Download as PDF, PPTX


















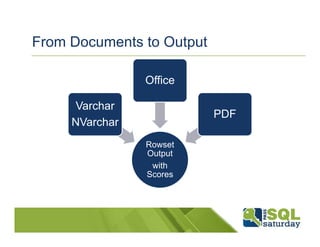

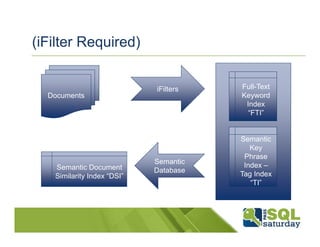






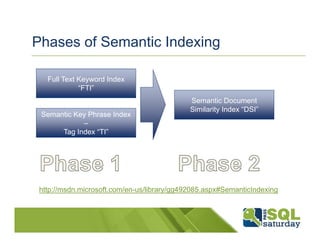










SQL Server 2012 introduces new semantic search capabilities that leverage its existing full text search. Semantic search builds semantic indexes in two phases, first creating a tag index and then a document similarity index. It can currently support indexing documents in 15 languages. The presentation provides details on how semantic search works and its performance, which scales linearly with document collection size. It also demonstrates how semantic search can help reduce the challenges of building applications with both structured and unstructured data.





































































































