Downloaded 40 times

















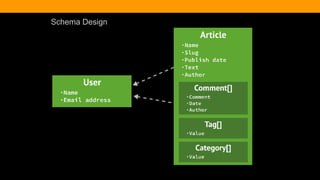




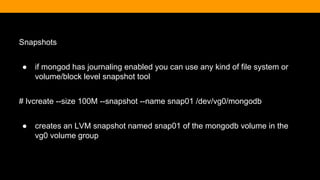
![Creating a Blog Post
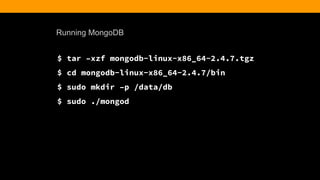
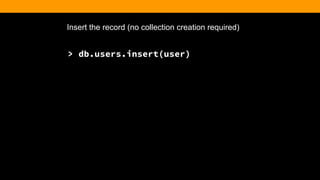
> db.article.insert({
title: ‘Hello World’,
body: ‘This is my first blog post’,
date: new Date(‘2013-06-20’),
username: kcearns,
tags: [‘adventure’, ‘mongodb’],
comments: [ ]
})](https://image.slidesharecdn.com/fitc-spotlightonmean-140331134751-phpapp02/85/MongoDB-Advantages-of-an-Open-Source-NoSQL-Database-33-320.jpg)
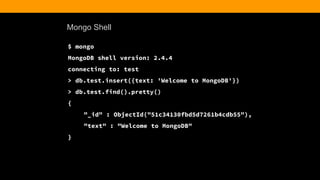
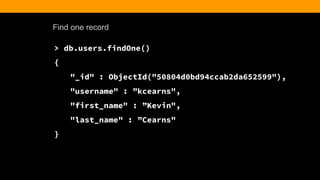
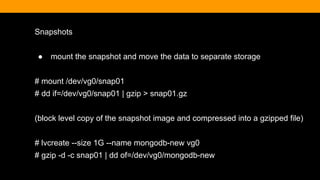
![Finding the Post
> db.article.find().pretty()
{
"_id" : ObjectId("51c3bafafbd5d7261b4cdb5a"),
"title" : "Hello World",
"body" : "This is my first blog post",
"date" : ISODate("2013-10-20T00:00:00Z"),
"username" : "kcearns",
"tags" : [
"adventure",
"mongodb"
],
"comments" : [ ]
}](https://image.slidesharecdn.com/fitc-spotlightonmean-140331134751-phpapp02/85/MongoDB-Advantages-of-an-Open-Source-NoSQL-Database-34-320.jpg)
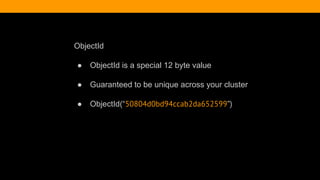
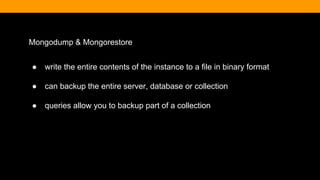
![Querying An Array
> db.article.find({tags:'adventure'}).pretty()
{
"_id" : ObjectId("51c3bcddfbd5d7261b4cdb5b"),
"title" : "Hello World",
"body" : "This is my first blog post",
"date" : ISODate("2013-10-20T00:00:00Z"),
"username" : "kcearns",
"tags" : [
"adventure",
"mongodb"
],
"comments" : [ ]
}](https://image.slidesharecdn.com/fitc-spotlightonmean-140331134751-phpapp02/85/MongoDB-Advantages-of-an-Open-Source-NoSQL-Database-35-320.jpg)









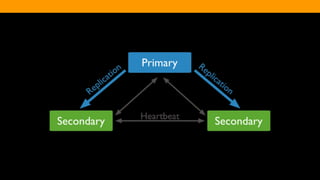
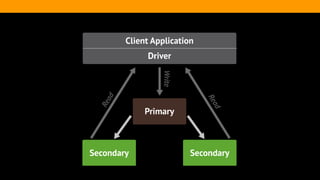
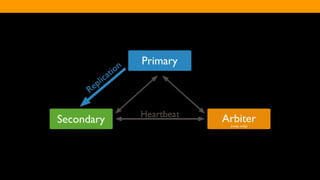

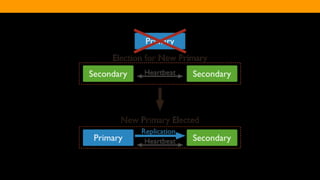

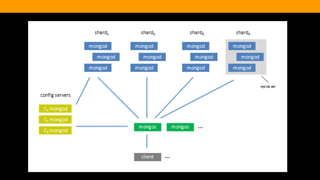


























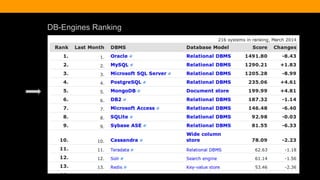
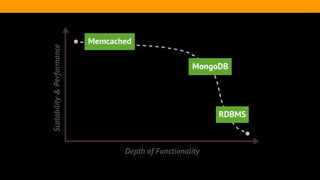
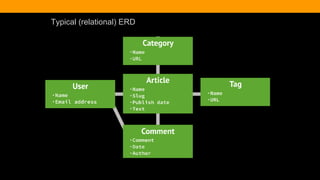
The document outlines the advantages and functionality of MongoDB, an open-source NoSQL database developed initially in 2007 and made public in 2009. It emphasizes MongoDB's high performance, flexible schema, and support for various programming languages, highlighting key features like document storage, ad hoc queries, and replication. Additionally, it offers best practices for setup, configuration, and operations, focusing on performance monitoring, backup methods, and diagnostics tools.





































































![How Big Brands are Taking Your Traffic in Alberta [Data Inside].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/howbigbrandsaretakingyourtrafficinalbertadatainside-260123180142-42d276f3-thumbnail.jpg?width=640&height=640&fit=bounds)





