

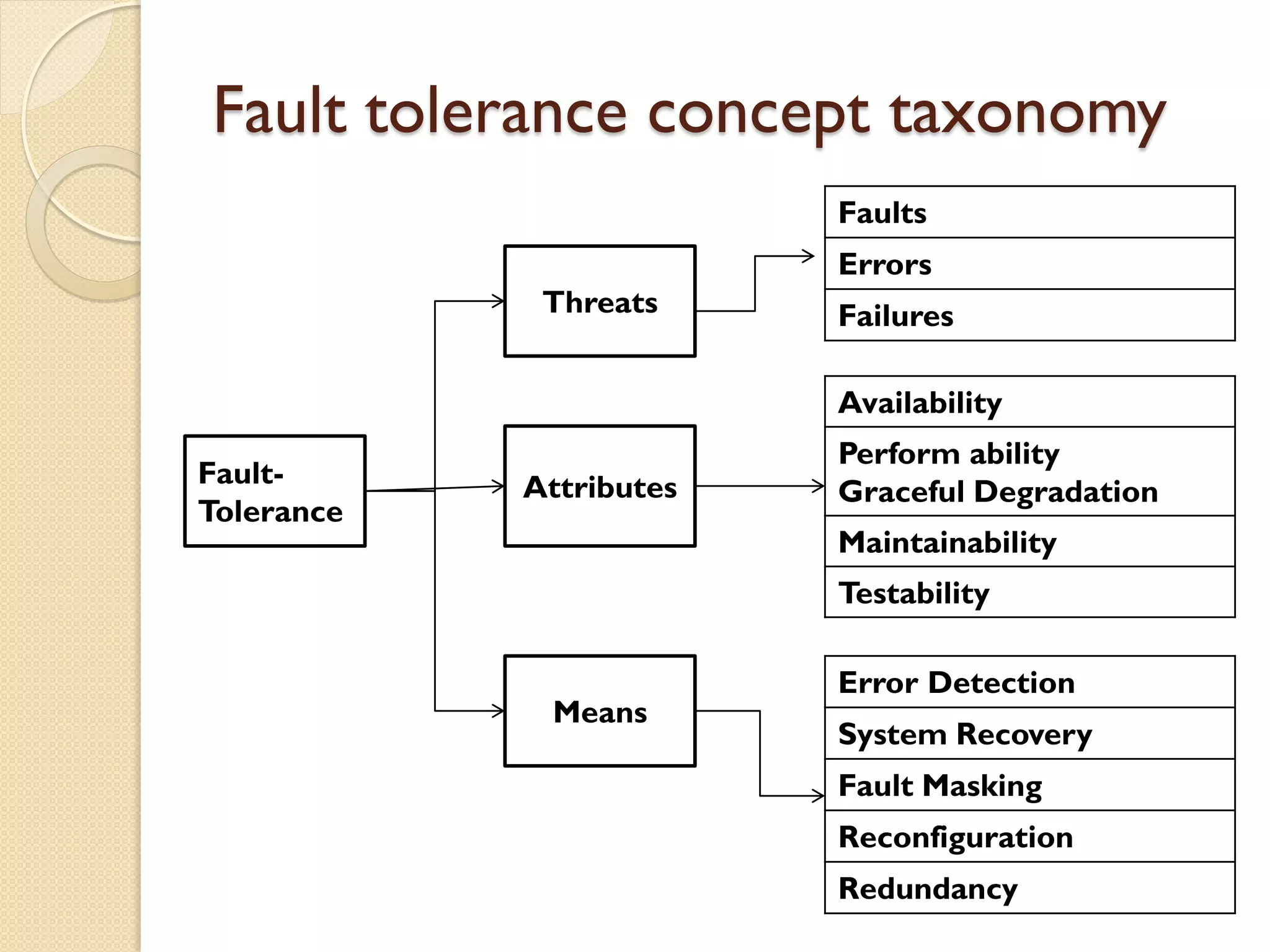




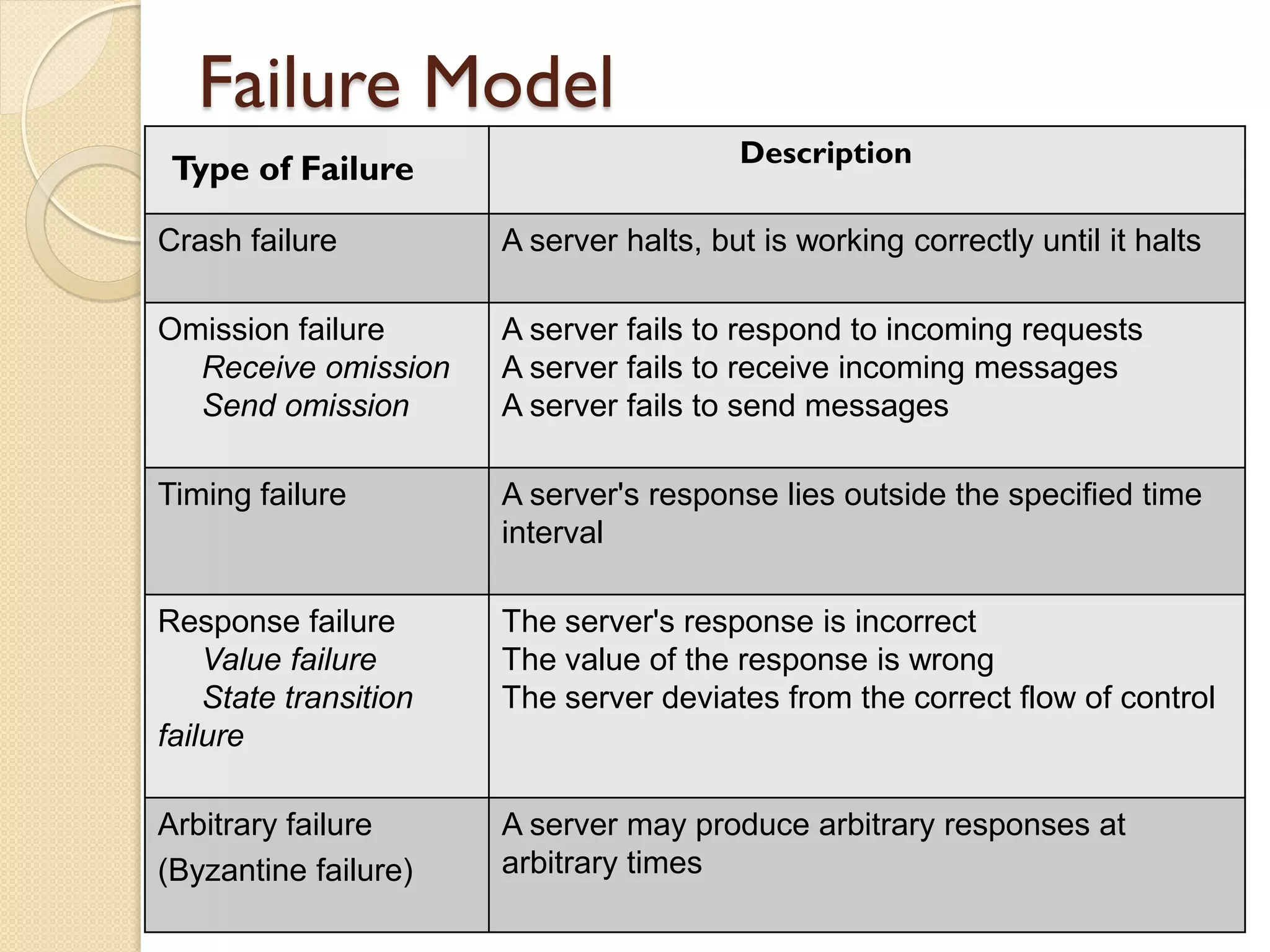










This document discusses fault tolerance in computing systems. It defines fault tolerance as building systems that can continue operating satisfactorily even in the presence of faults. It describes different types of faults like transient, intermittent, and permanent hardware faults. It also discusses concepts like errors, failures, fault taxonomy, attributes of fault tolerance like availability and reliability. It explains various techniques used for fault tolerance like error detection, system recovery, fault masking, and redundancy.

































































































