Downloaded 17 times


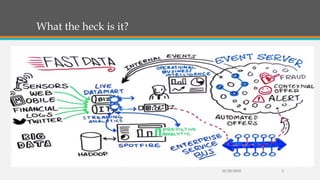



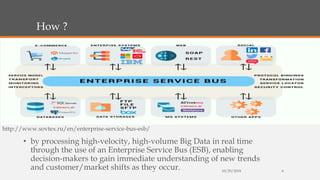
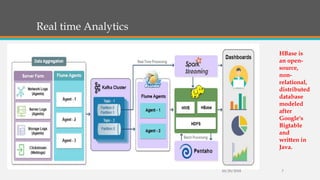










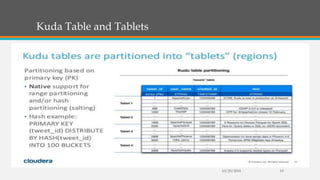

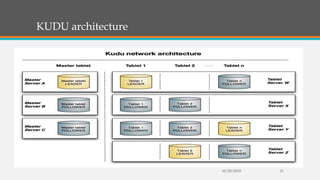



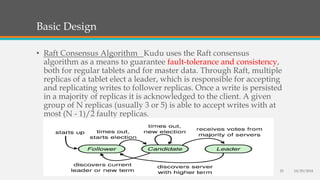





















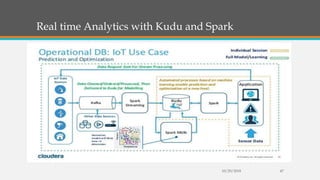
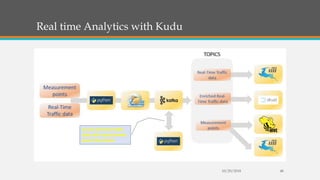
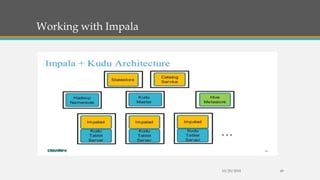
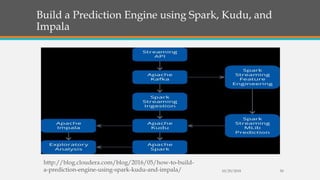


Fast Analytics (FA) uses an Enterprise Service Bus (ESB) to process high volumes of big data in real time, enabling decision makers to understand new trends and shifts as they occur. FA delivers analytics at decision-making speeds through technologies like Apache Kudu, which provides low latency random access and efficient analytical queries on columnar data. Kudu uses a log-structured storage approach and Raft consensus algorithm to replicate data across nodes for reliability and high availability.












































































