This document discusses IPv4 and IPv6 addressing and routing. It covers topics such as:
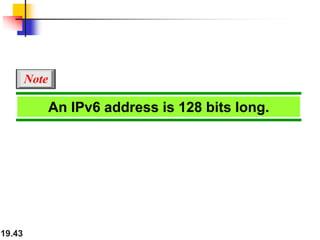
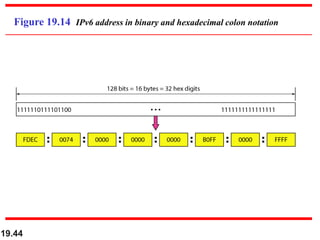
- IPv4 addresses are 32-bit and unique, while IPv6 addresses are 128-bit
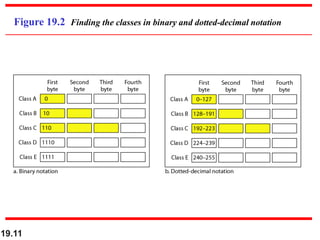
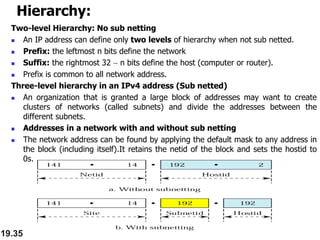
- Classful and classless addressing in IPv4, including network masks
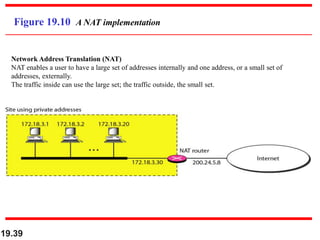
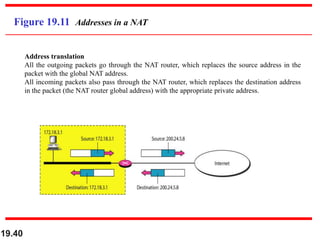
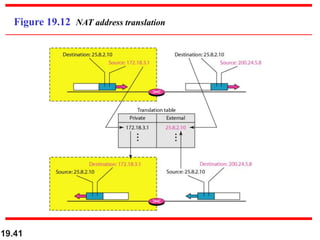
- Network address translation (NAT) allows private addresses to connect to the public internet
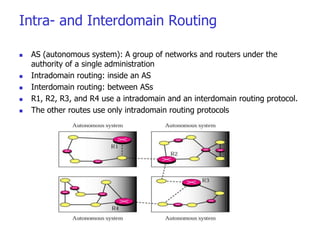
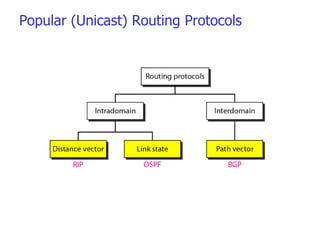
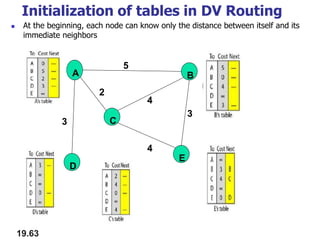
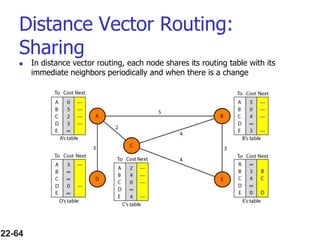
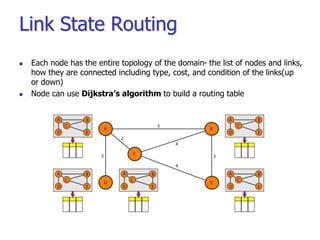
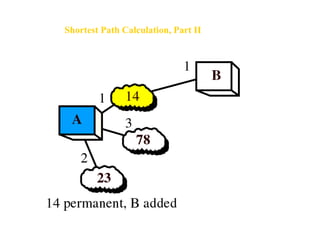
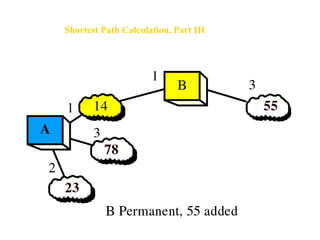
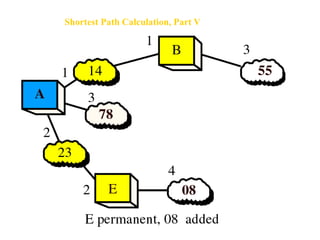
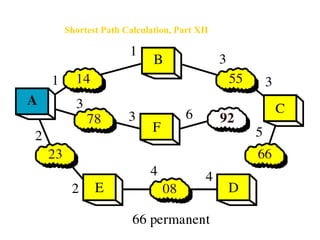
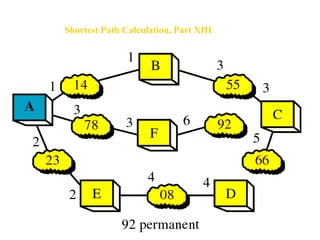
- Routing protocols like RIP, OSPF, and BGP are used for intradomain and interdomain routing based on metrics and shortest paths
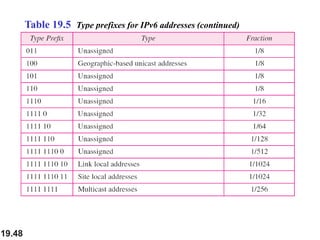
- IPv6 was developed to address the long-term address depletion problem in IPv4