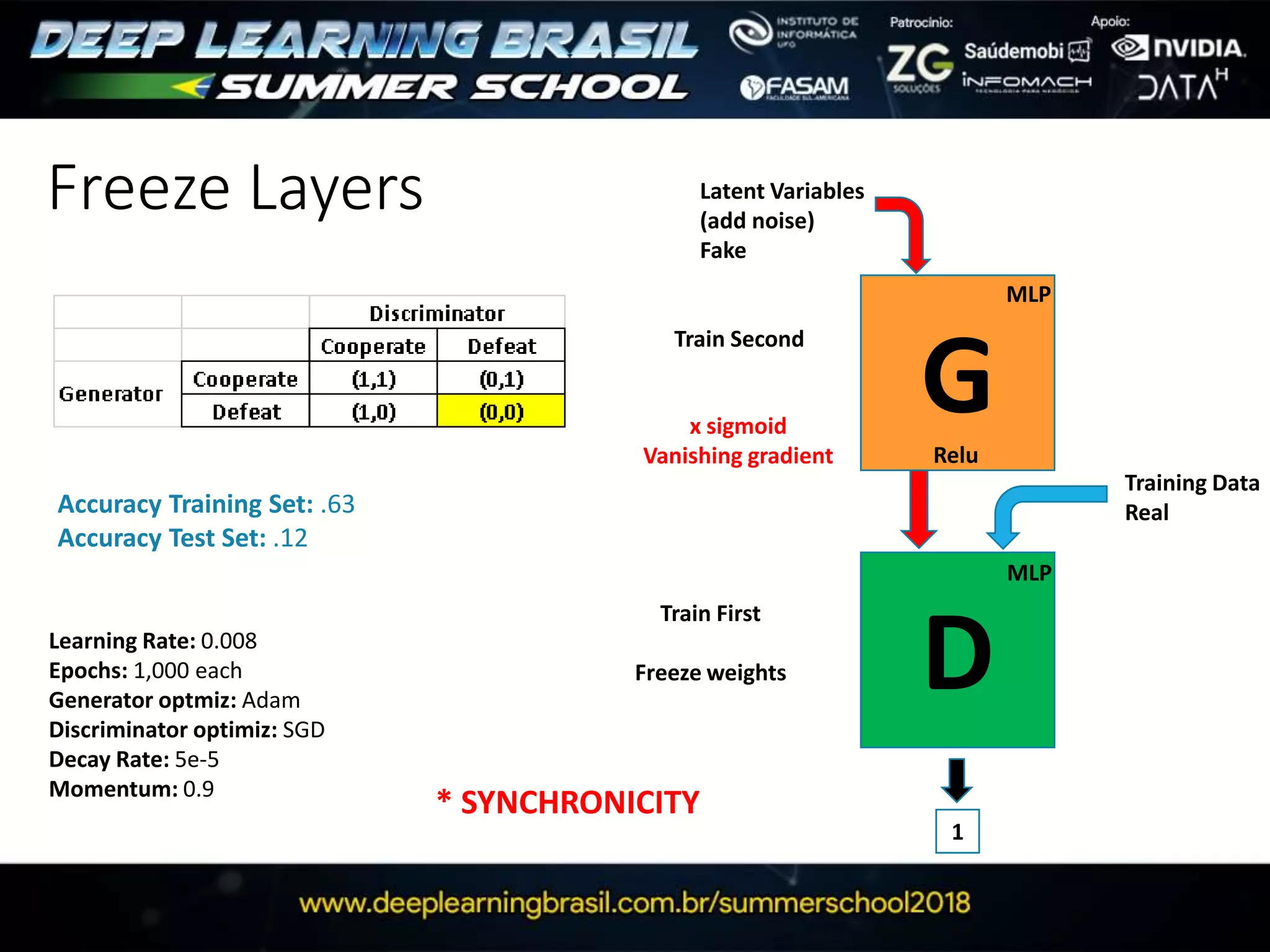
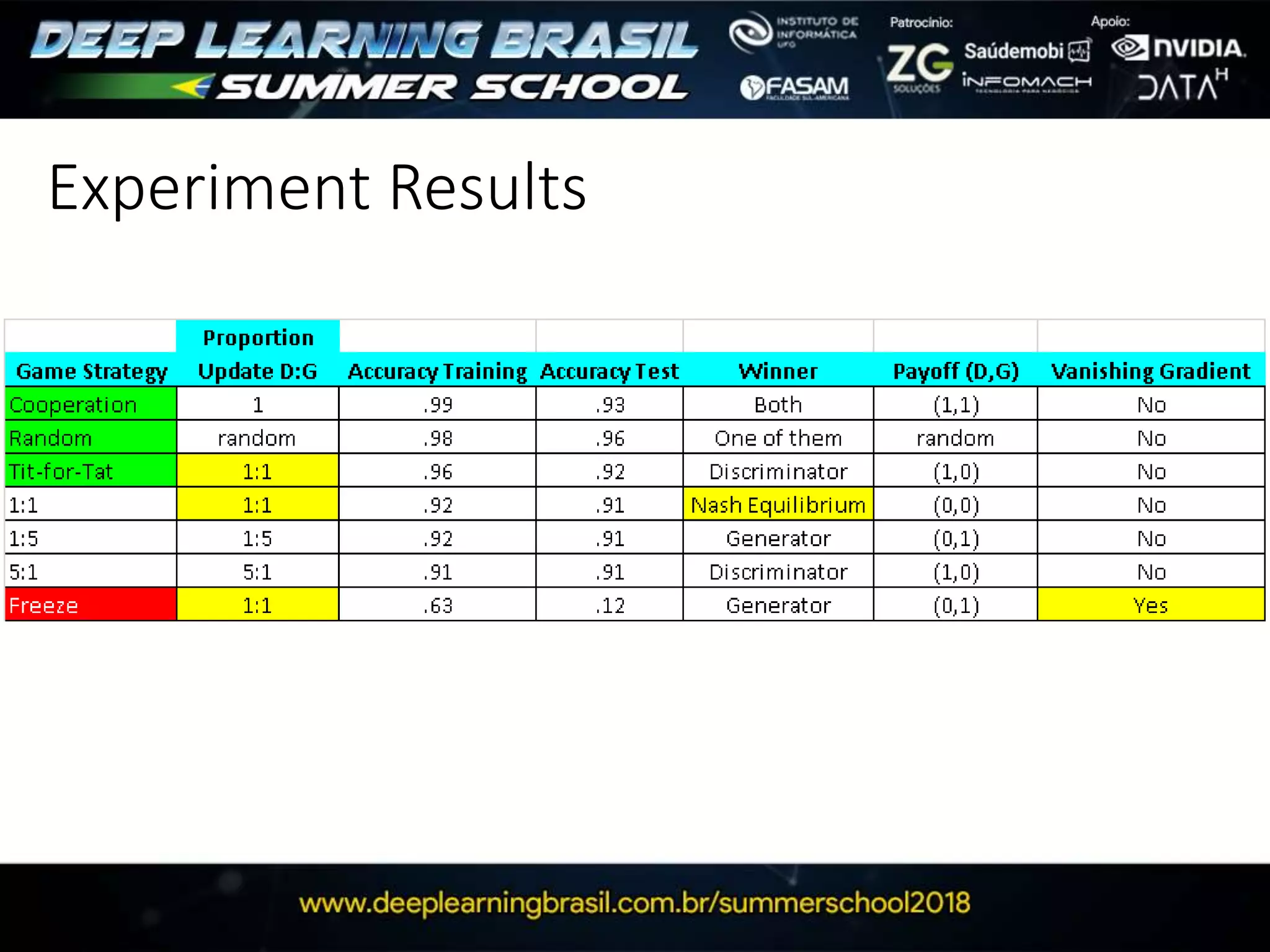

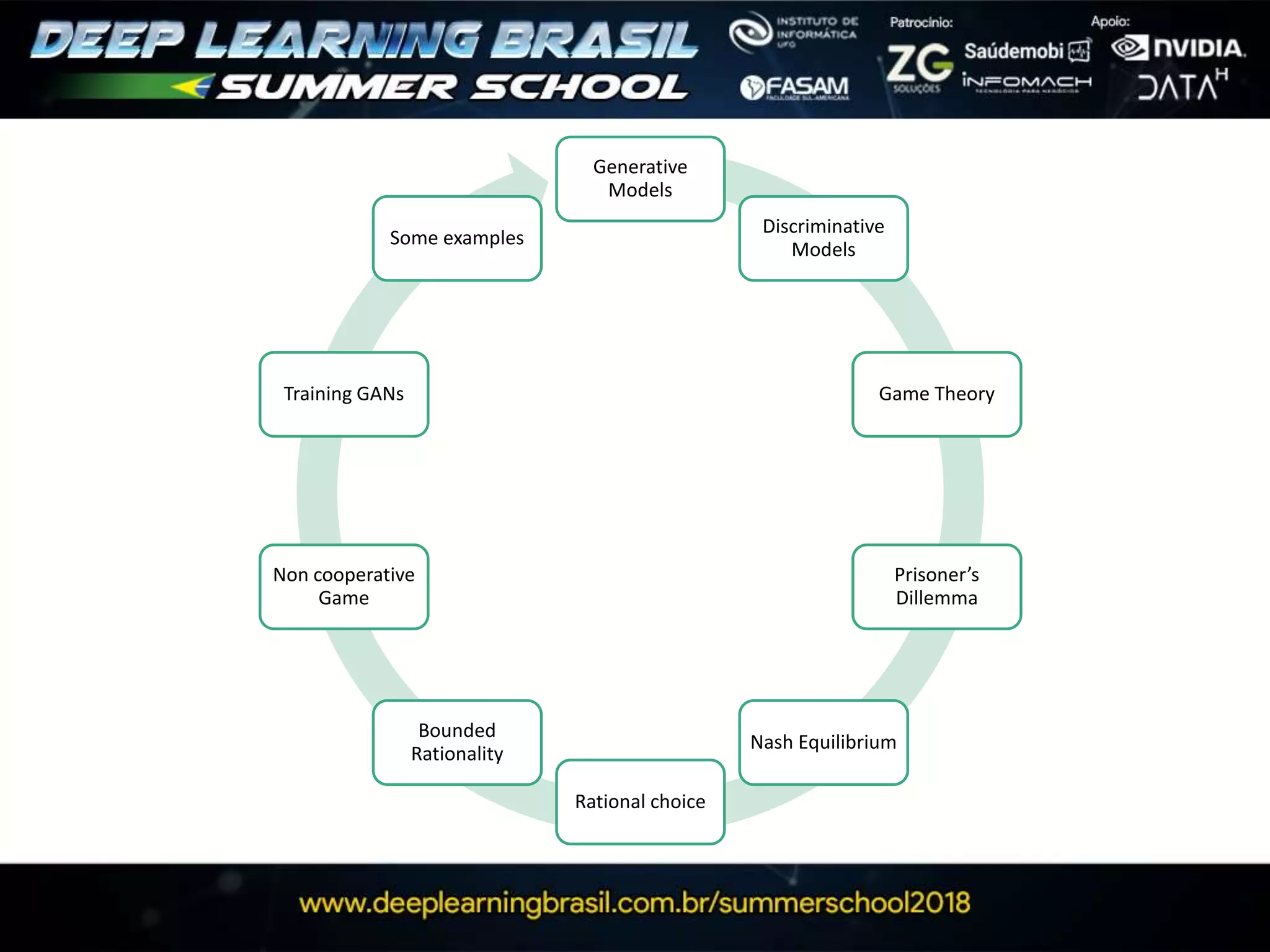
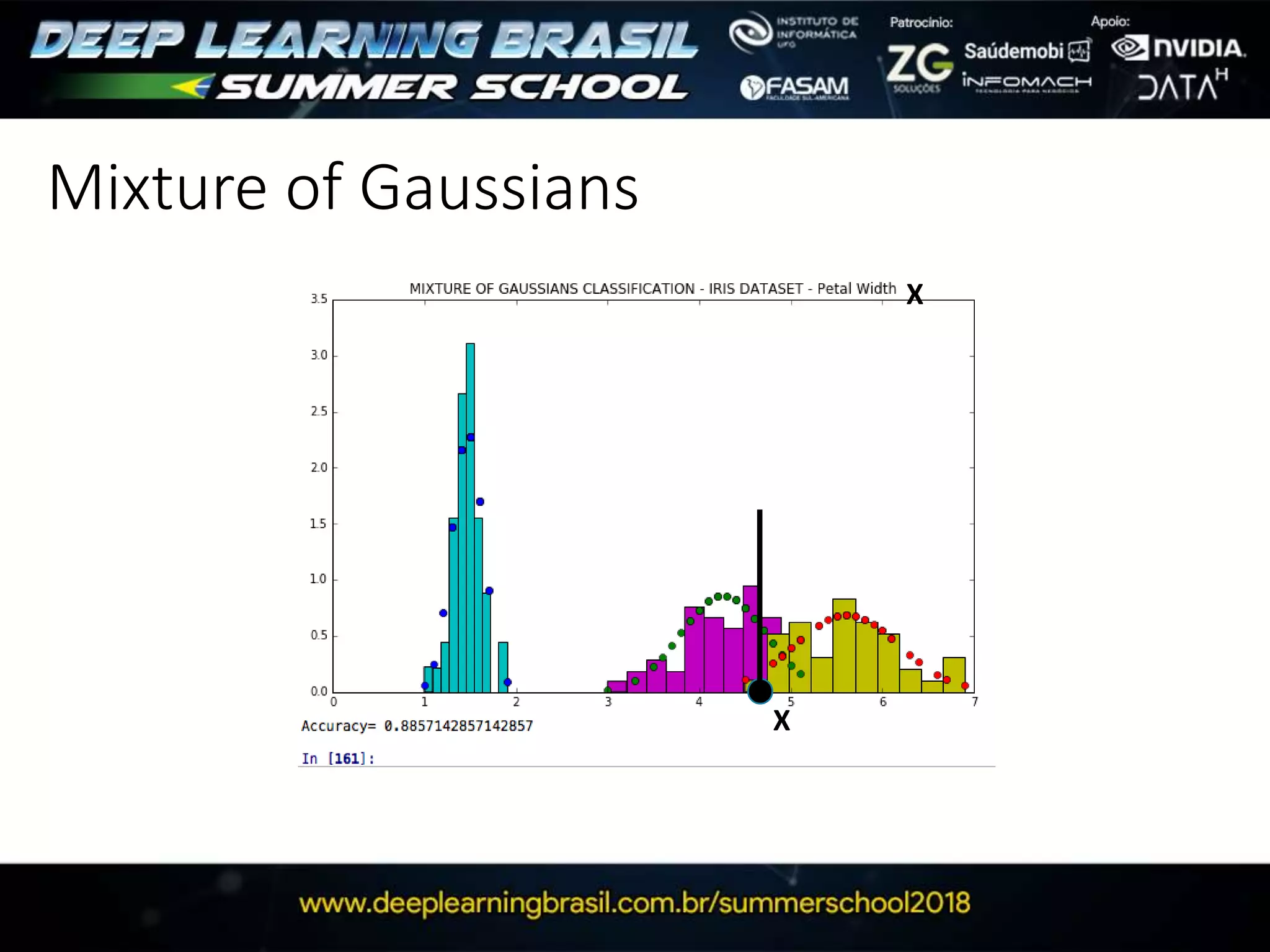
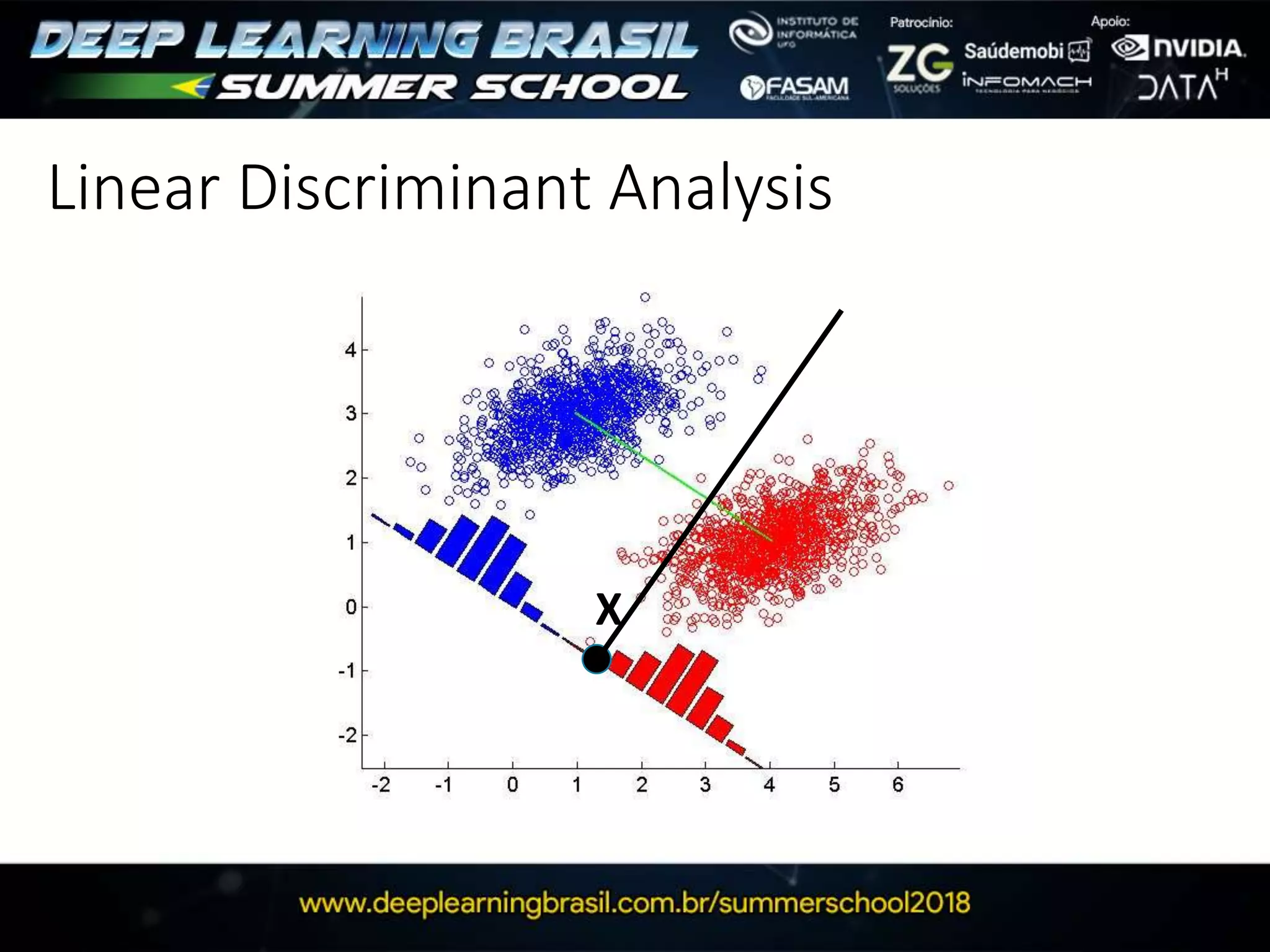
This document discusses generative adversarial networks (GANs) and provides several summaries: 1. GANs use two neural networks, a generator and discriminator, that compete in a game theoretic framework to generate new data instances that match the training data distribution. 2. Training GANs involves training the generator to generate more realistic samples to fool the discriminator while training the discriminator to better distinguish real and generated samples. 3. Several strategies for training GANs are discussed, including varying the update rates of the generator and discriminator, using cooperative or random update strategies, and applying penalties for noisy samples.








![[GAN by Hung-yi Lee]Part 1: General introduction of GAN](https://cdn.slidesharecdn.com/ss_thumbnails/part1-180809095233-thumbnail.jpg?width=640&height=640&fit=bounds)









![[GAN by Hung-yi Lee]Part 2: The application of GAN to speech and text processing](https://cdn.slidesharecdn.com/ss_thumbnails/part2v2-180809095331-thumbnail.jpg?width=640&height=640&fit=bounds)




![[한국어] Safe Multi-Agent Reinforcement Learning for Autonomous Driving](https://cdn.slidesharecdn.com/ss_thumbnails/safemultiagentrlforautonomousedriving4-170508165059-thumbnail.jpg?width=640&height=640&fit=bounds)





























































