Download as PDF, PPTX




























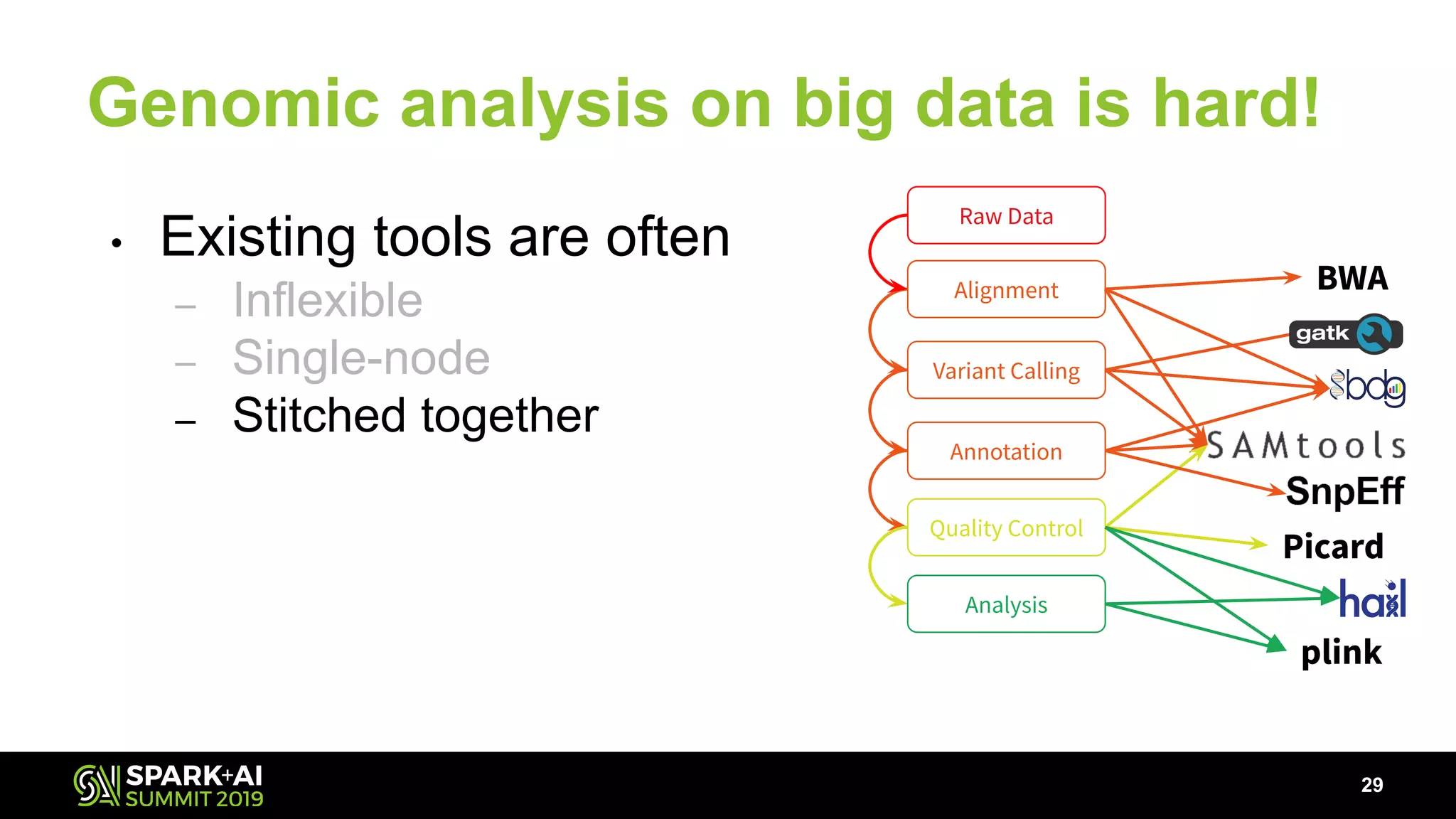





















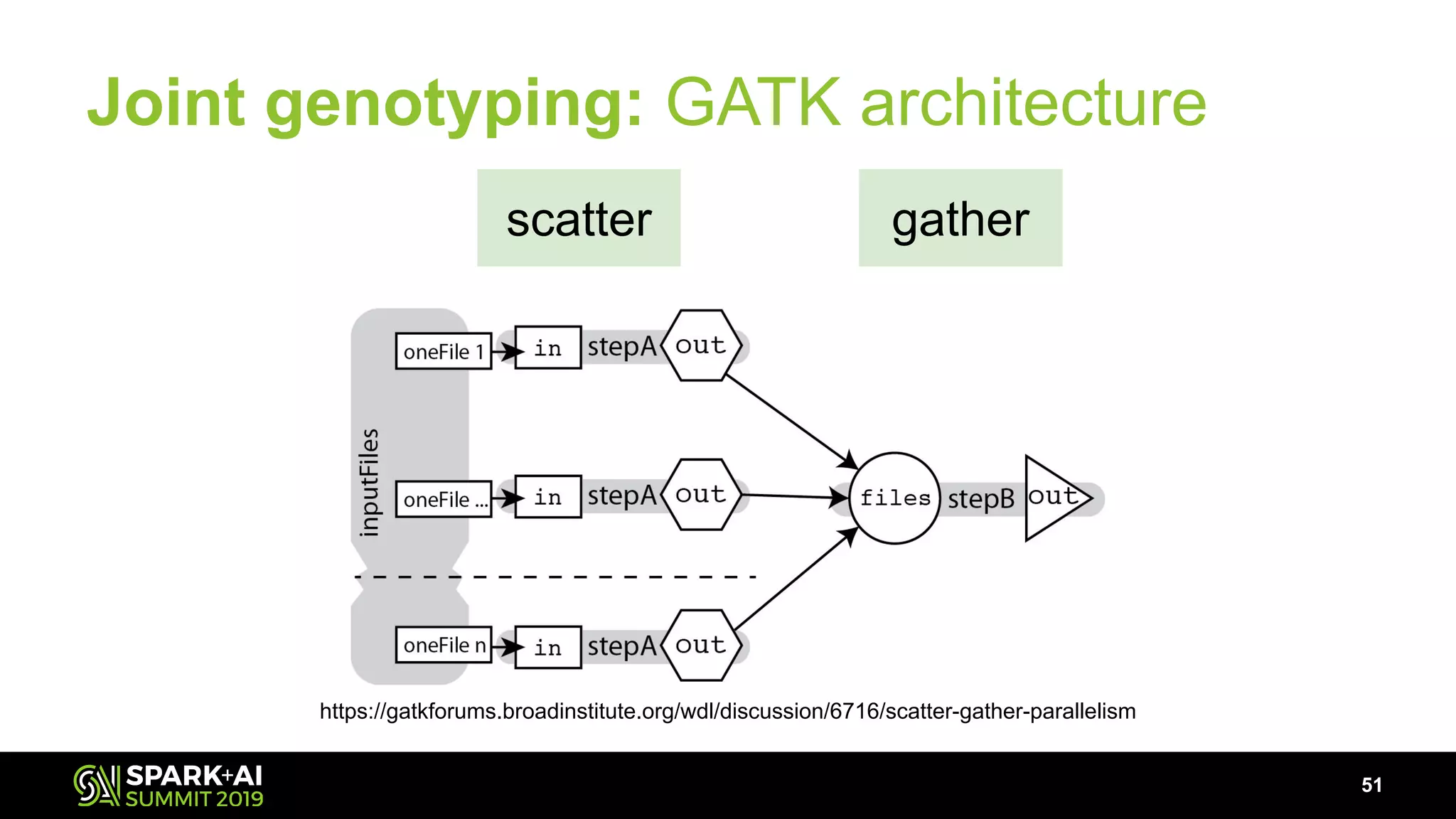






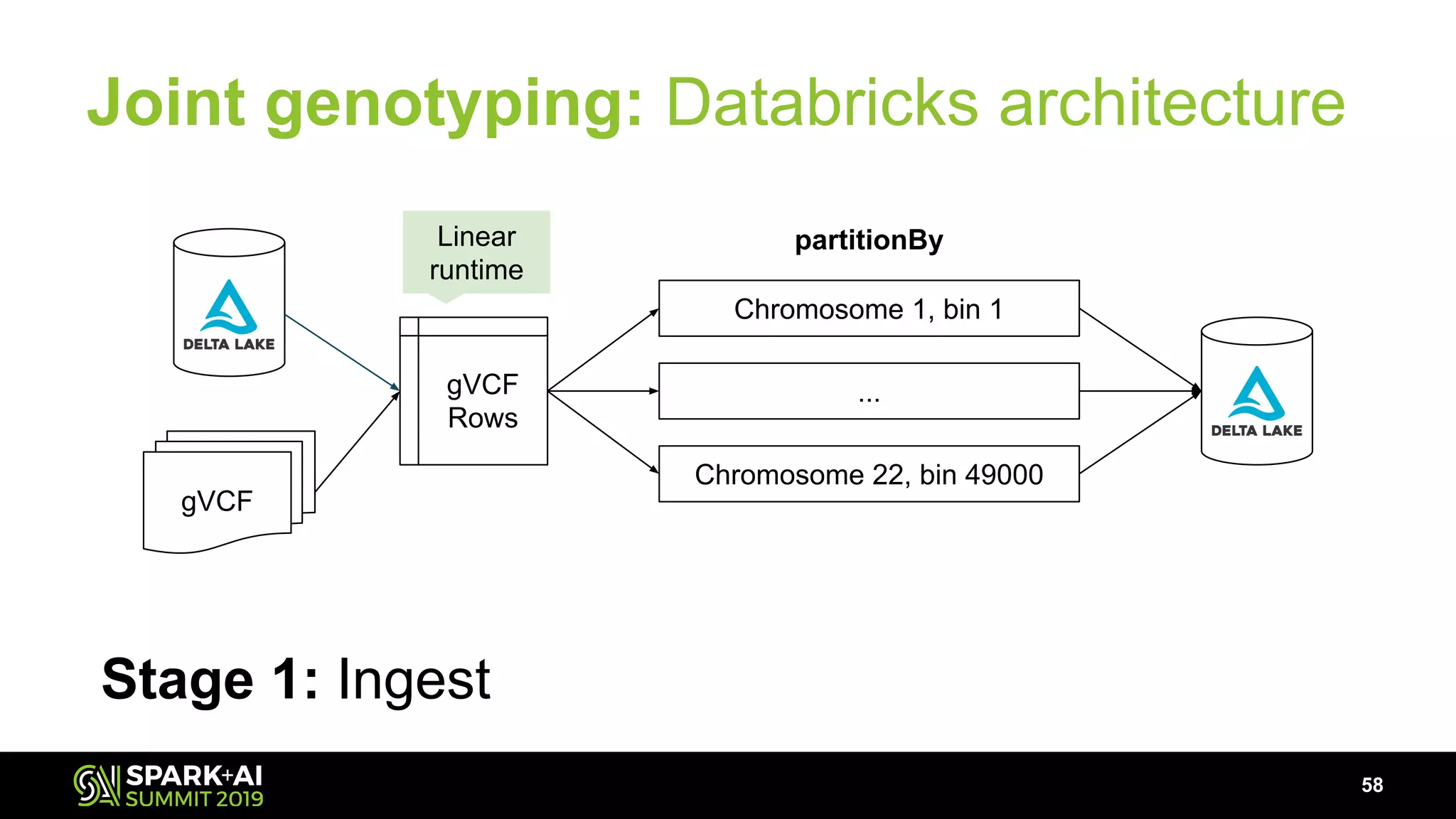




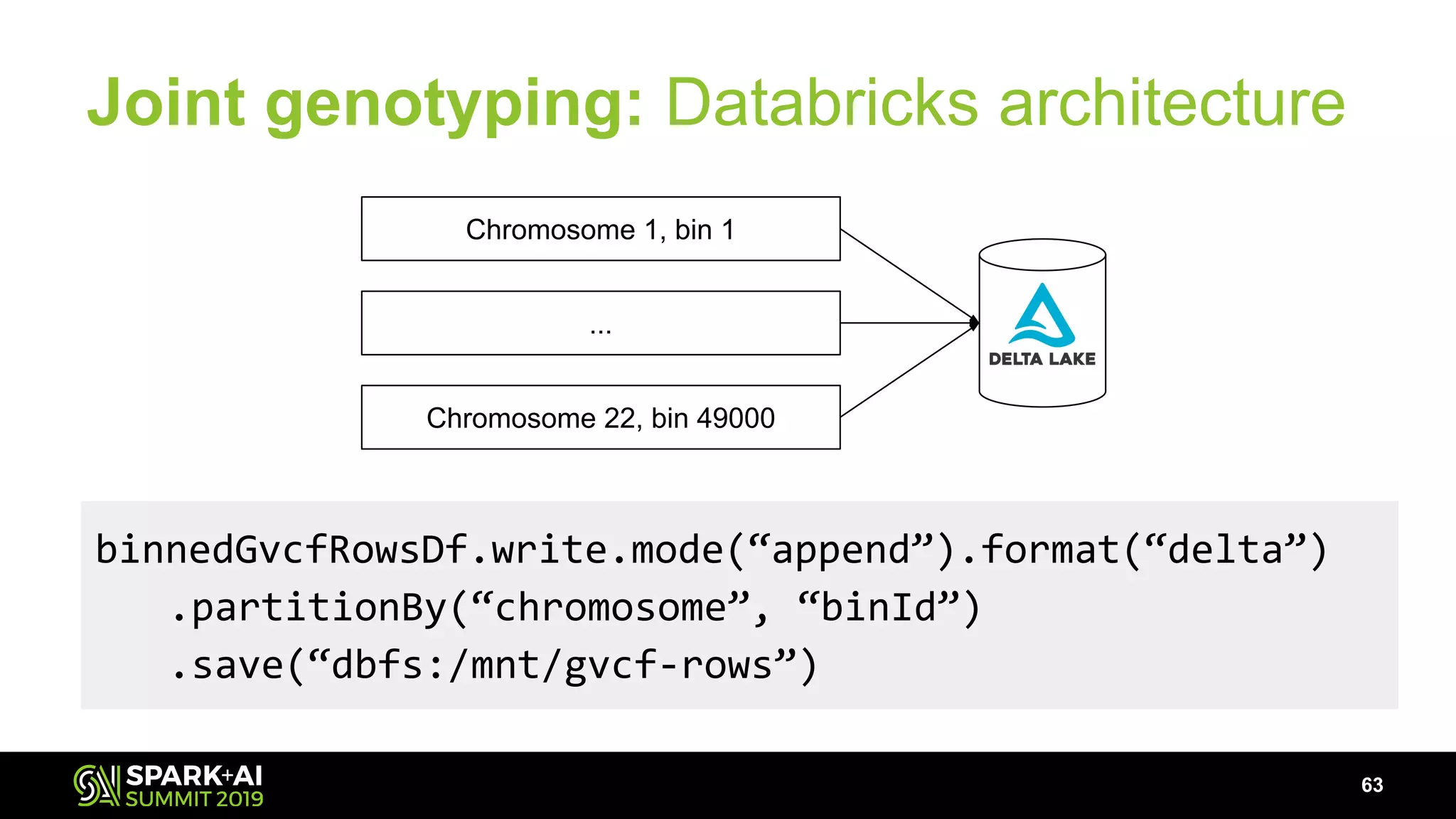
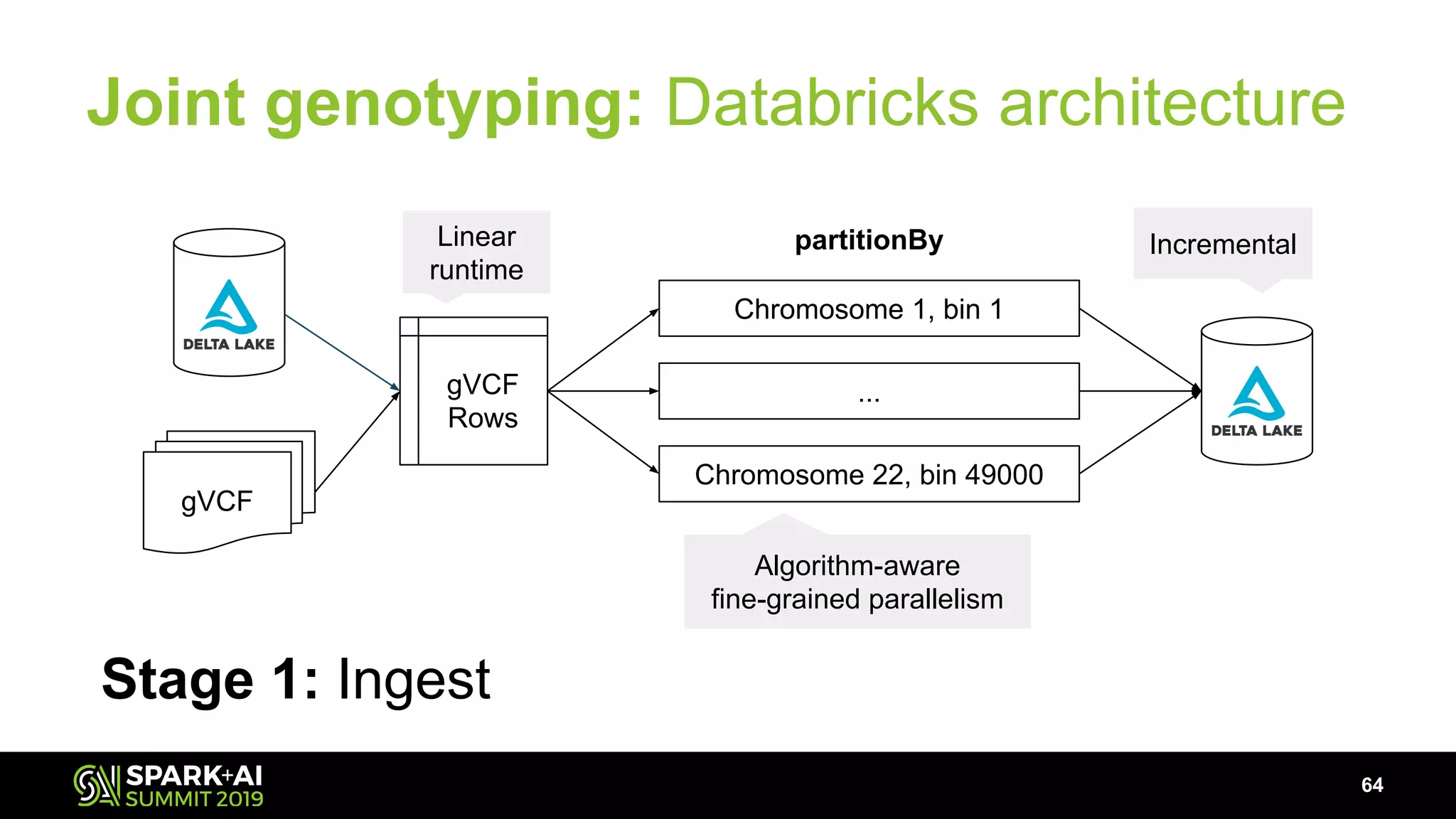







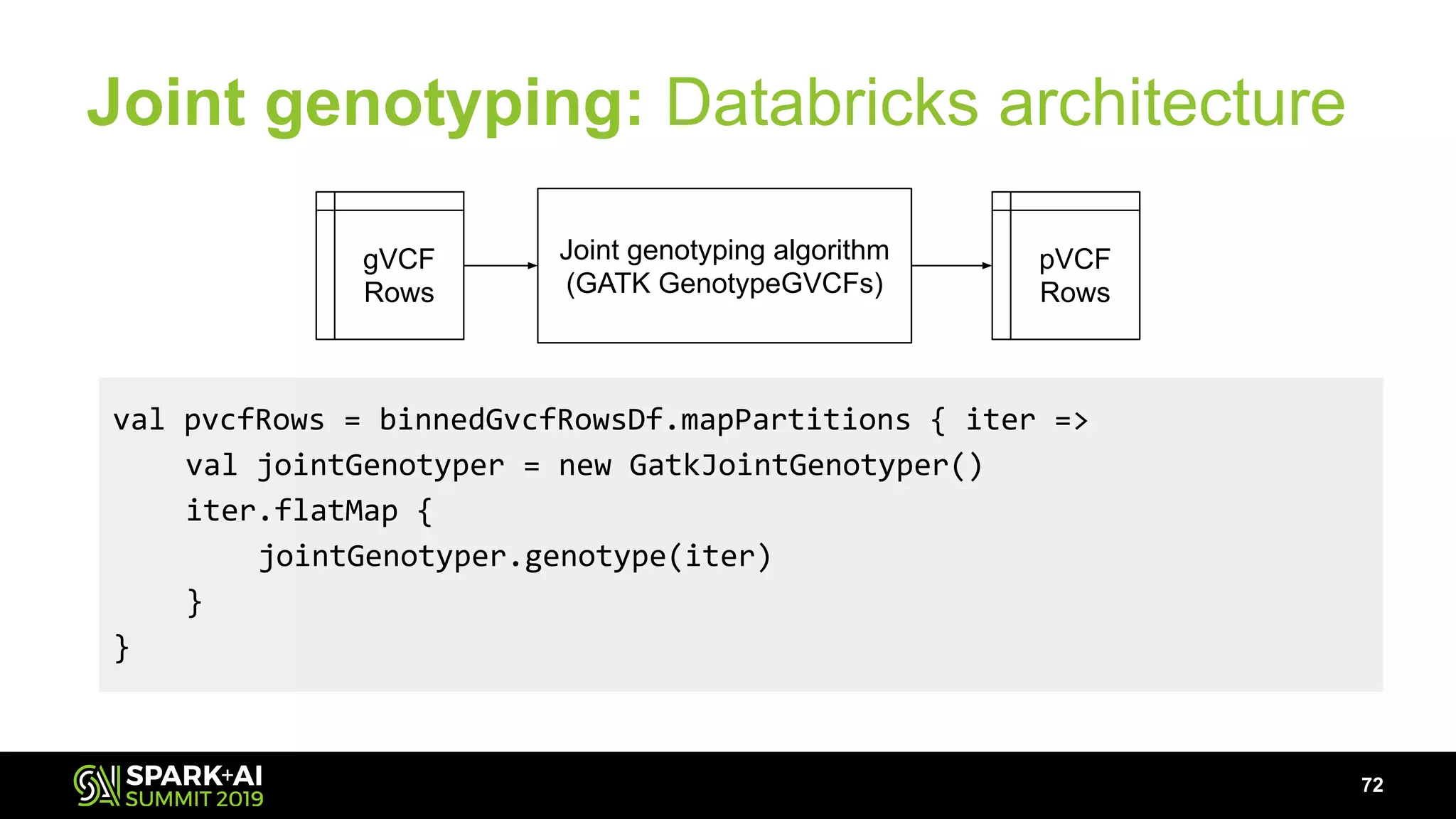
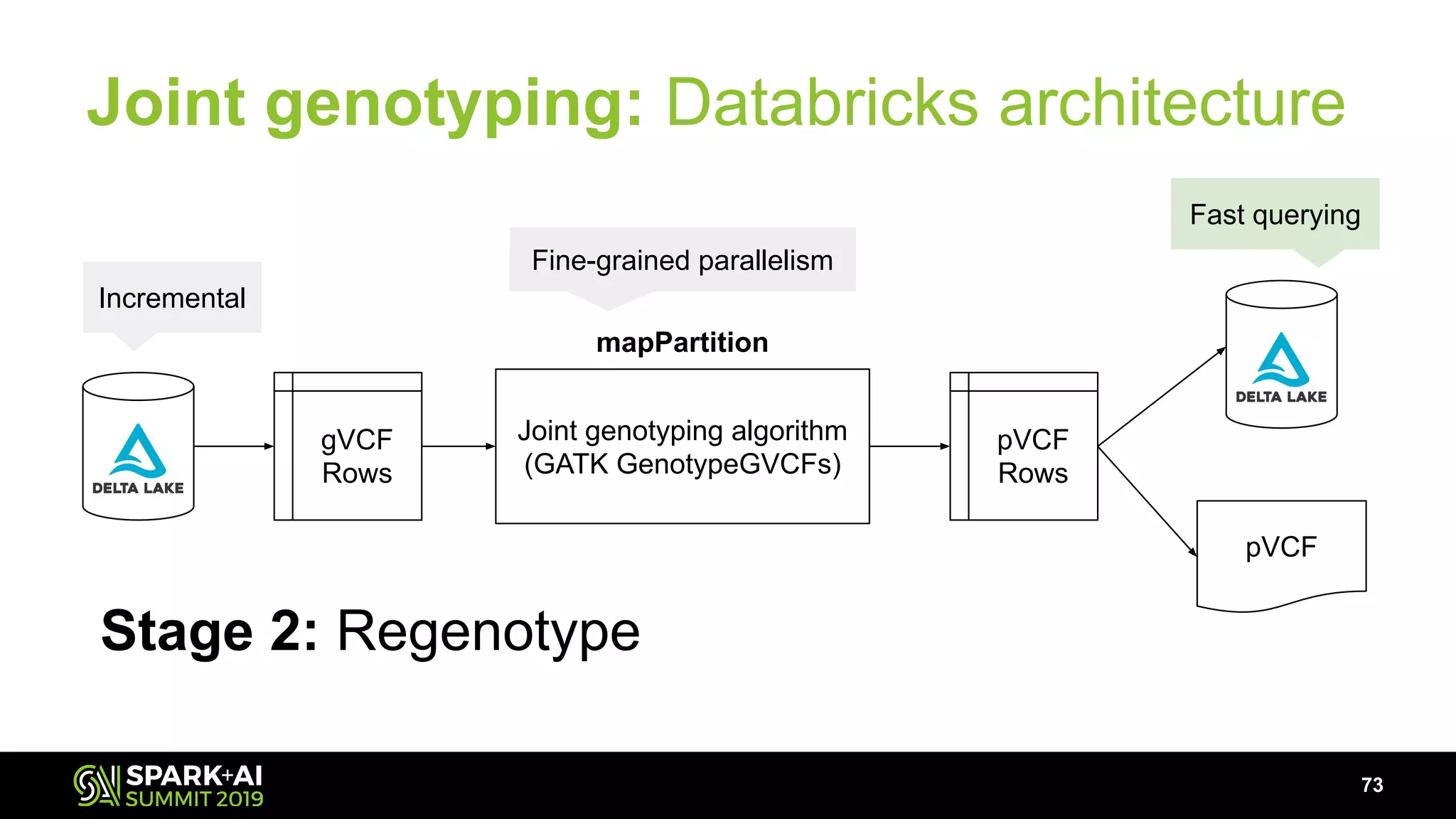
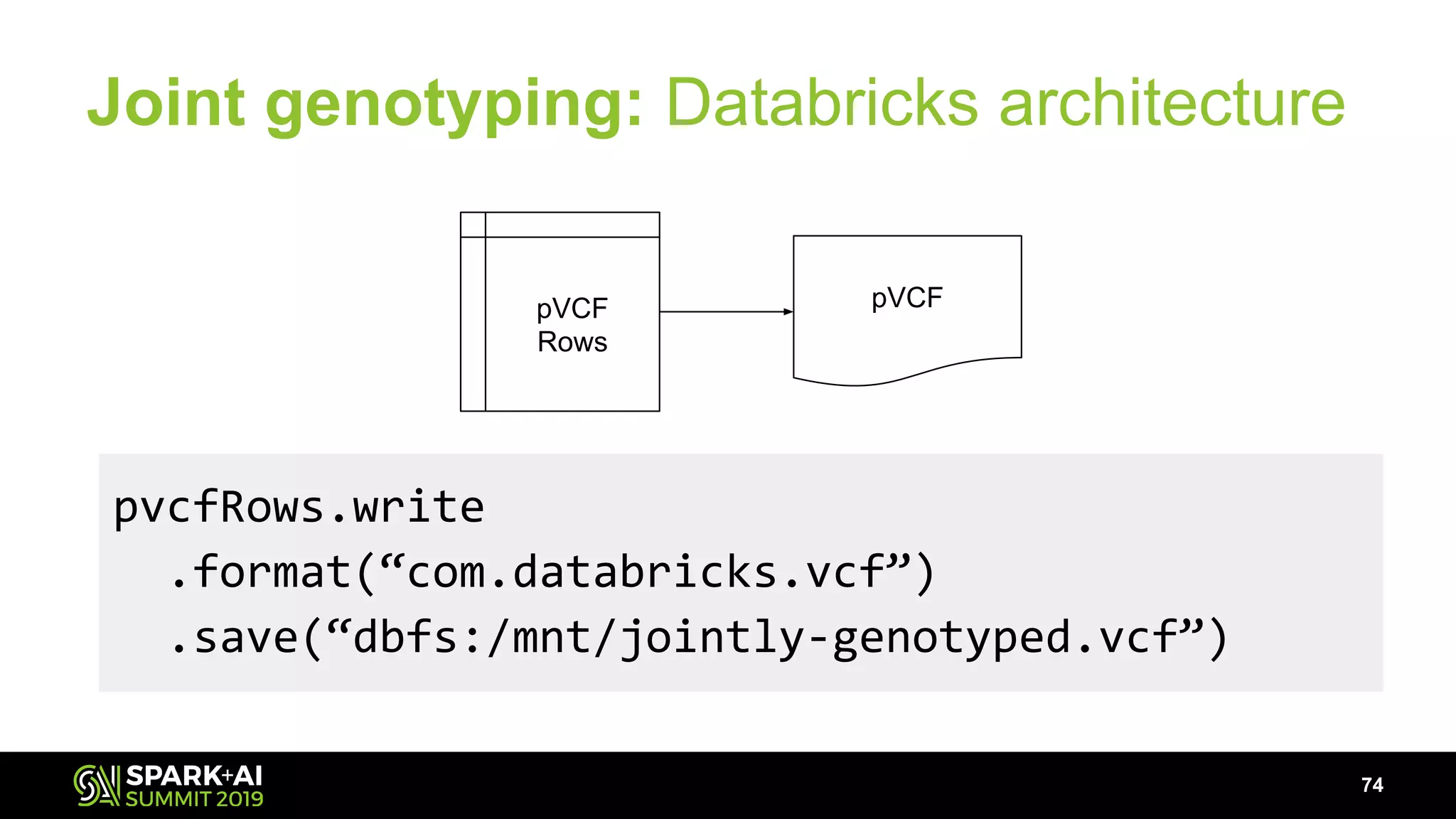





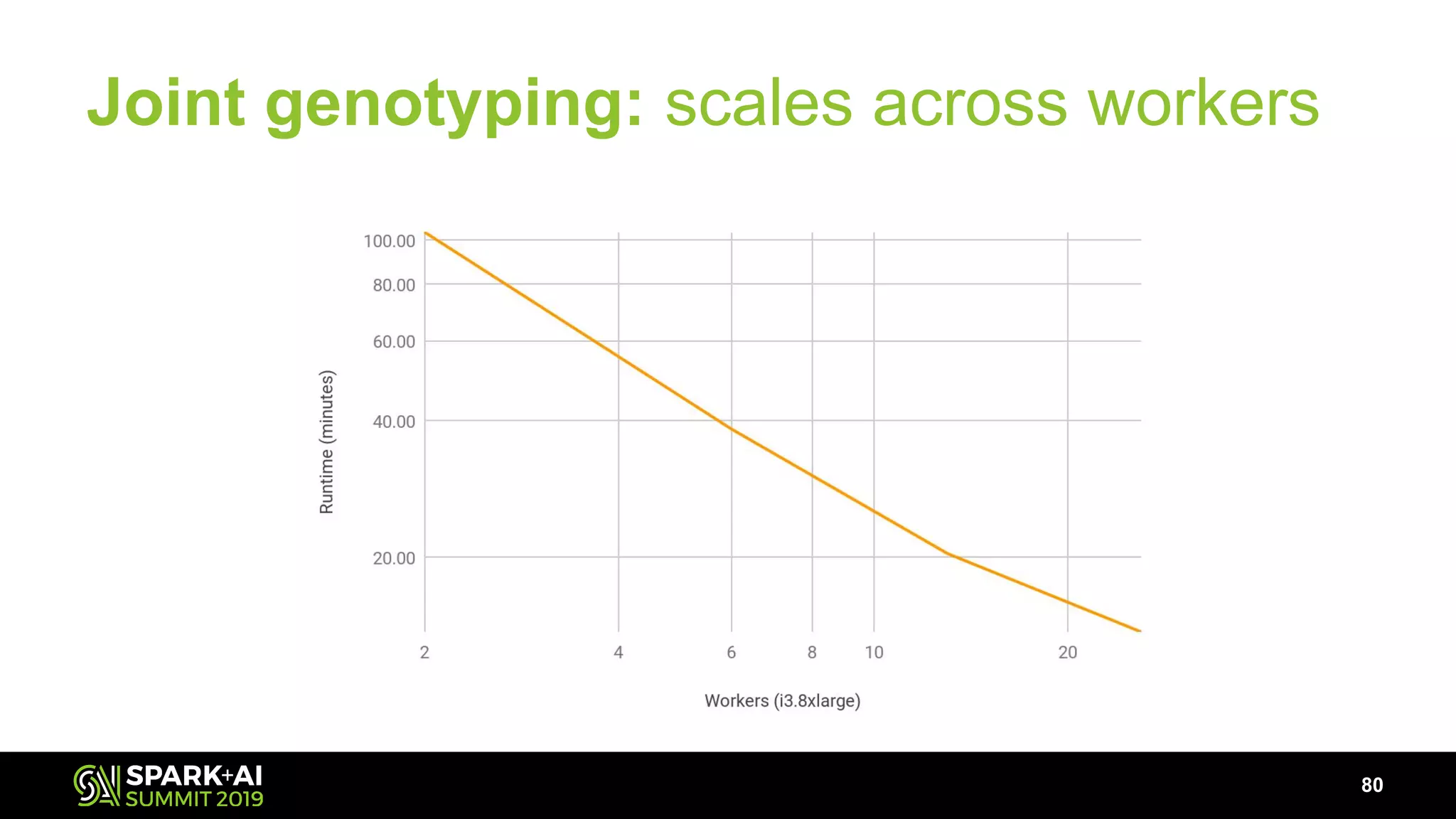












The document discusses advancements in genomics and healthcare, highlighting the case of a 6-year-old boy who was cured of a rare genetic condition through genomic sequencing and stem cell transplantation. It explores the challenges of genomic data analysis, emphasizing the need for efficient processing techniques, particularly using Databricks for joint genotyping. The presentation outlines the potential of big genomic data to accelerate drug discovery, optimize treatment, and reduce healthcare costs.






































































![[DSC Europe 25] Dragan Vucic - Building the Learning Organization - How AI Tr...](https://cdn.slidesharecdn.com/ss_thumbnails/8brigo2sbu6qur6gxrra-7-251205085715-6ae07d24-thumbnail.jpg?width=640&height=640&fit=bounds)







![[DSC Europe 25] Vid Stimac - Policy Parsimony: Between Oversimplifying and Ov...](https://cdn.slidesharecdn.com/ss_thumbnails/eqlepagzqp2rhg3gbluh-dsc-stimac-251120-251205090438-059e7f54-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC Europe 25] Goran Obradovic - The Rise of Sovereign AI: Building the Regi...](https://cdn.slidesharecdn.com/ss_thumbnails/7nw2xxixrxqdxvrb5wca-6-251205085714-ab09a2ac-thumbnail.jpg?width=640&height=640&fit=bounds)



