
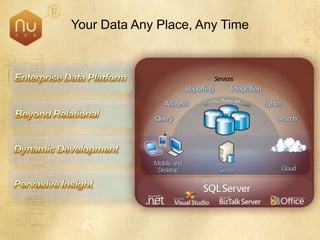
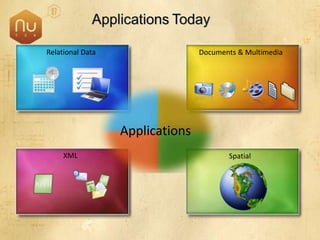
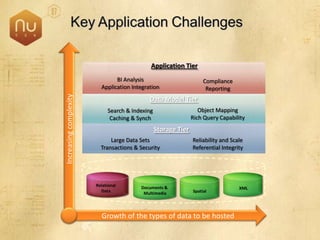











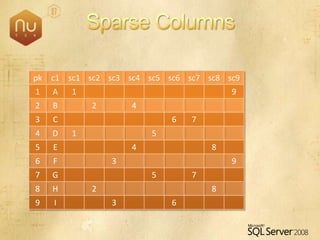
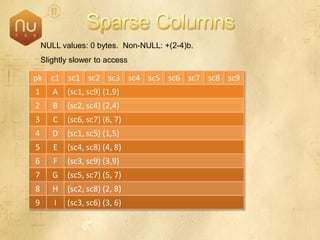





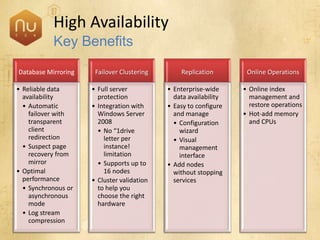
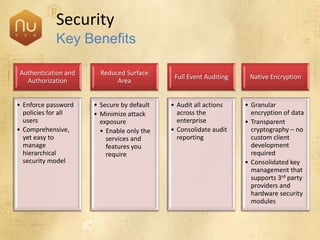
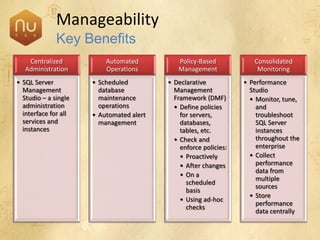
































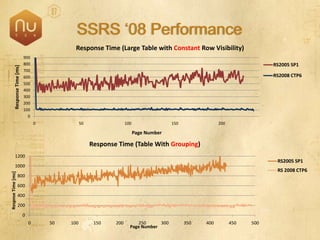
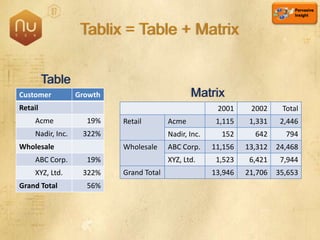
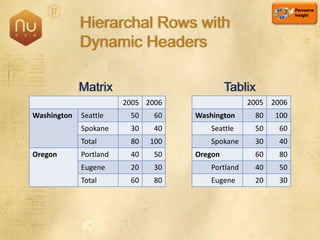
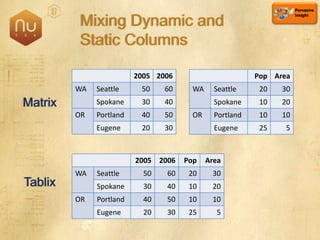
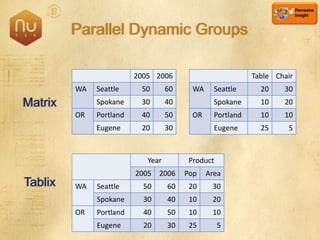
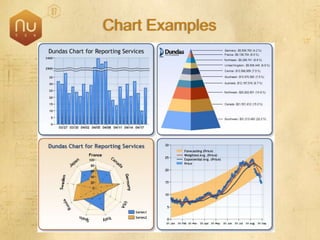


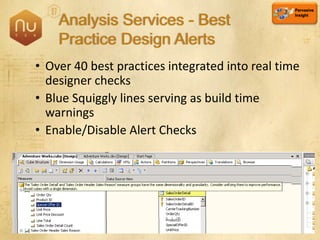





The document discusses new features in SQL Server 2008 that improve data storage, analytics, performance, scalability, high availability, security, and manageability. Key highlights include: - Storing and querying multiple data types like relational, documents, XML, and spatial data more efficiently - Enhancements for analytics, reporting, and mixed queries using features like column sets and sparse columns - Increased scalability through features such as resource governor, memory management improvements, and query optimization - High availability options like database mirroring, failover clustering, and replication - Security enhancements including encryption, auditing, and reduced attack surfaces - Simplified administration using tools such as SQL Server Management











































































































