Download to read offline
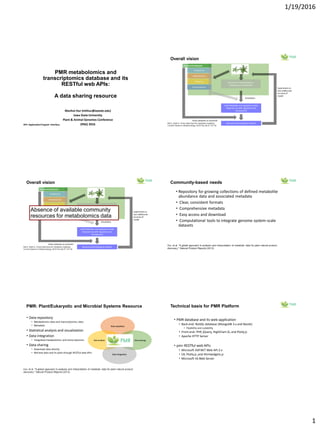
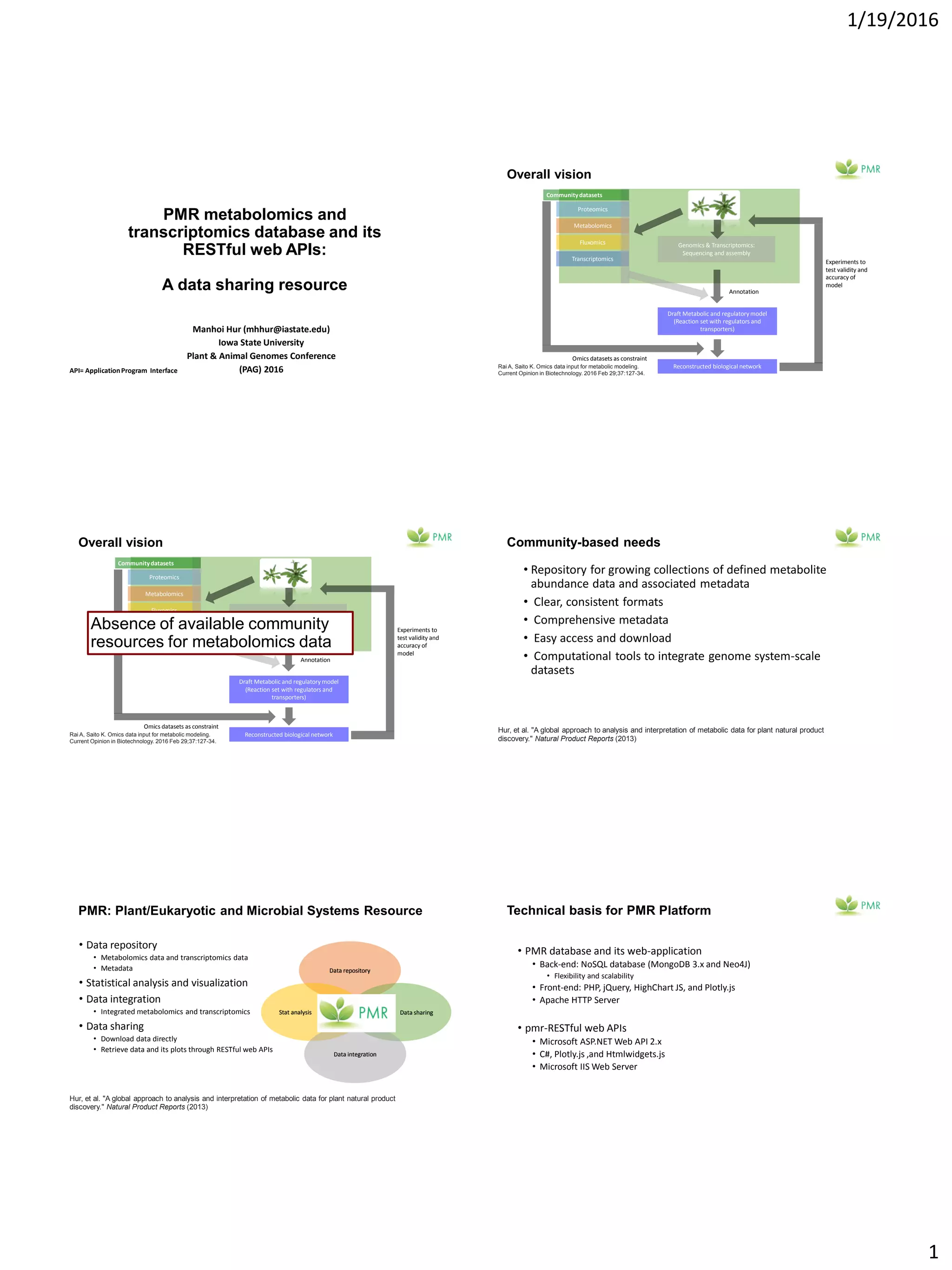


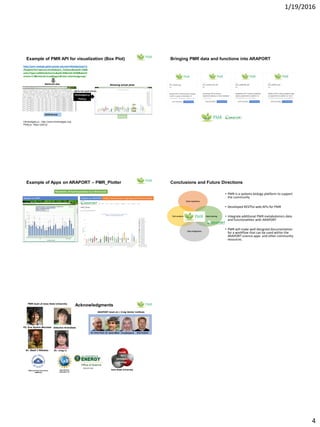

The document discusses the PMR (Plant & Microbial Resource) platform, which offers a database for metabolomics and transcriptomics data along with RESTful web APIs for data sharing. It highlights the need for community resources in metabolomics and presents the platform's capabilities for integrating various omics datasets, enabling statistical analysis, and visualization tools. Future plans include enhancing data integration with other platforms and providing comprehensive documentation for community use.















































































