Download as PDF, PPTX











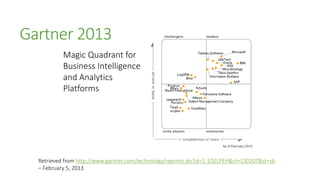
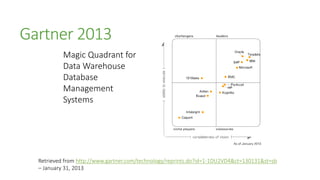



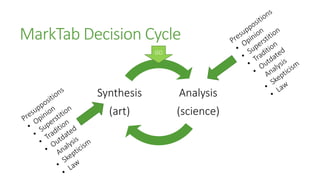











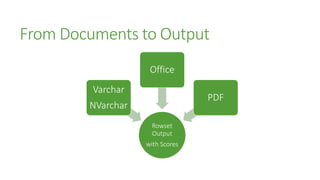
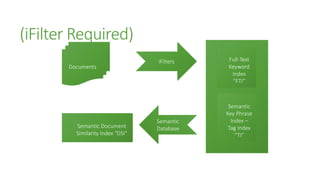

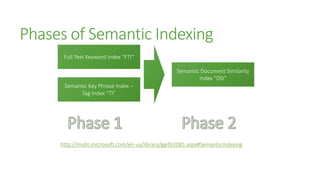




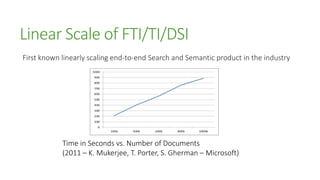








The document outlines the advancements in SQL Server 2012 related to semantic search and text mining, highlighting Microsoft's competitive edge in the data mining landscape. It details the historical context of Microsoft's development of semantic search technology and provides insights into the performance enhancements available in SQL Server 2012 for text mining. Additionally, it emphasizes the integration of full-text search capabilities and the significance of combining both quantitative and qualitative research methods in the mining of textual data.




































































































