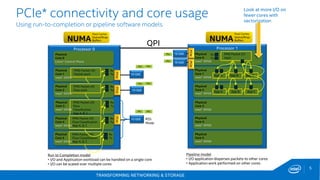
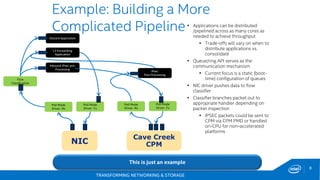
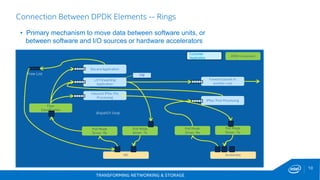
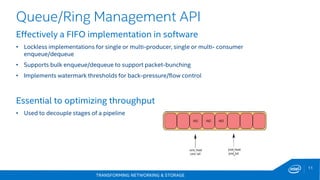
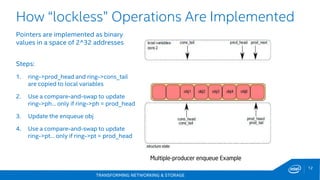
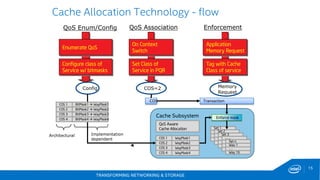
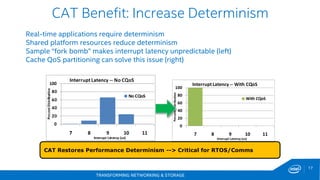
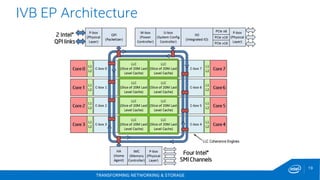
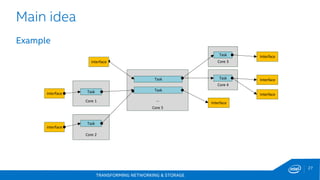
This document discusses new hardware features including CAT, COD, and Haswell, as well as network platforms. It provides an overview of run-to-completion and pipeline software models for network processing. Run-to-completion allows I/O and application work to be handled on a single core, while pipeline distributes packets to other cores for application work. Lockless queues are used to share data between cores and threads. Rings are the primary mechanism to move data between software units and I/O sources in DPDK.














![TRANSFORMING NETWORKING & STORAGE
22
40GbE Fortville family (XL710/X710)
Comparing Controller Typical Power
82599EB
1 x 40GbE
3.3 watts2
Typical Power
2 x 10GbE
5.2 watts1
Typical Power
Source as of Aug 2014: 1: 82599 Datasheet rev 2.0 Table 11.5 for 2x10GbE Twinax Typical Power [W] 2:
XL710 Data sheet rev 1.21 Table 14-7 Typical Active Power 1x40GbE Power [W]
30%
65%
2x
Power Efficiency Improvements
UP TO 30%
Reduction
TYPICAL POWER
UP TO 65%
Reduction In
GIGABIT PER WATT
Increase in
TOTAL
BANDWIDTH](https://image.slidesharecdn.com/2newhwfeaturescatcodetc-150616083423-lva1-app6892/85/2-new-hw_features_cat_cod_etc-22-320.jpg)






![TRANSFORMING NETWORKING & STORAGE
30
DPPD: Very simple Port Forwarding
FWD
ETH1 ETH2
[port 0] ;DPDK port number
name=cpe0
mac=00:00:00:00:00:01
[port 1] ;DPDK port number
name=cpe1
mac=00:00:00:00:00:02
[core 1]
name=FWD
task=0
mode=none
rx port=cpe0
tx port=cpe1](https://image.slidesharecdn.com/2newhwfeaturescatcodetc-150616083423-lva1-app6892/85/2-new-hw_features_cat_cod_etc-30-320.jpg)


































































































