Download as PDF, PPTX













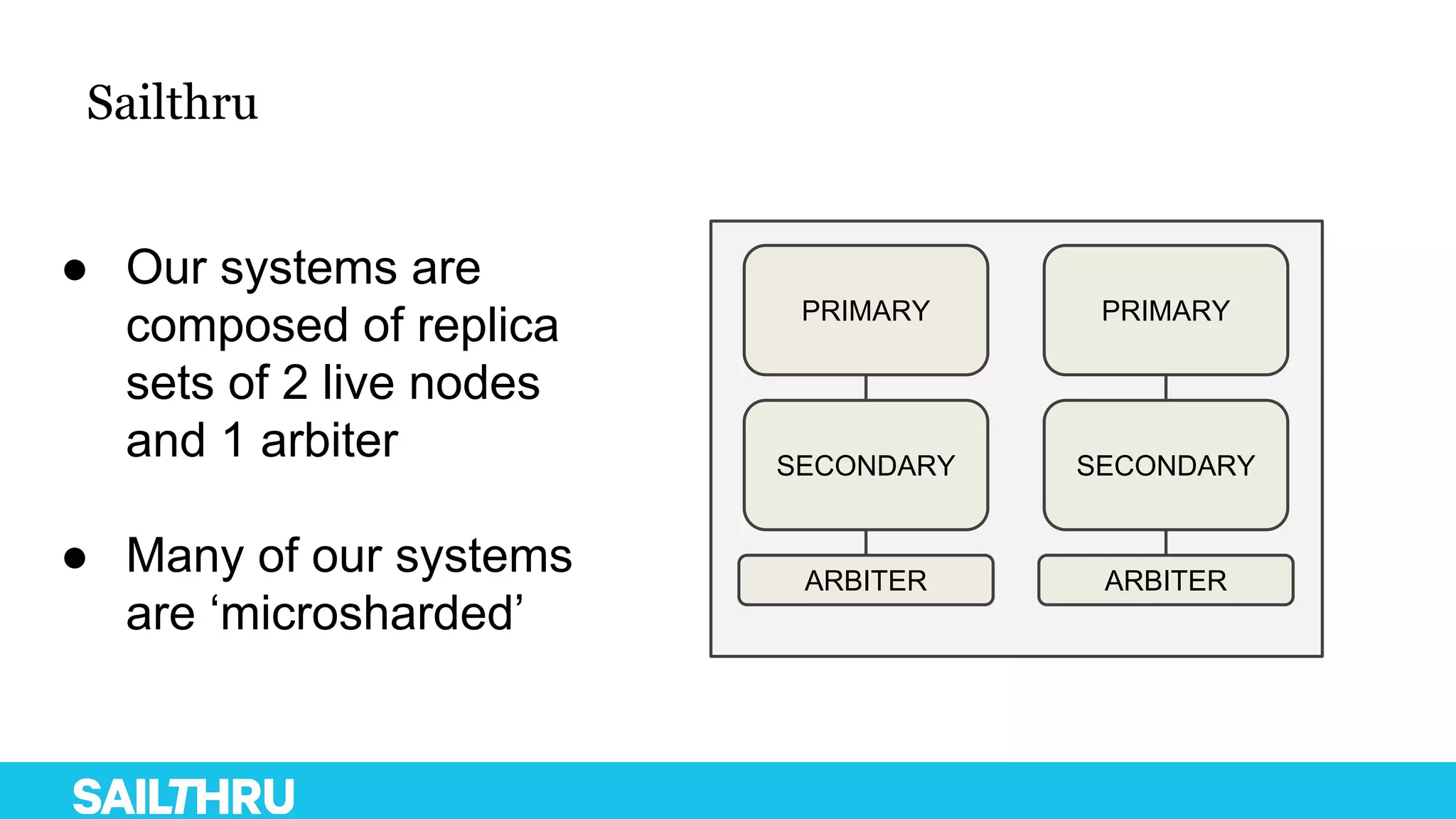
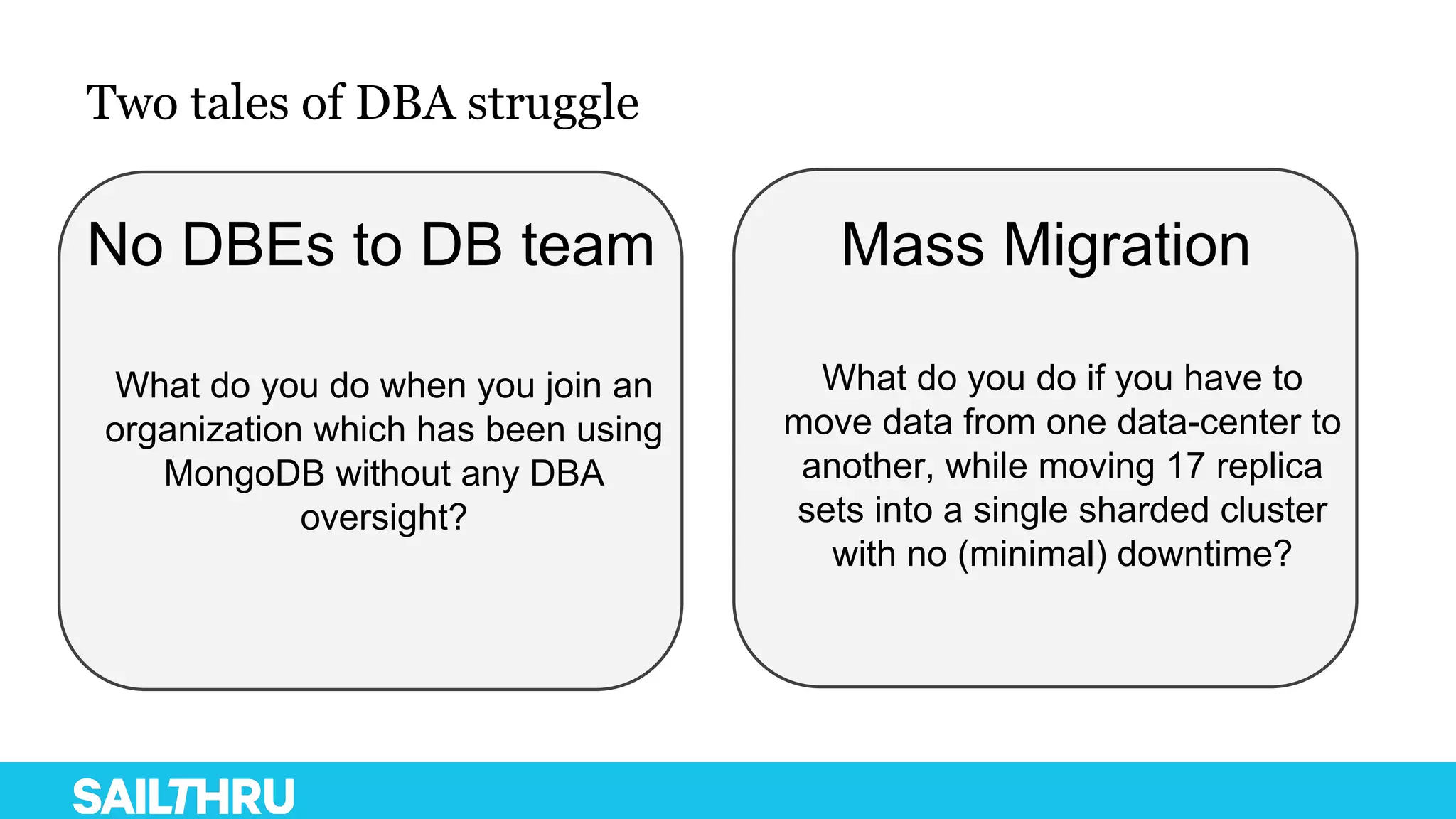

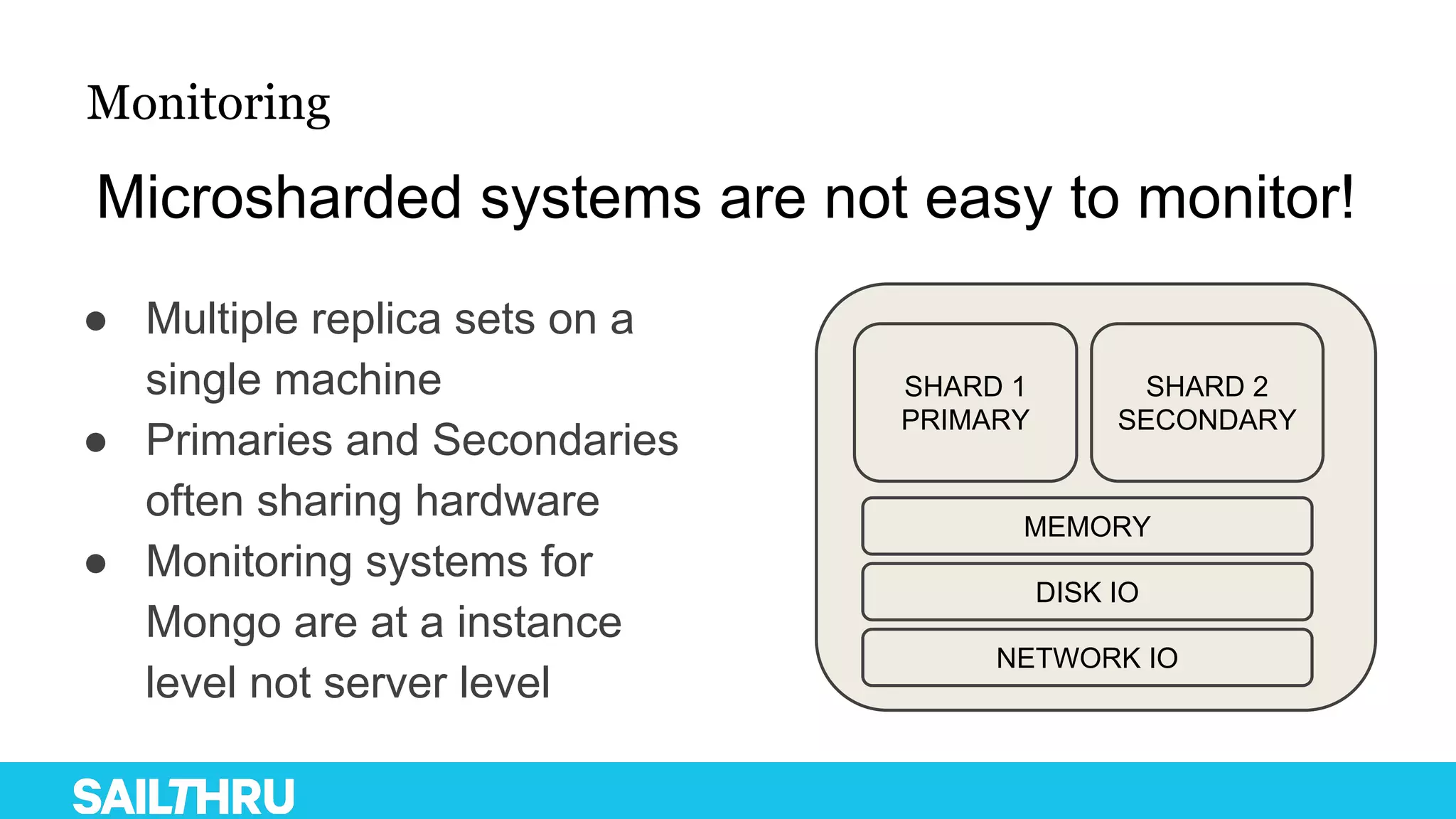

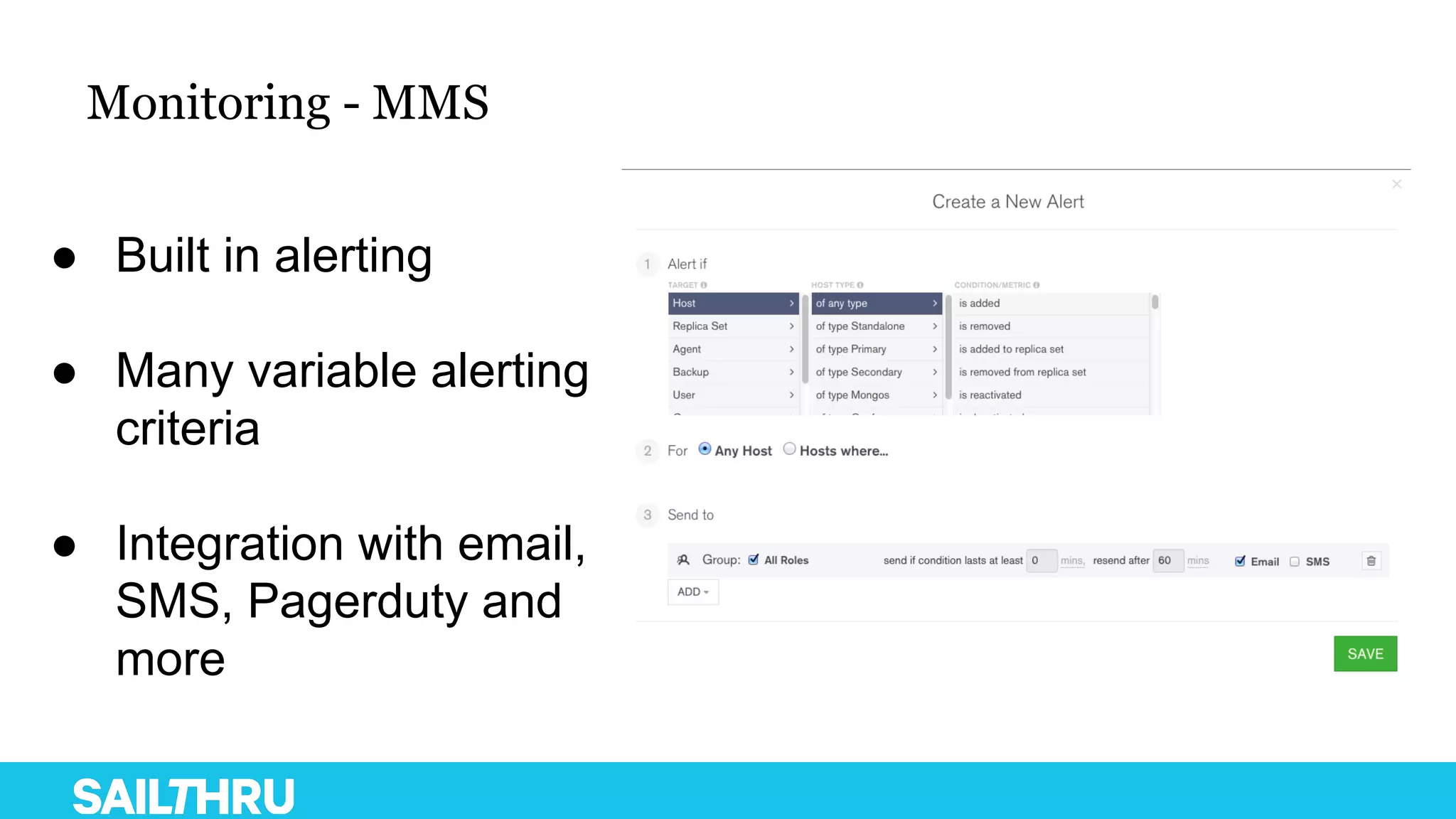
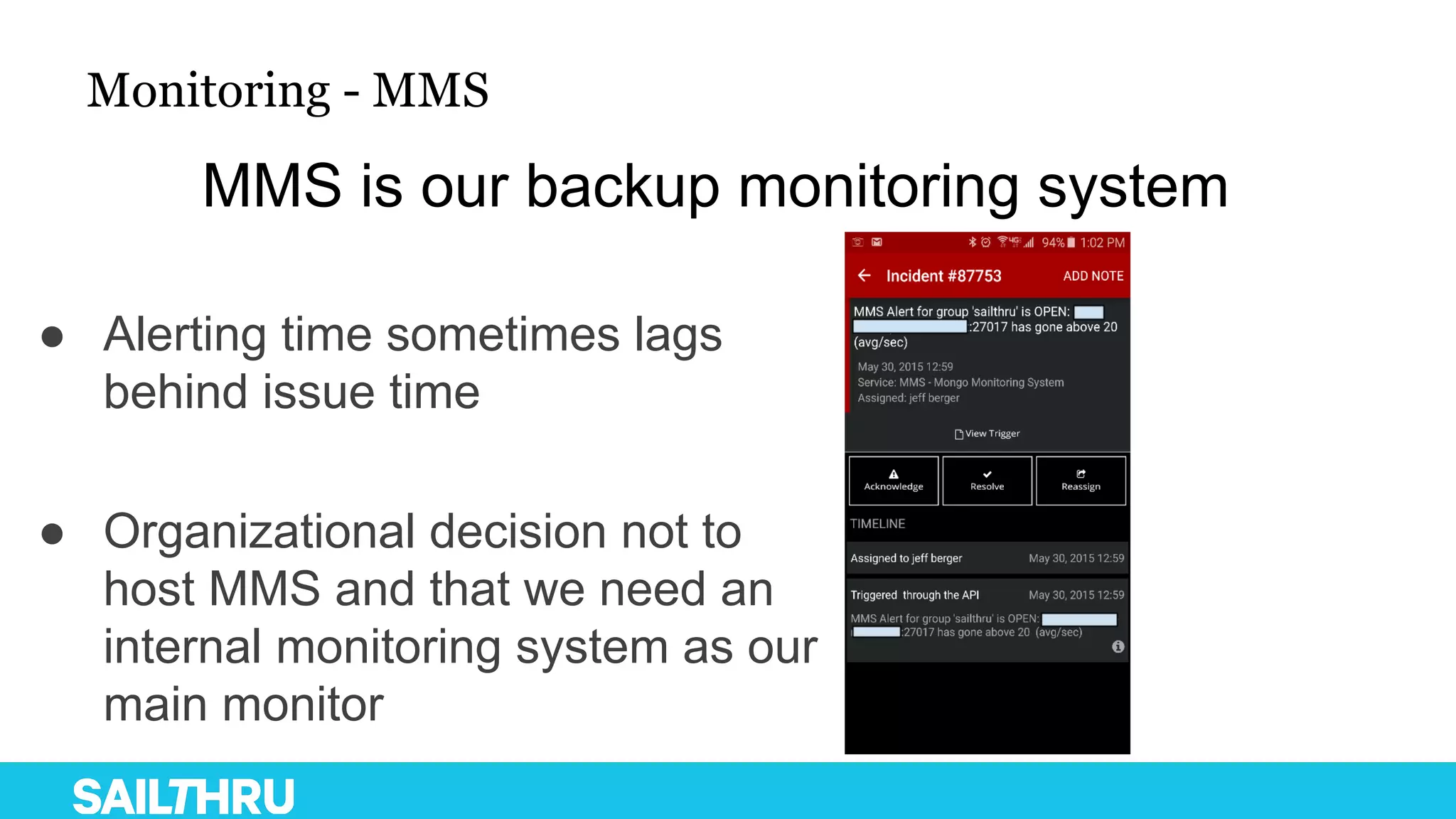



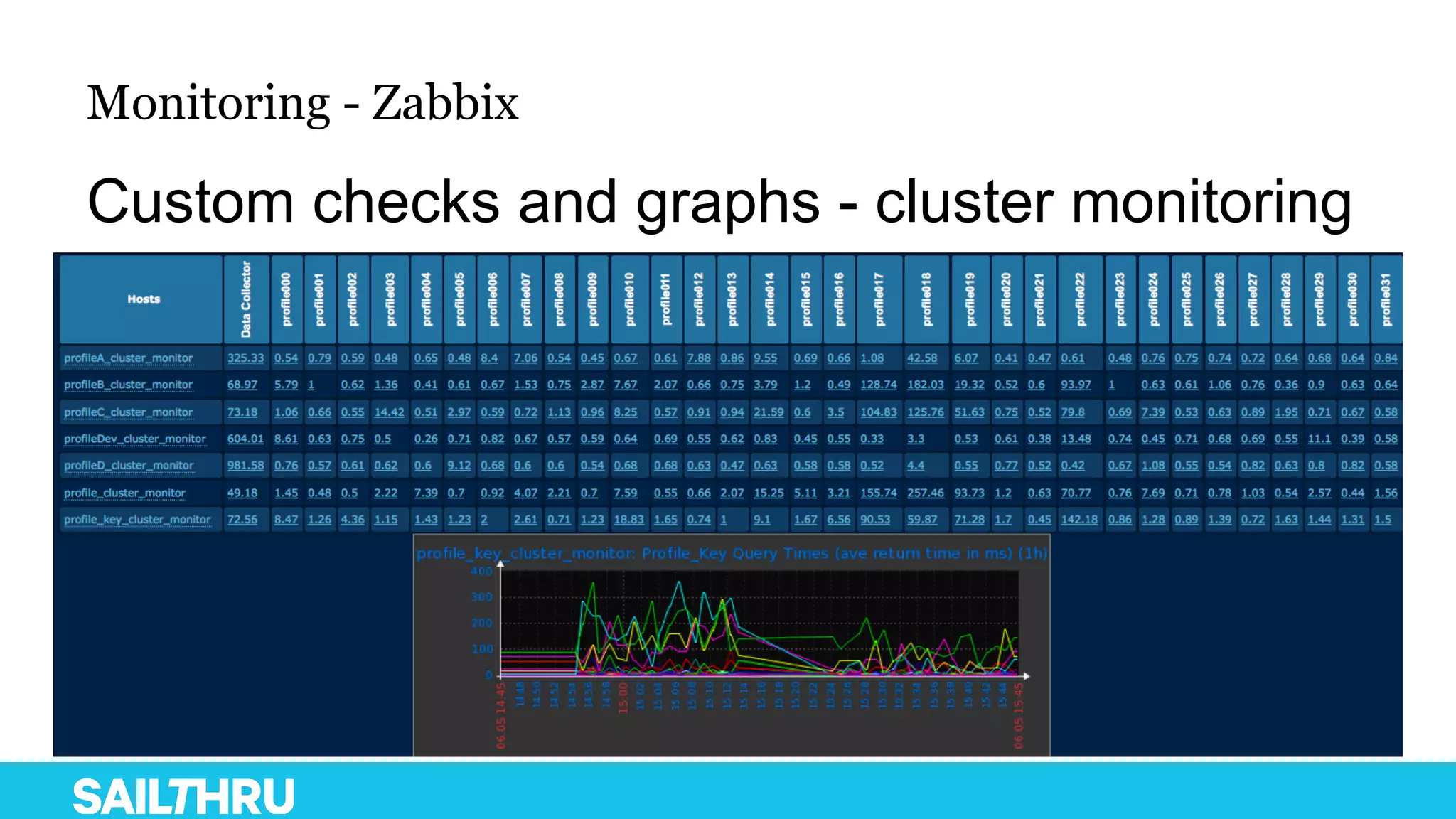




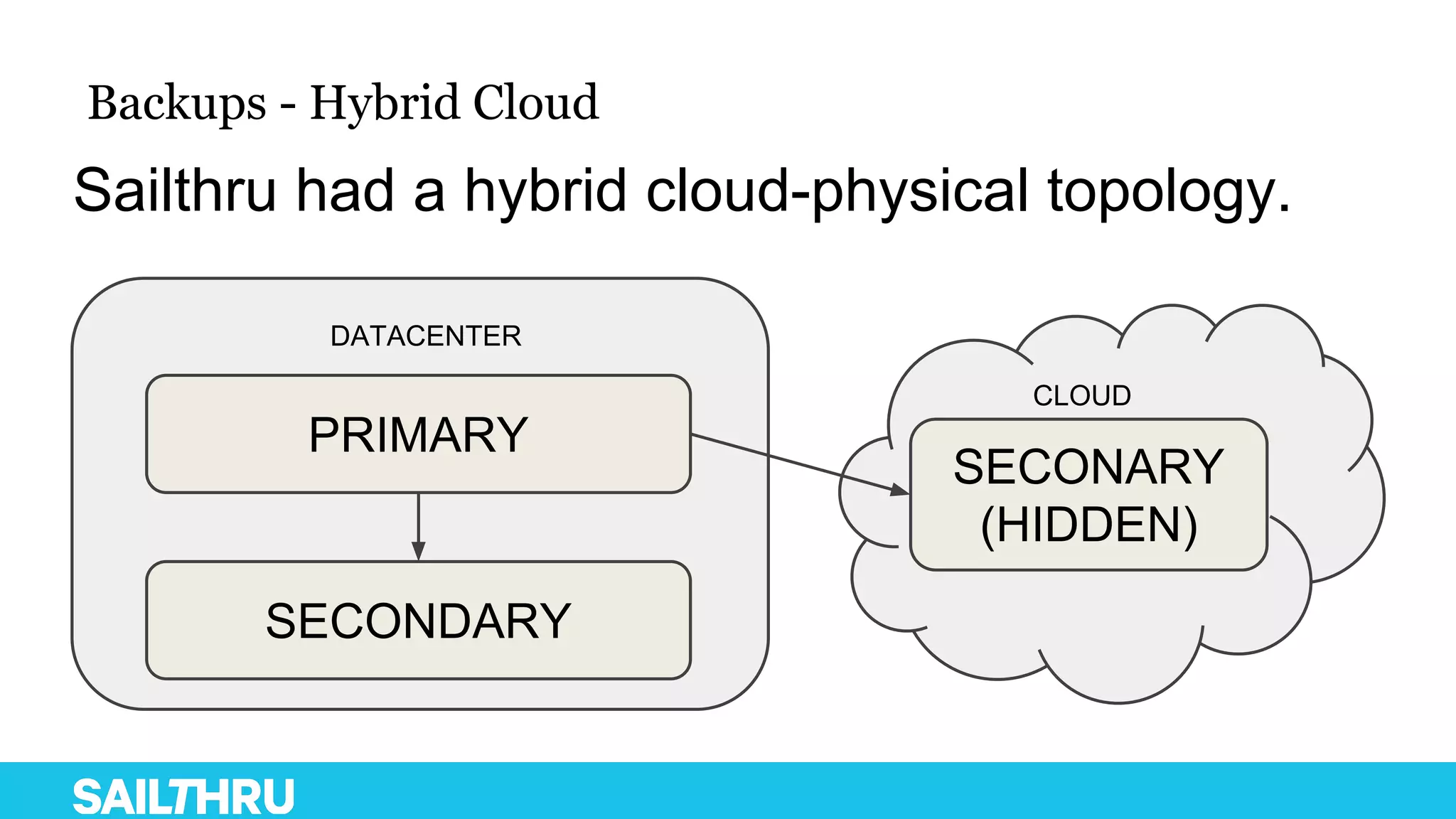

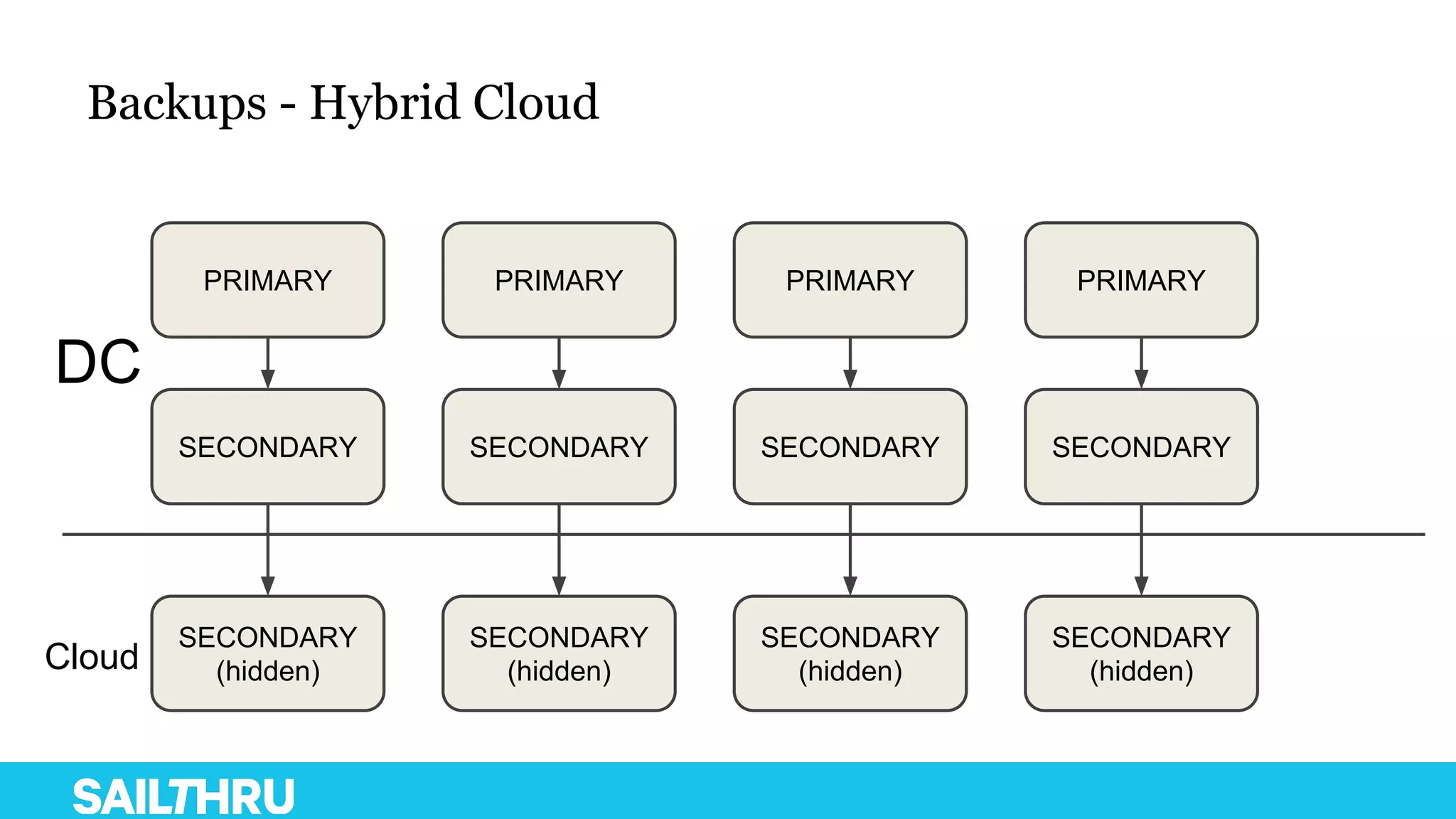
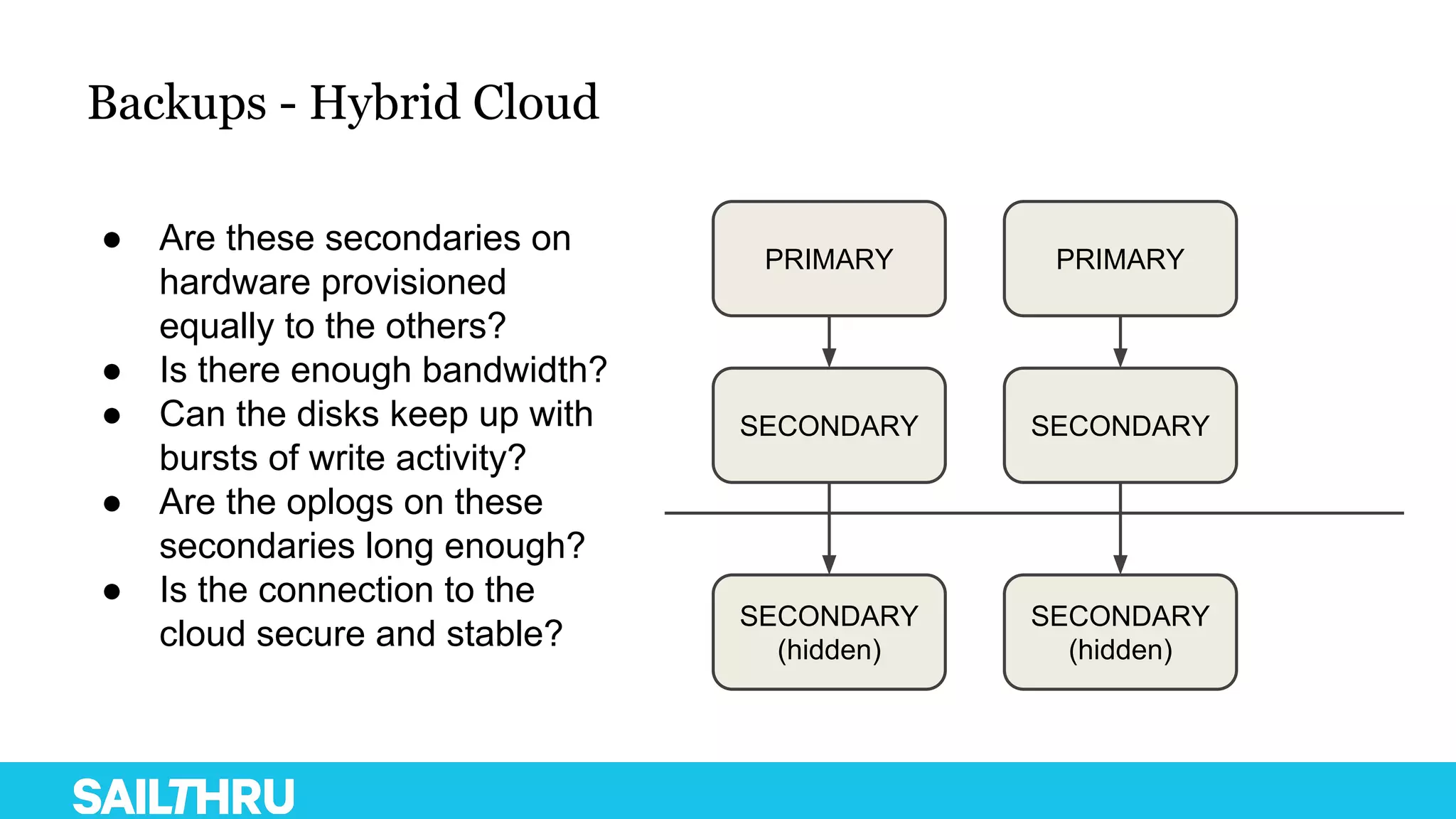




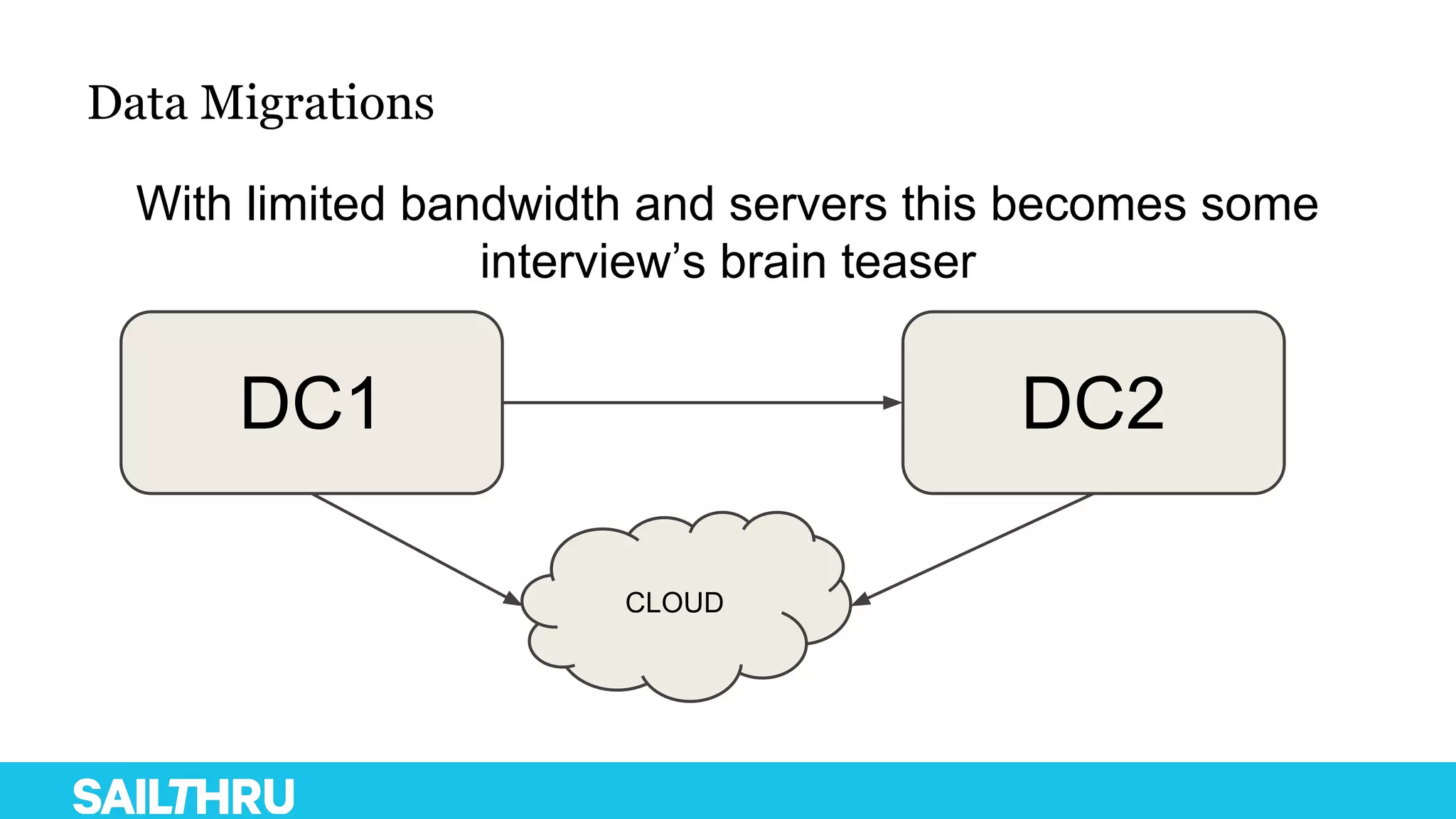
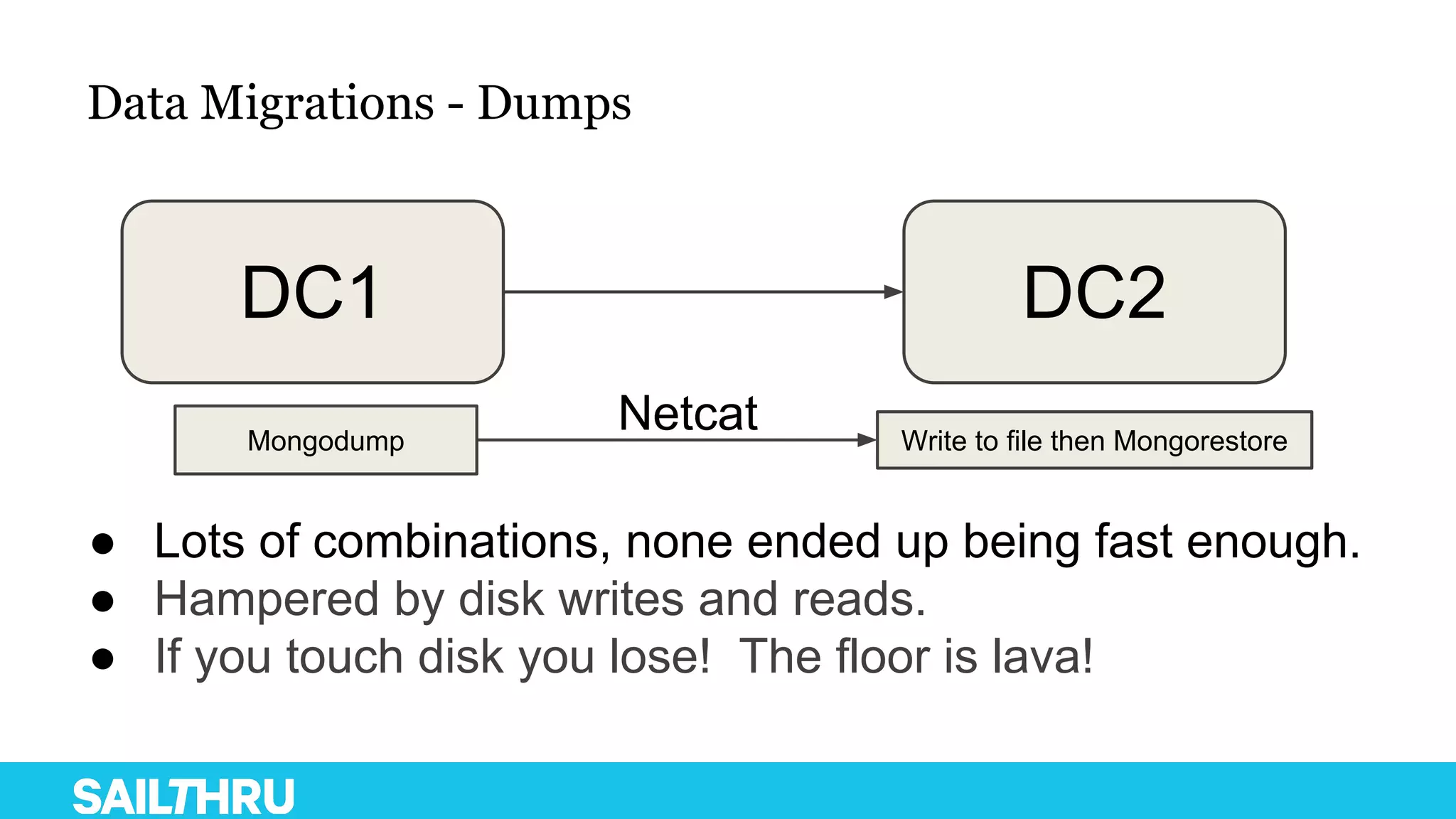

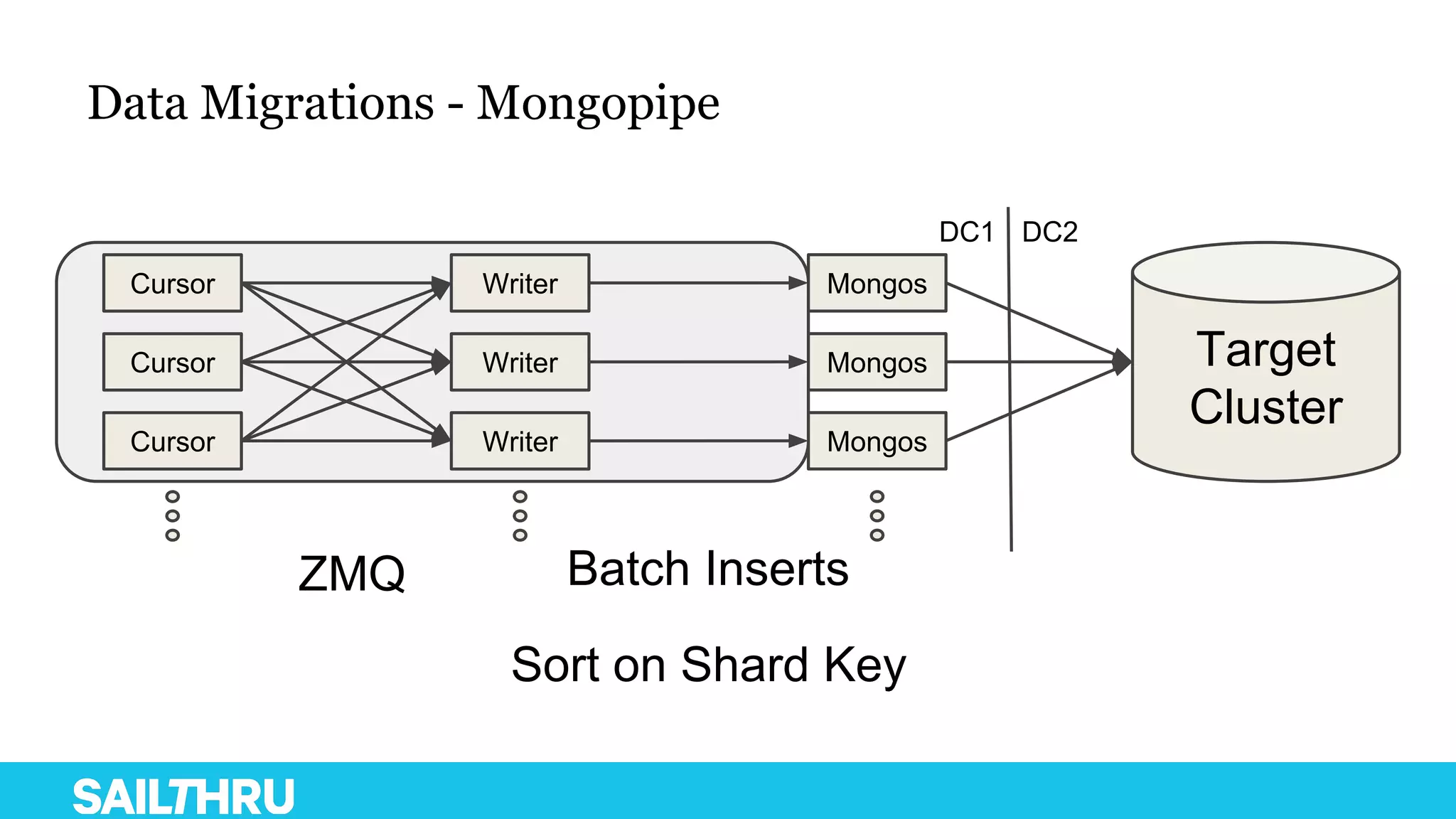
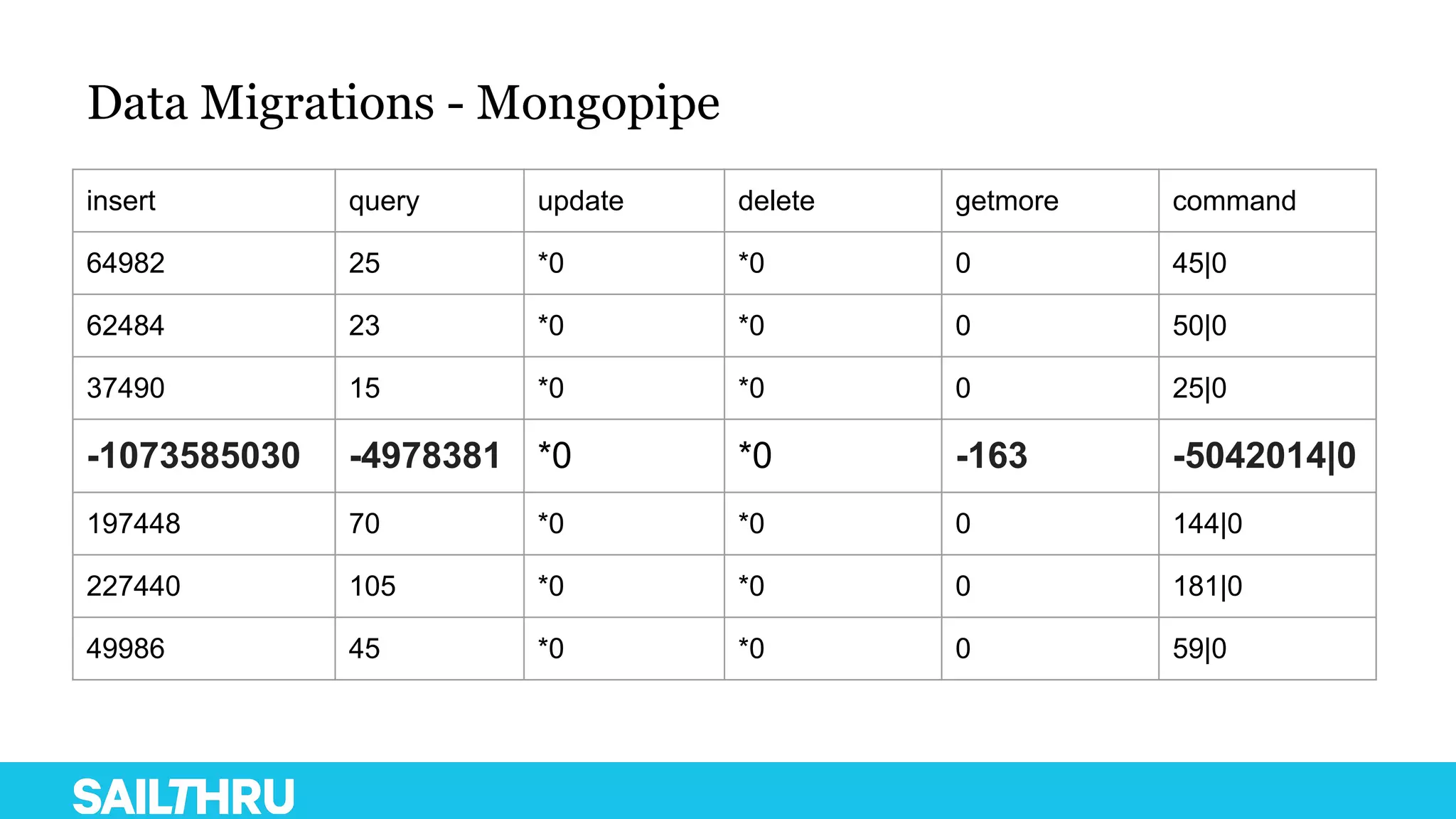

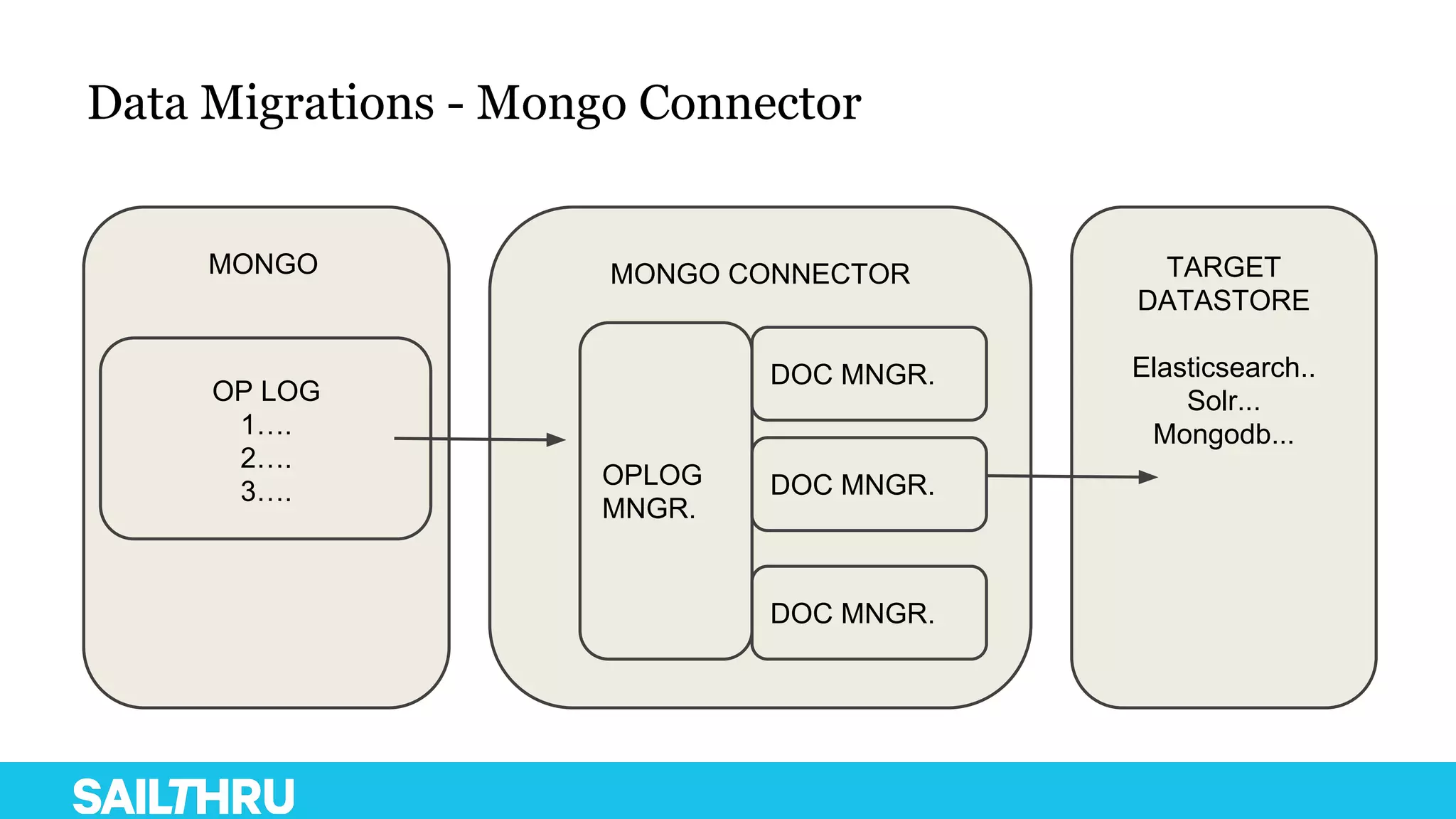
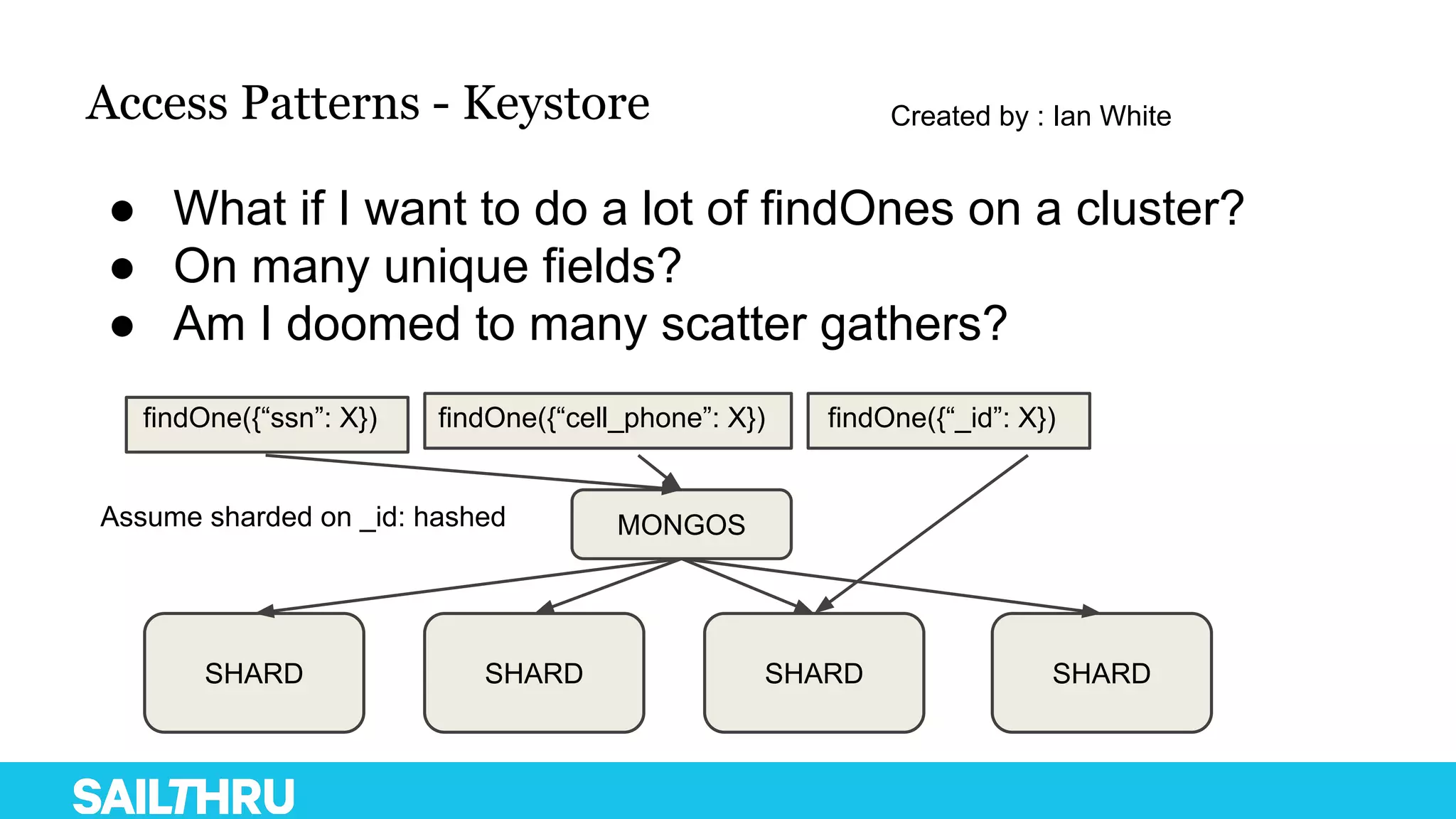
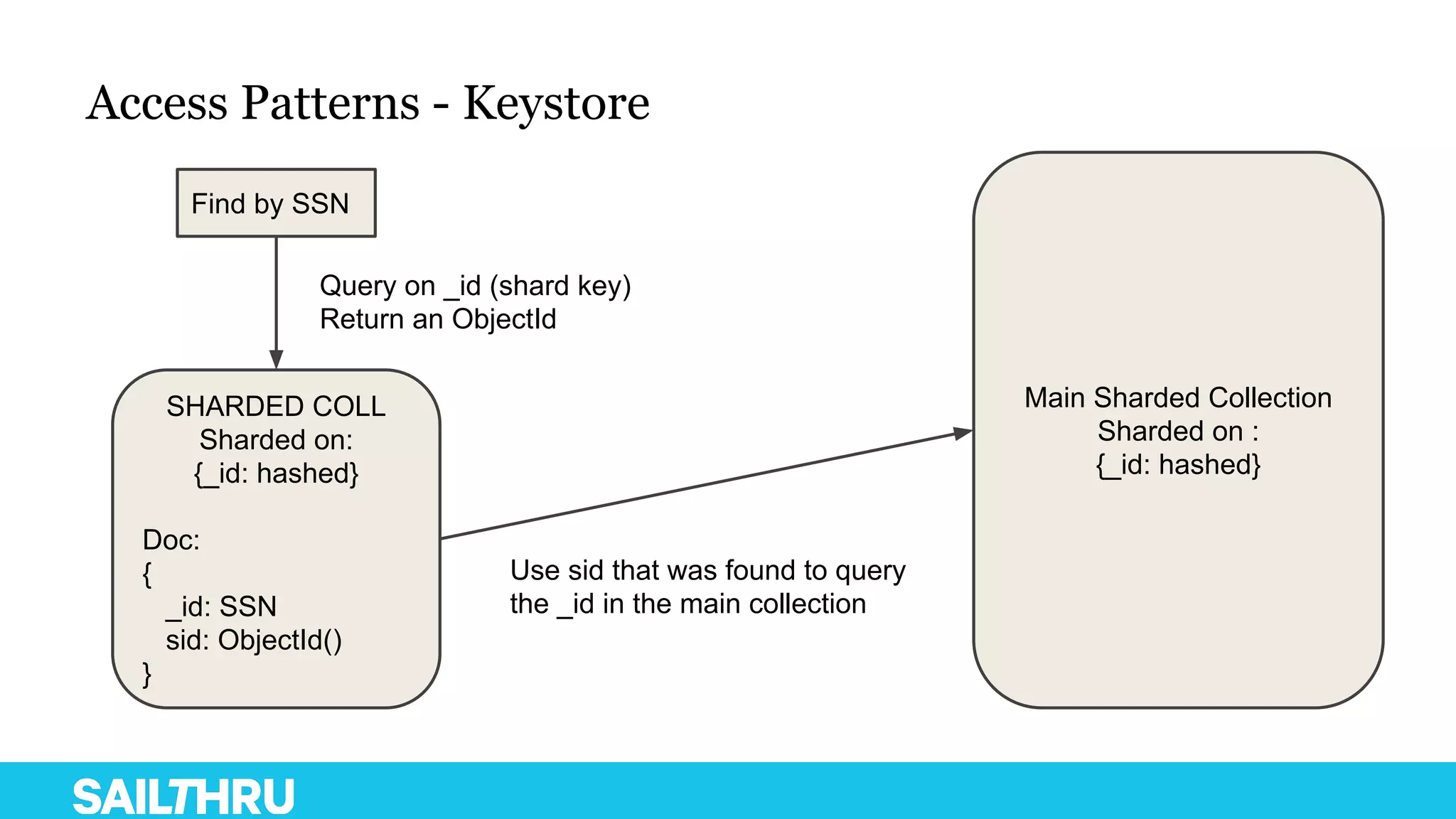


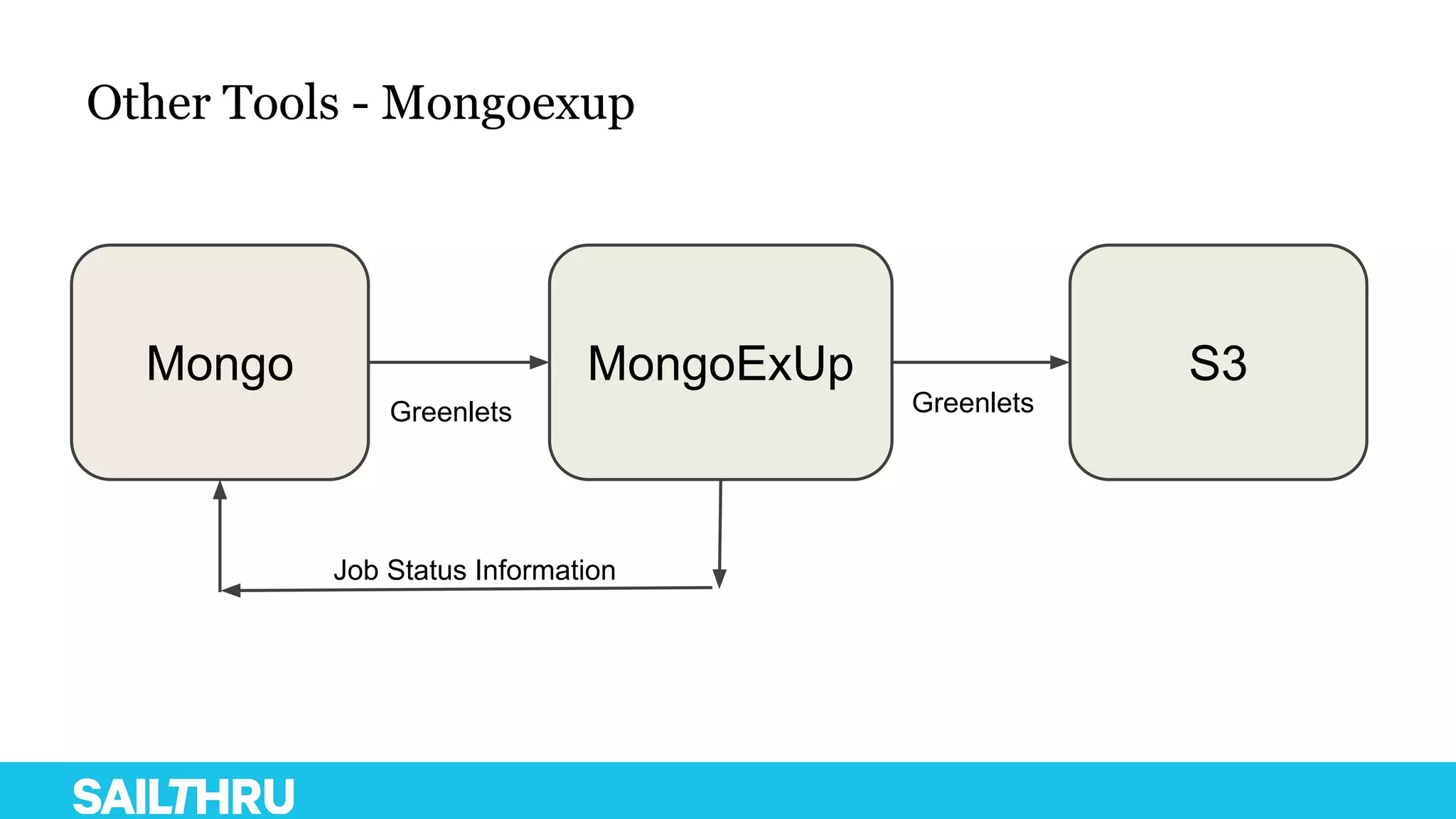


The document discusses advanced database administration and monitoring techniques, focusing on a migration to a sharded cluster and enhancements in monitoring using tools like MMS and Zabbix. It details Sailthru's experiences with MongoDB management, including challenges faced during data center migrations, backup strategies, and the development of tools for effective monitoring and data handling. Additionally, it highlights the importance of automation and open-source initiatives to improve operational efficiency in database management.





















































![MongoDB .local San Francisco 2020: Powering the new age data demands [Infosys]](https://cdn.slidesharecdn.com/ss_thumbnails/315pminfosysfinalsfoversionvocalpart1-200120221508-thumbnail.jpg?width=640&height=640&fit=bounds)













