Downloaded 227 times

















![FULLTEXT PROPERTY SCOPED SEARCH
New Search Filter for Document Properties
CONTAINS (PROPERTY ( { column_name }, 'property_name' ), „contains_search_condition‟ )
• Setup once per database instance to load the office filters
exec sp_fulltext_service 'load_os_resources',1
go
exec sp_fulltext_service 'restart_all_fdhosts'
go
• Create a property list
CREATE SEARCH PROPERTY LIST p1;
• Add properties to be extracted
ALTER SEARCH PROPERTY LIST [p1] ADD N'System.Author' WITH
(PROPERTY_SET_GUID = 'f29f85e0-4ff9-1068-ab91-08002b27b3d9',
PROPERTY_INT_ID = 4, PROPERTY_DESCRIPTION = N'System.Author');
• Create/Alter Fulltext index to specify property list to be extracted
ALTER FULLTEXT INDEX ON fttable... SET SEARCH PROPERTY LIST = [p1];
• Query for properties
SELECT * FROM fttable WHERE CONTAINS(PROPERTY(ftcol, 'System.Author'), 'fernlope');](https://image.slidesharecdn.com/filetablesemanticsearchsql2012mrys-120303173259-phpapp01/85/FileTable-and-Semantic-Search-in-SQL-Server-2012-24-320.jpg)



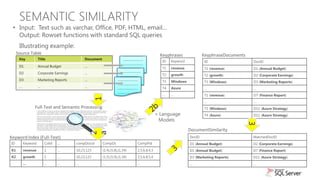





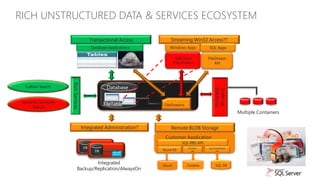
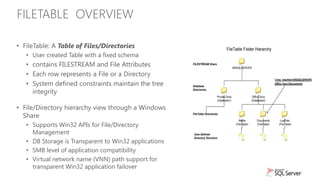
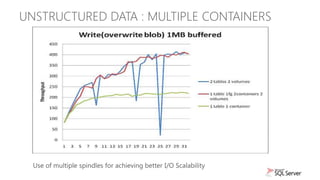
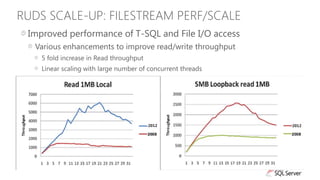
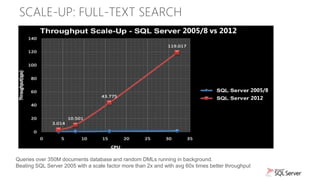
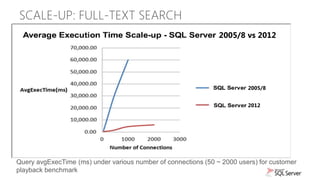
The document discusses new capabilities for managing and analyzing unstructured data in SQL Server 2012. Key points include: - SQL Server 2012 introduces FileTable which allows storing and accessing files and folders through standard file system APIs while storing the file data and metadata in SQL Server tables. - Full-text search is improved with better performance and ability to scale to hundreds of millions of documents. New capabilities like property search and customizable "near" operator are also introduced. - Semantic search allows extracting keywords and identifying related content based on statistical analysis, without requiring ontologies. It provides insight into unstructured text content.










































































































