Download as PDF, PPTX






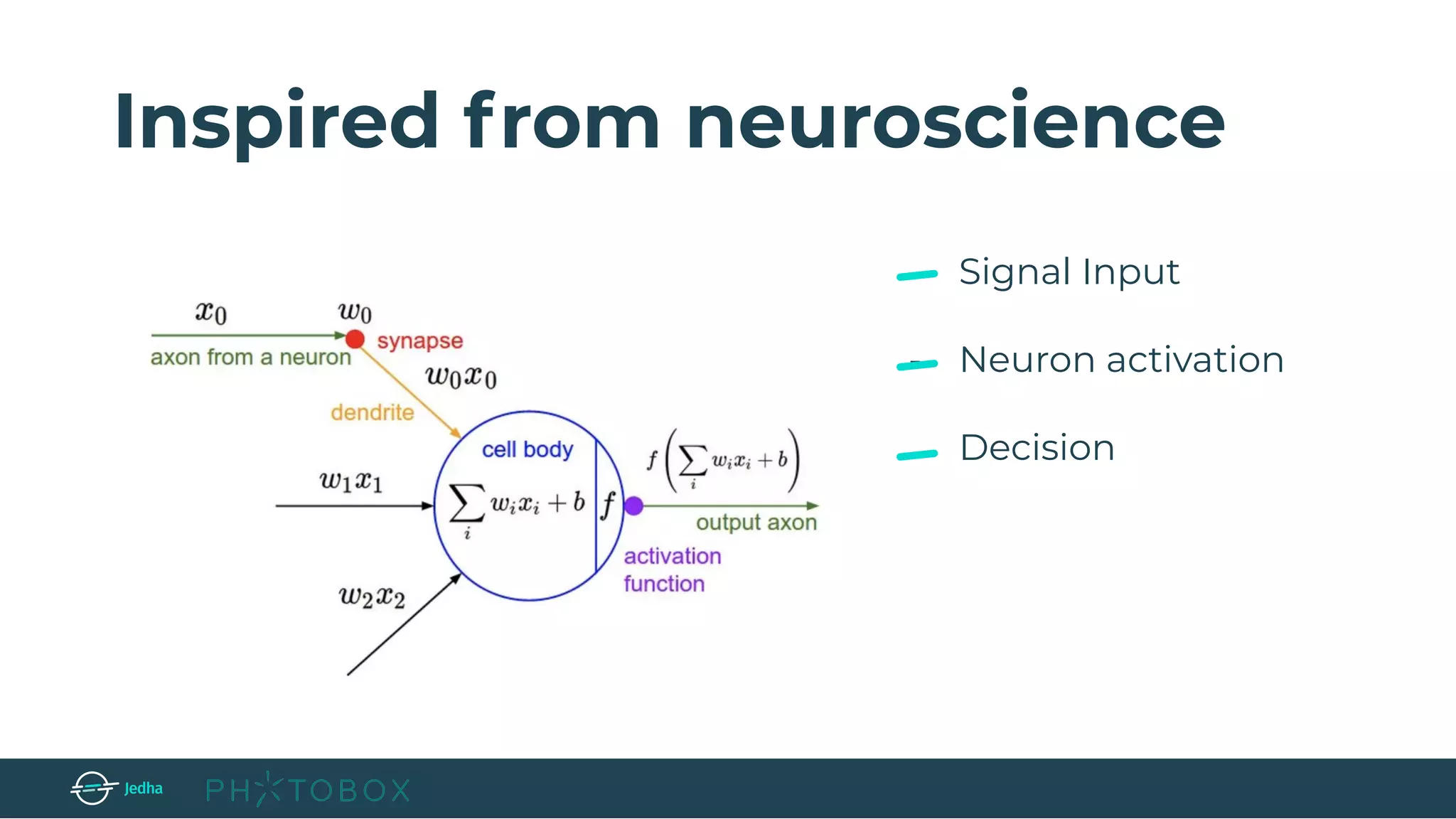

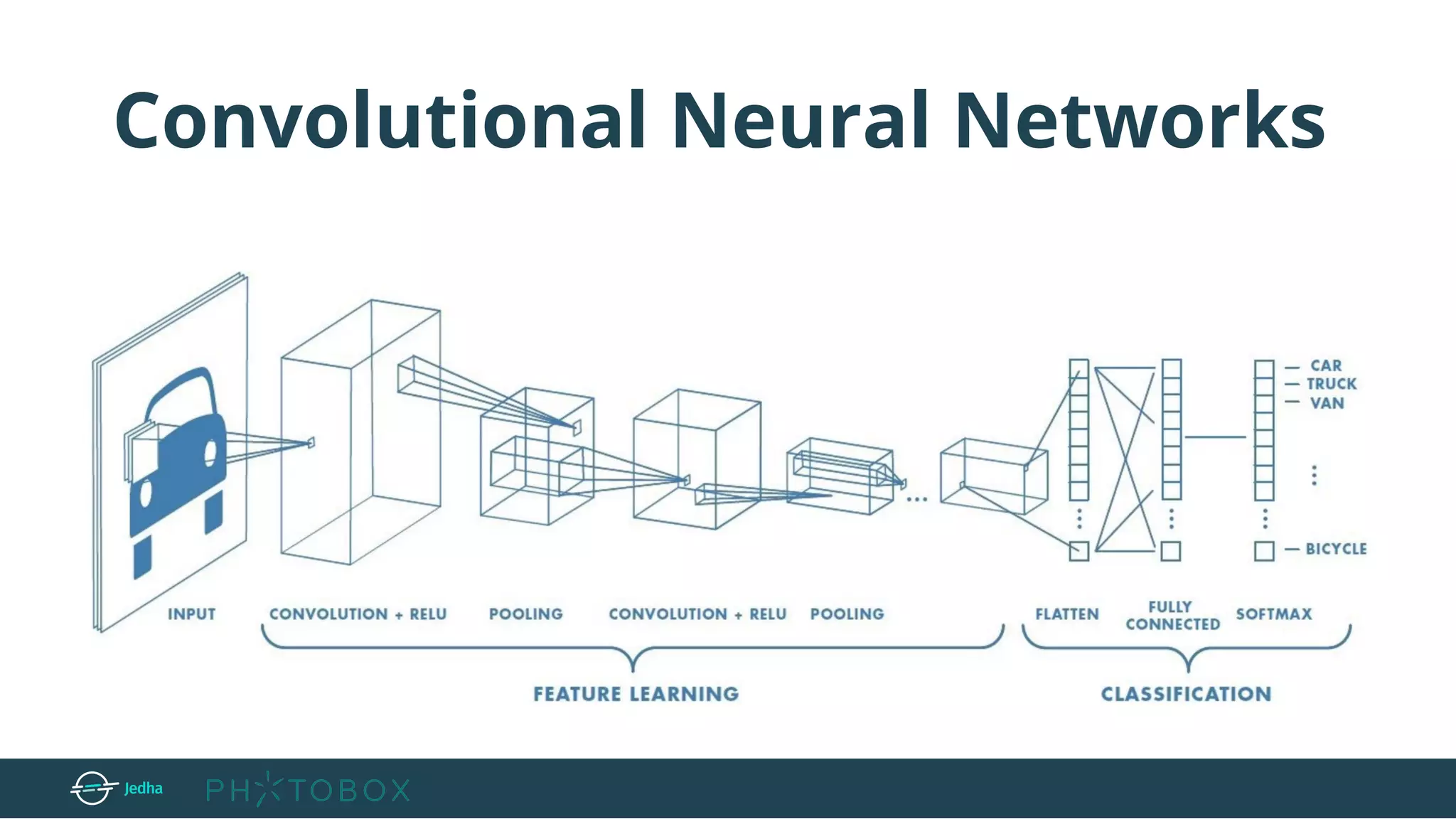
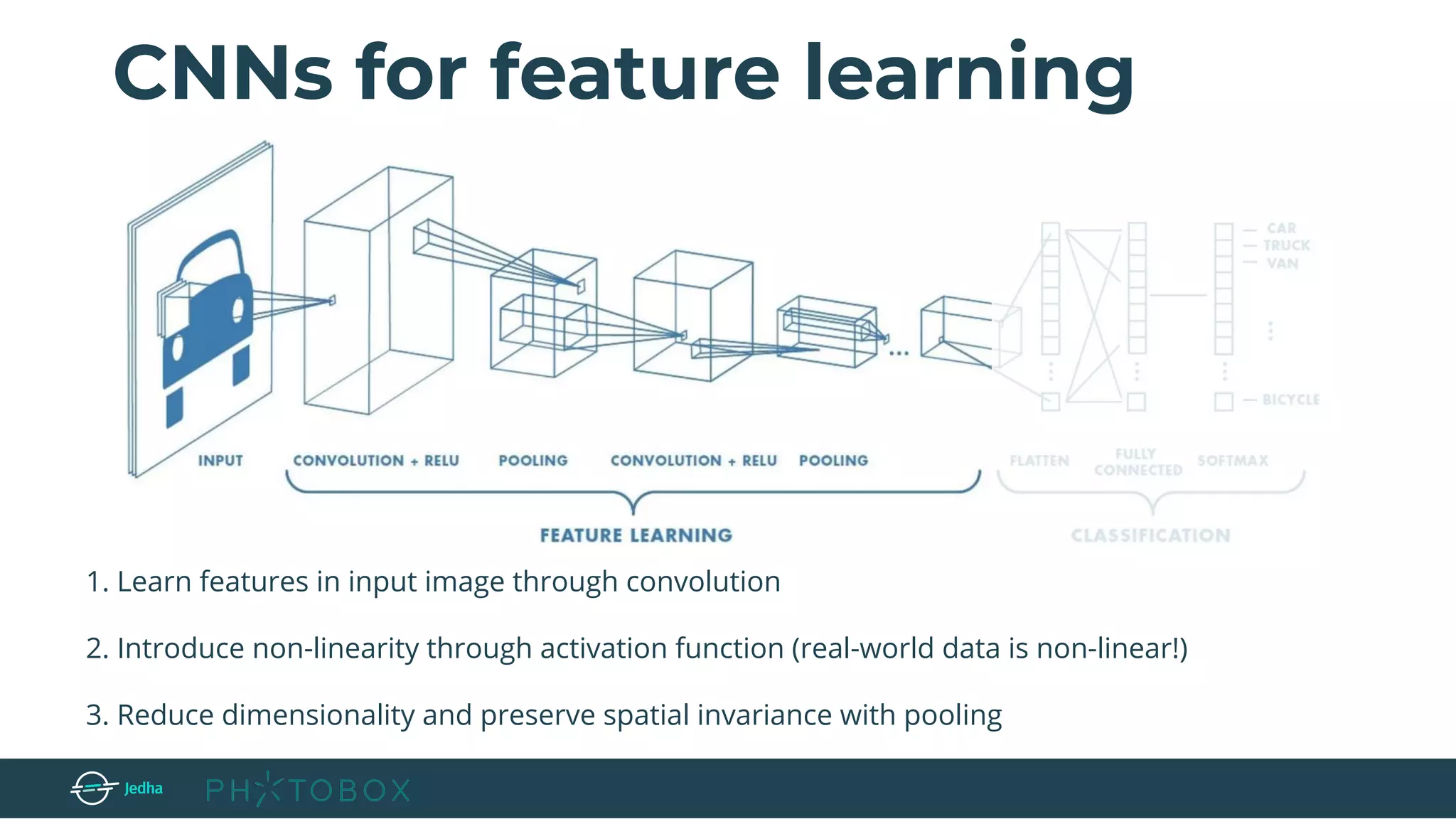
![Layers used to build ConvNets
INPUT → will hold the raw pixel values of the image (e.g.[32,32,3] - image with width 32,
height 32 and 3 channels: RGB)
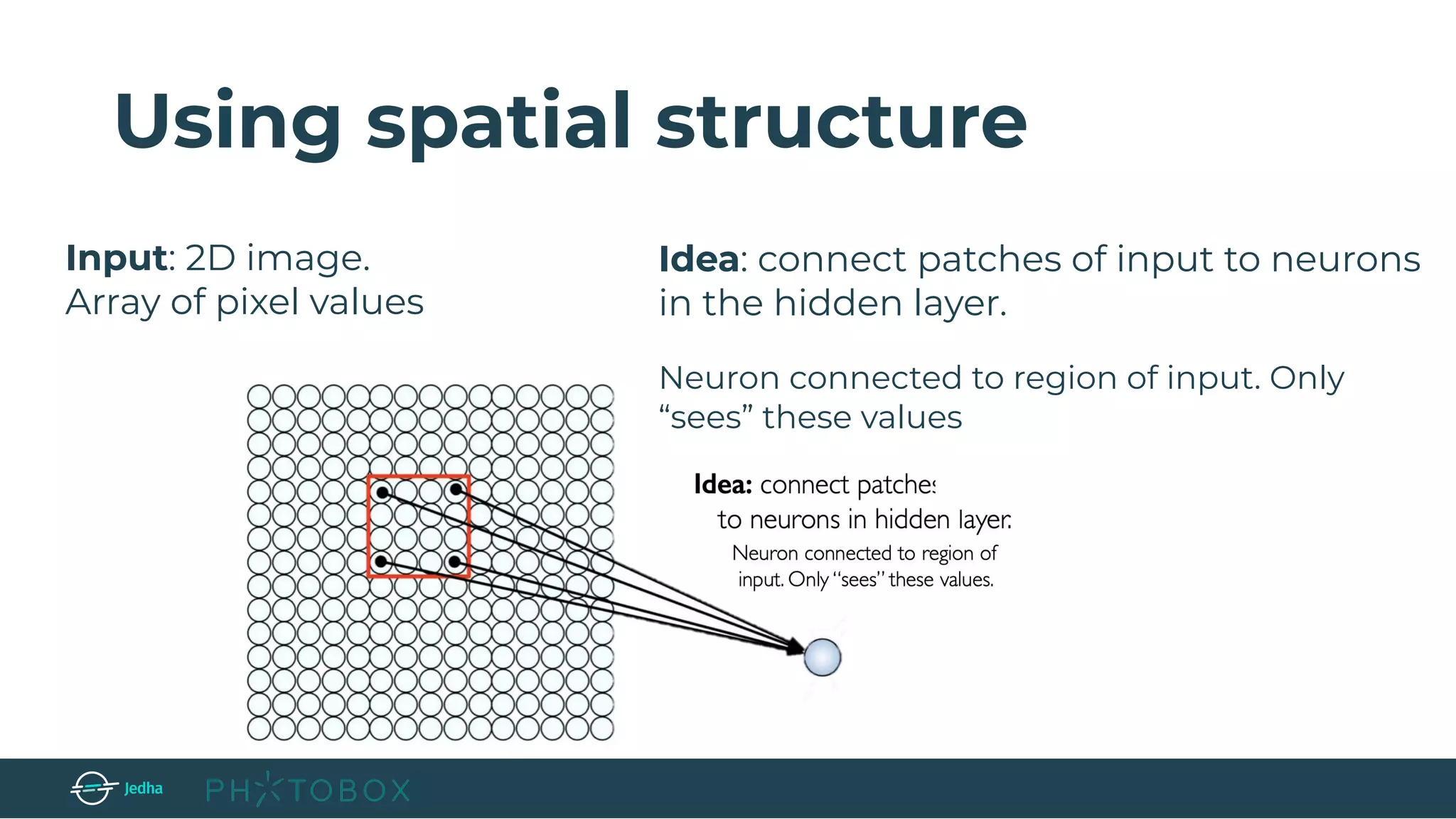
Convolutional layer (CONV) → compute the output of neurons connected to
local regions in the input (e.g.: output of size [32x32x12] if we decided to use 12 filters)
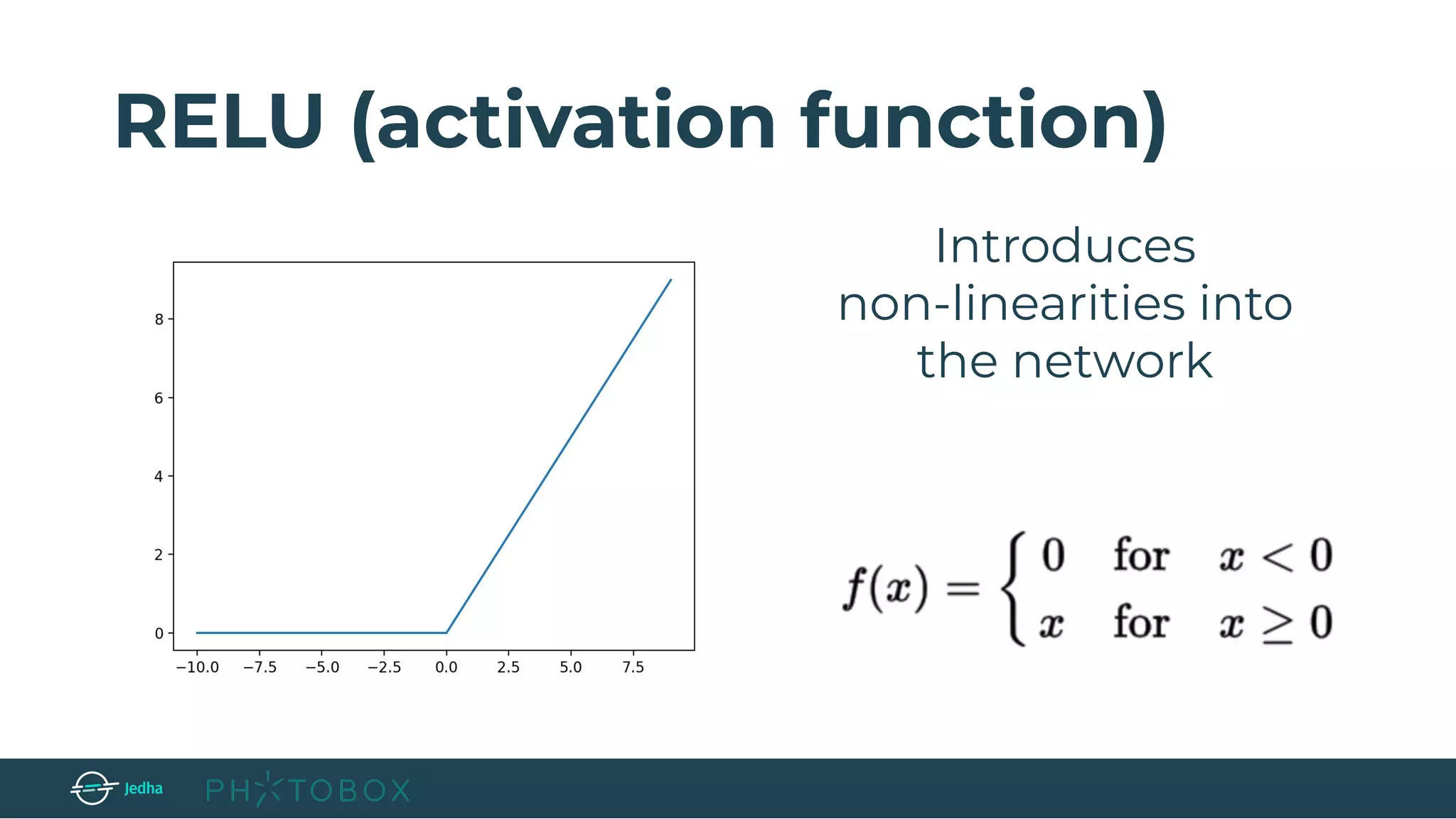
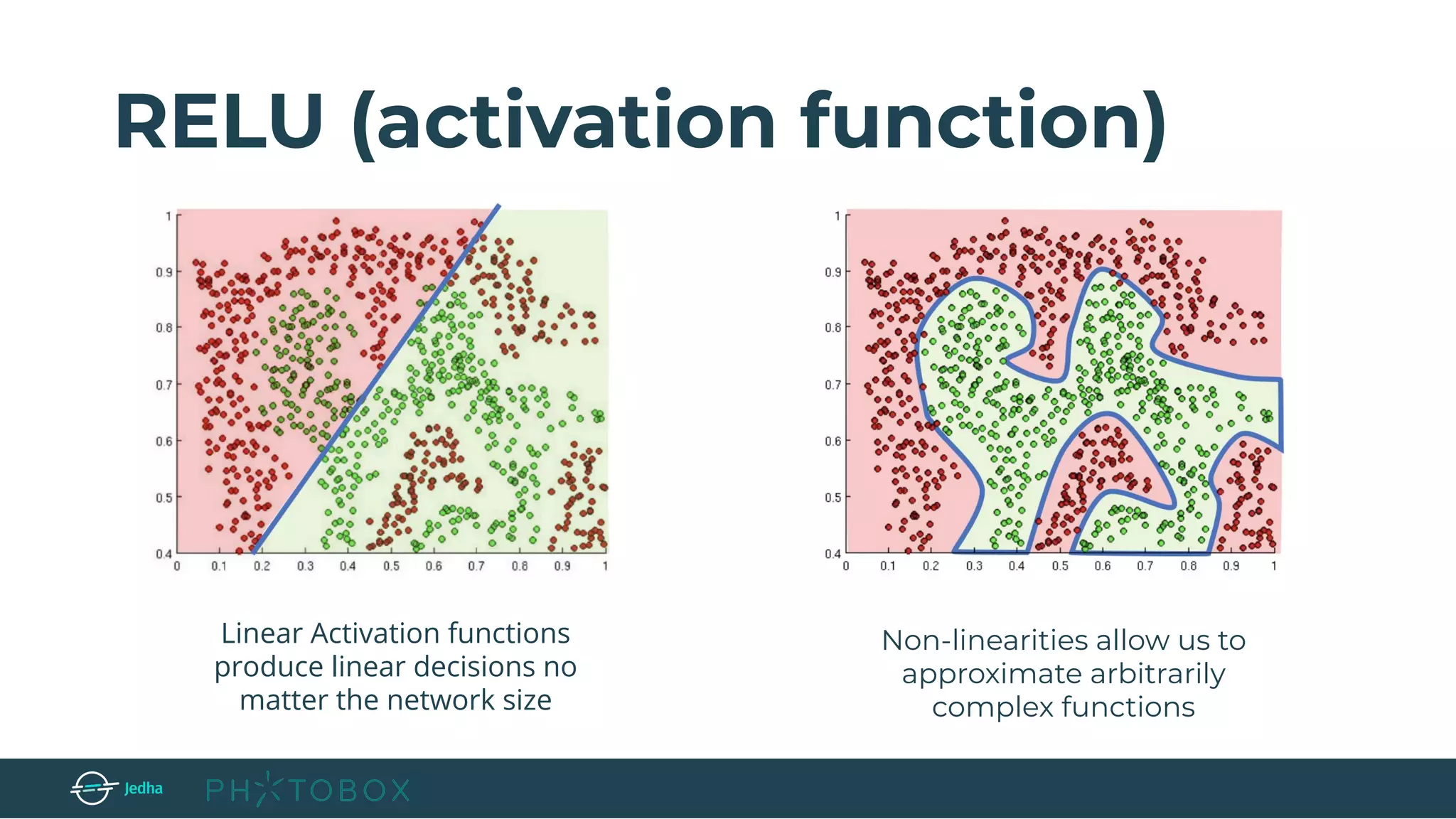
RELU → apply an elementwise activation function, such as the max(0,x) thresholding at
zero. (e.g. the size of the volume is unchanged [32x32x12])
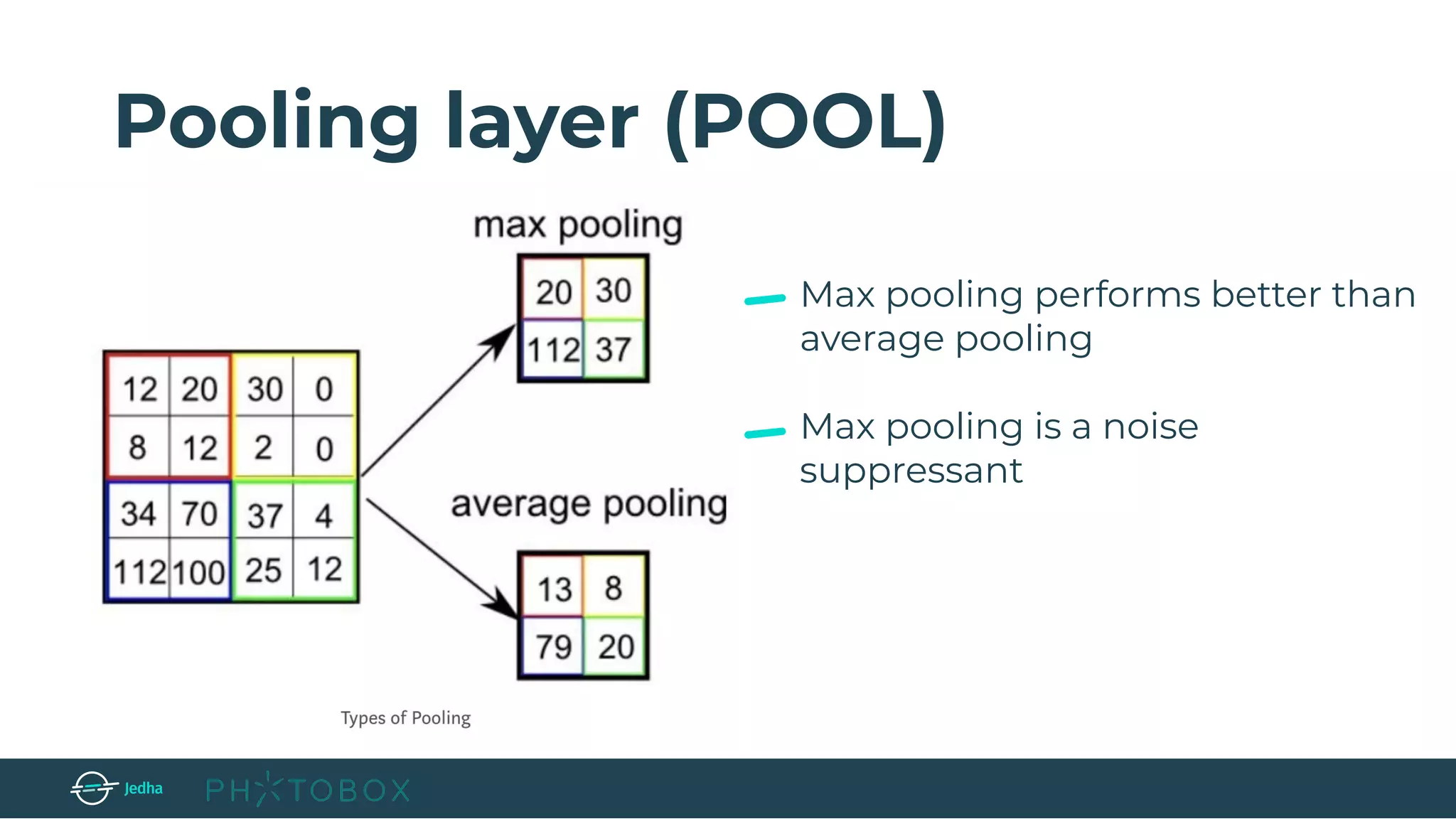
POOL → perform a downsampling operation along the spatial dimensions (width, height),
resulting in volume such as [16x16x12].
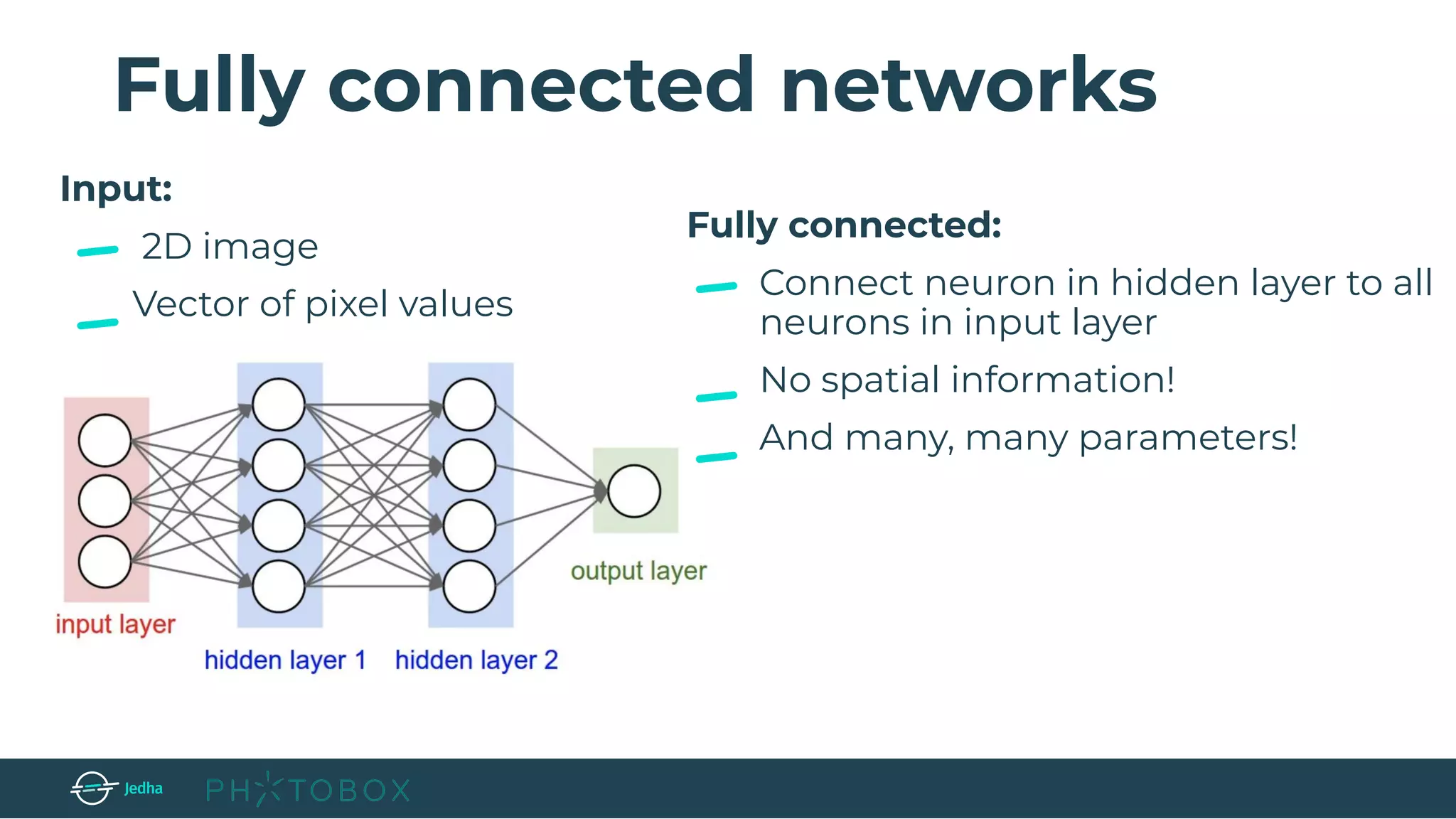
Fully connected layer (FC) → compute the class scores, and it connects all
neurons in this layer with all the neurons in the previous one. (e.g. the size is [1, 1, 10] if we
have 10 classes)](https://image.slidesharecdn.com/jedhaxphotobox-imagerecognitionwithdeeplearning-190425170000/75/Faire-de-la-reconnaissance-d-images-avec-le-Deep-Learning-Cristina-Pierre-Photobox-12-2048.jpg)





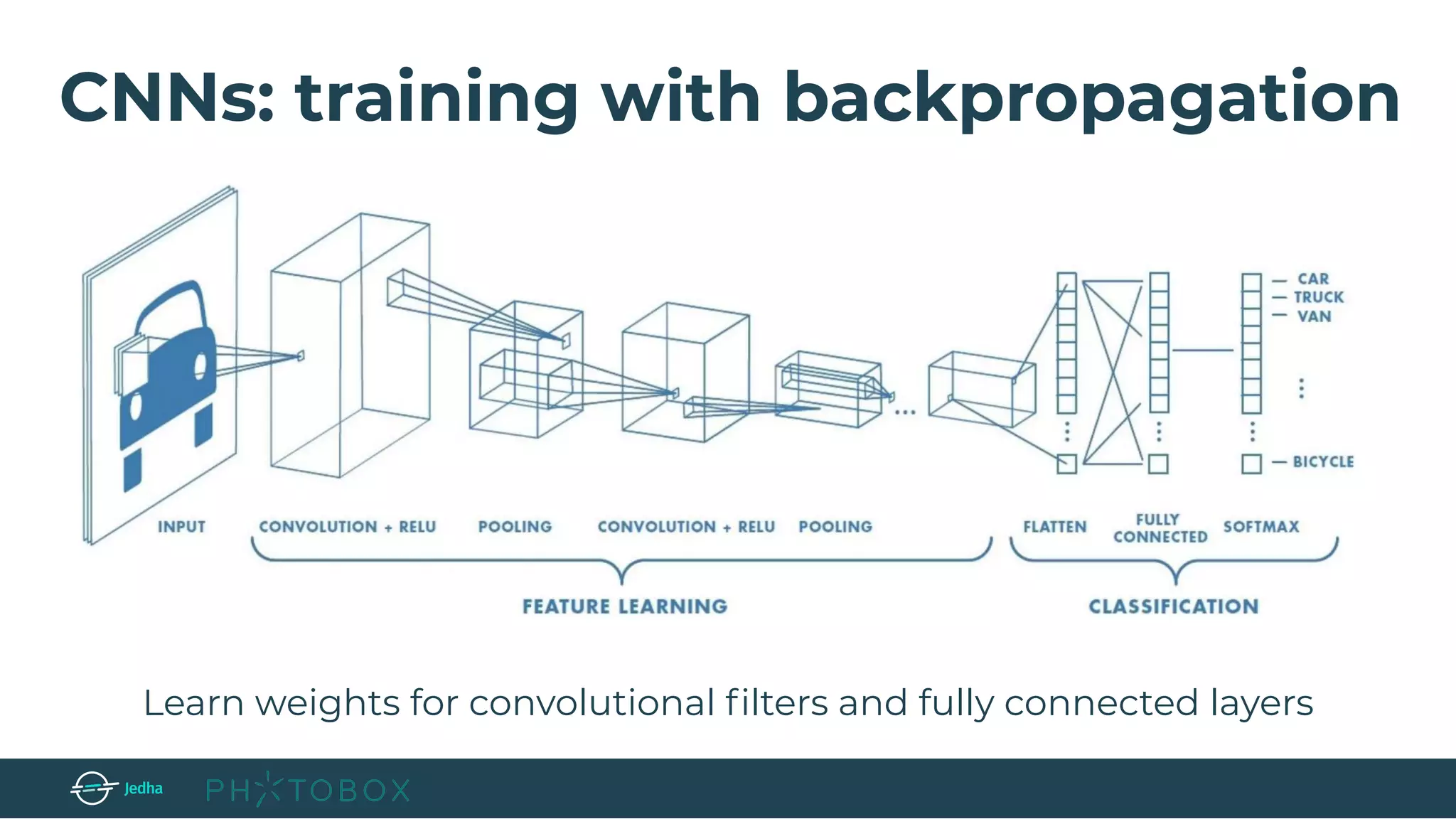
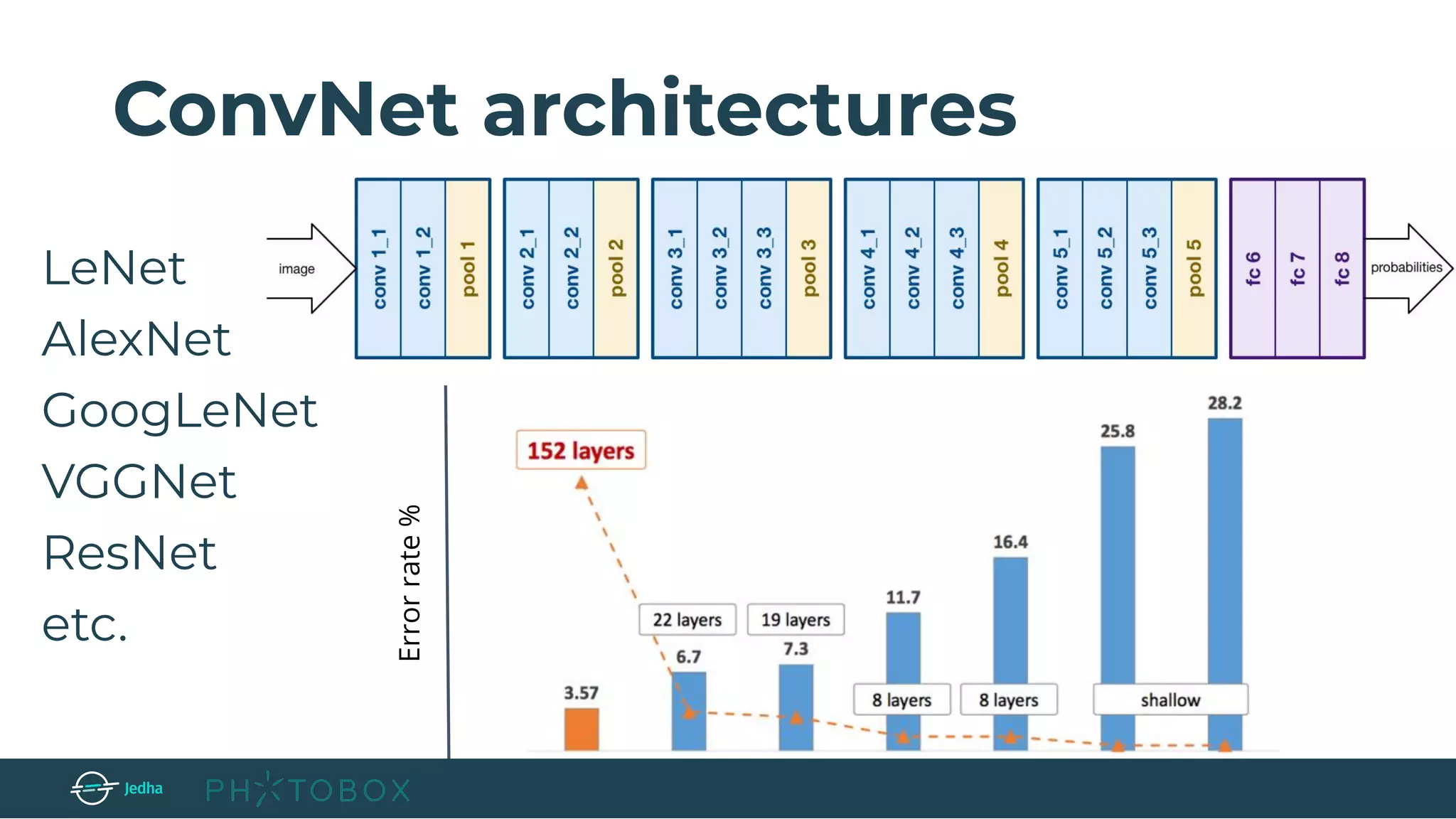
















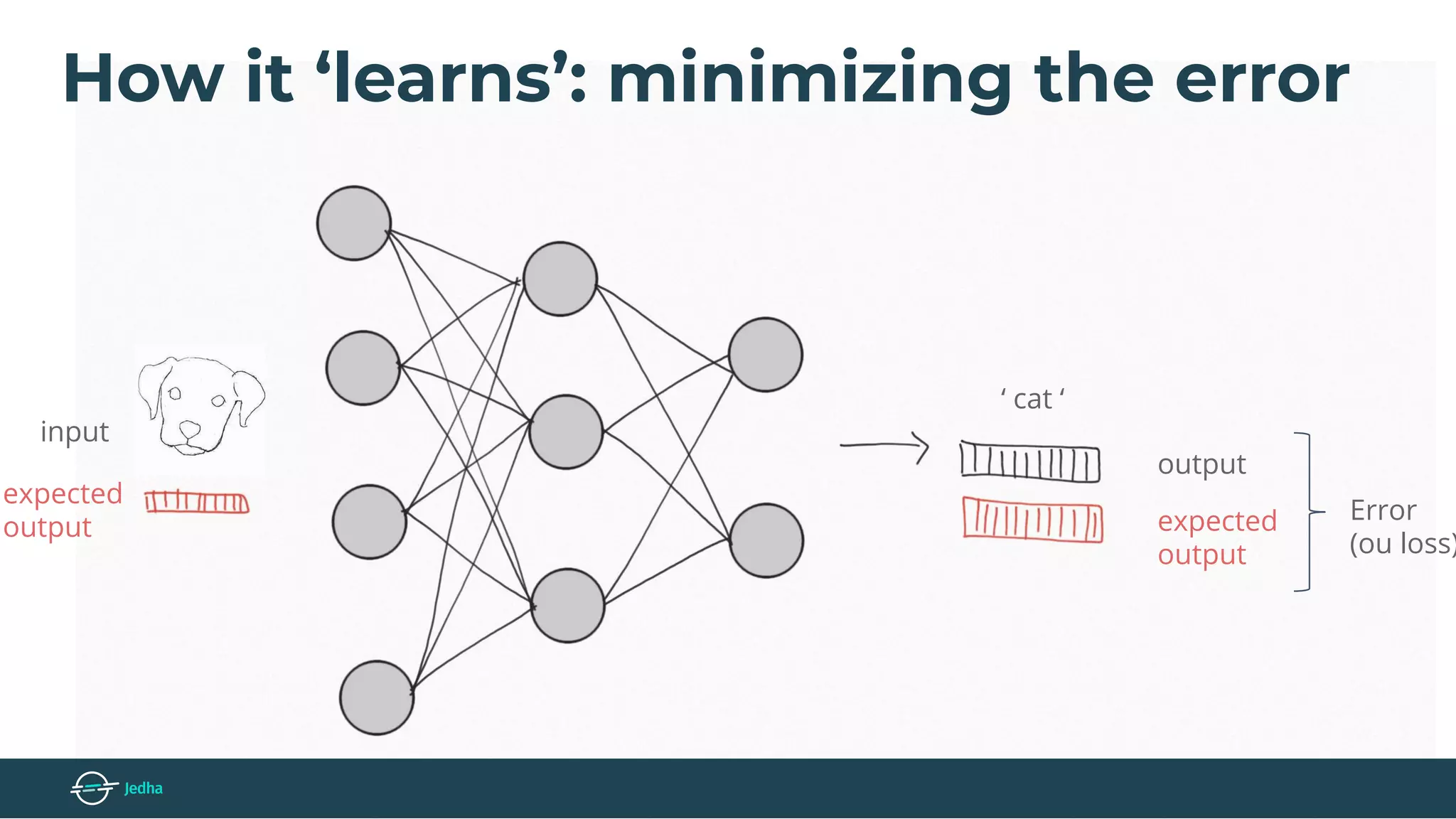

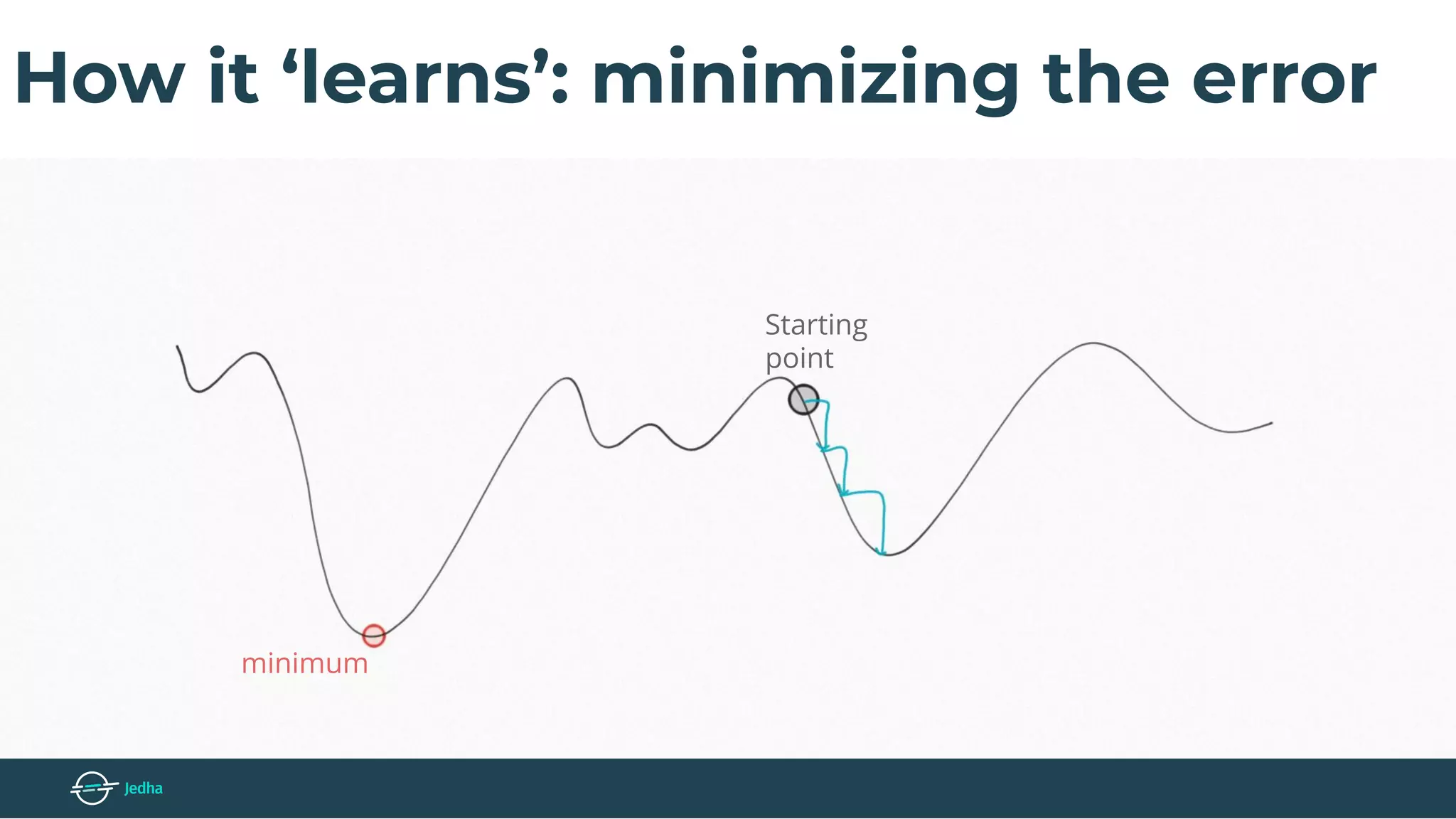
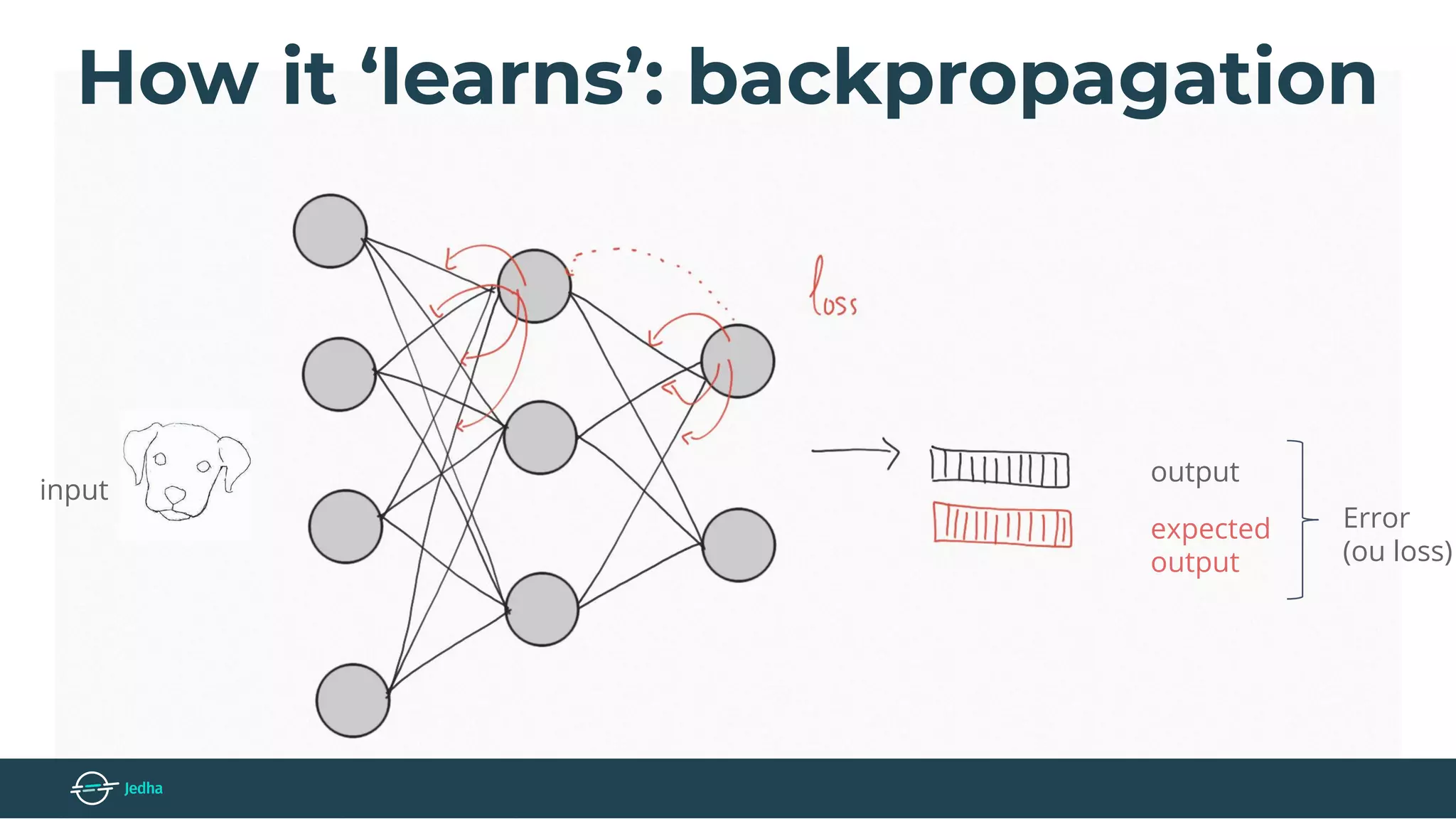


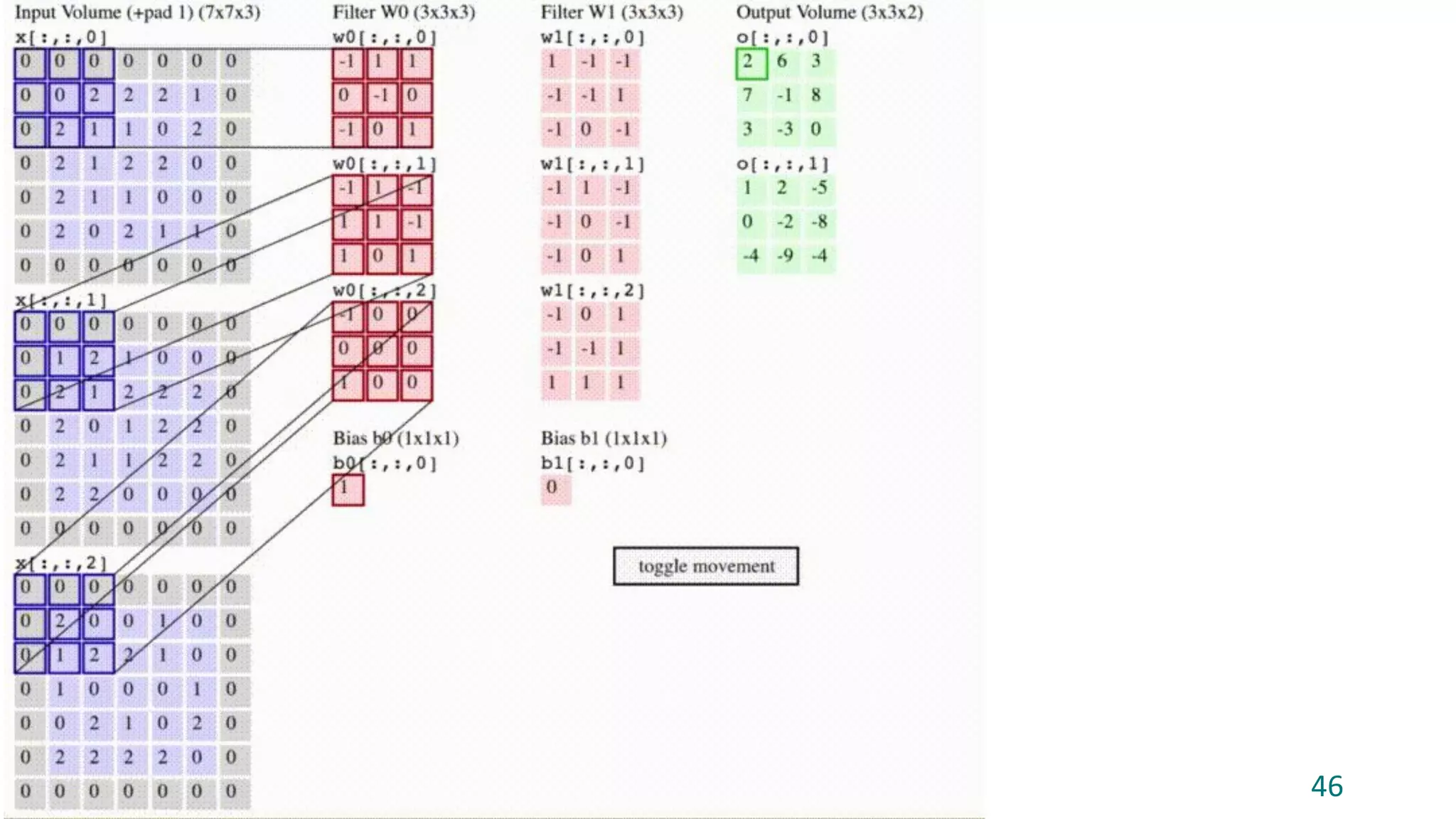
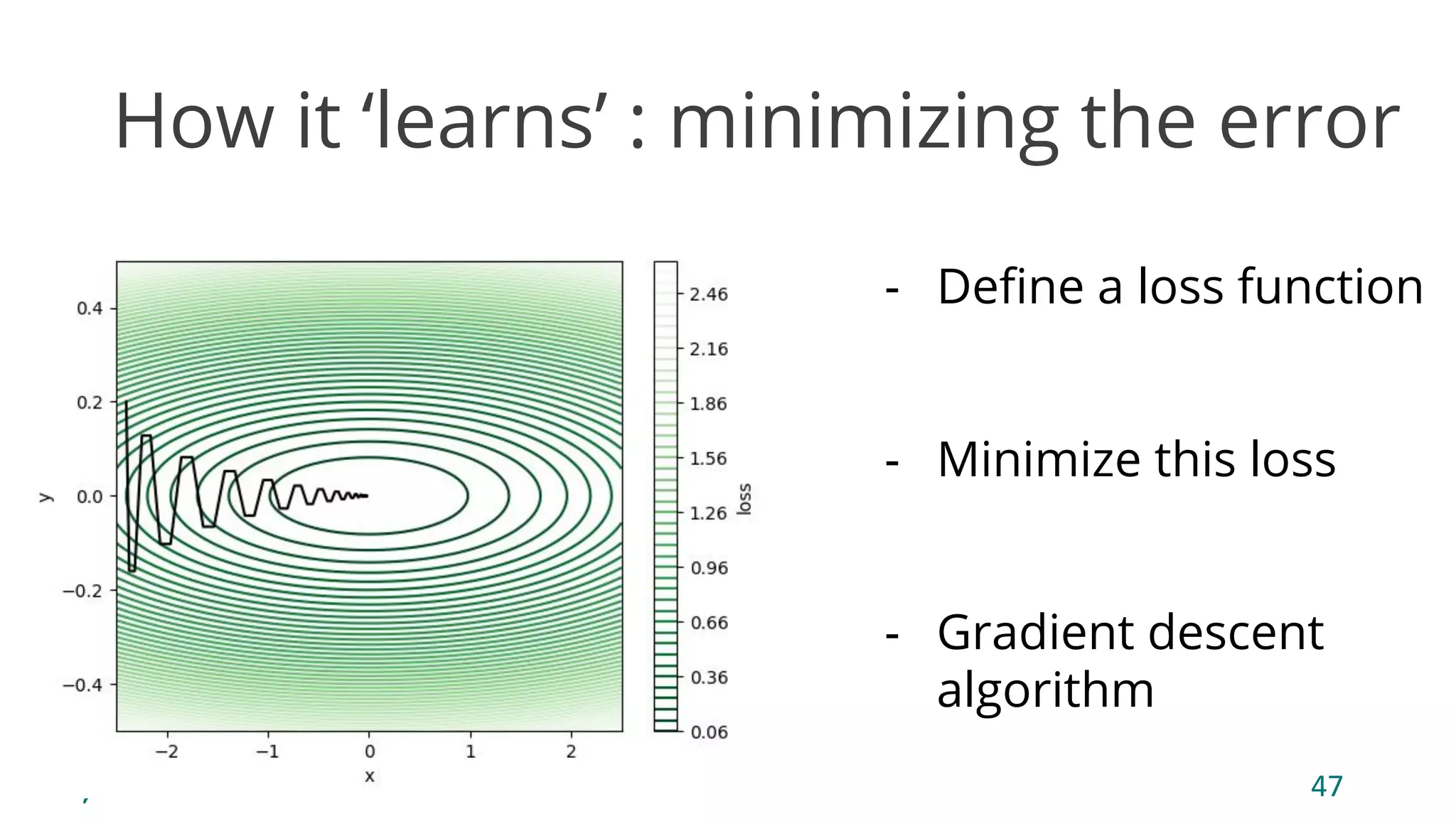

The document discusses the fundamentals of deep learning, particularly through the use of Convolutional Neural Networks (CNNs) for image processing and classification. It outlines key components such as convolutional layers, activation functions, and pooling techniques, and emphasizes the importance of feature extraction and dimensionality reduction. The content also addresses practical applications of CNNs, techniques for dataset creation, and the learning process involving backpropagation.








































































![[DSC Europe 25] Boris Perkovic - Lost in performance.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/uq5hrp7vsuahqkxzifux-1-251204082258-fd2ee09d-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Goran Obradovic - The Rise of Sovereign AI: Building the Regi...](https://cdn.slidesharecdn.com/ss_thumbnails/7nw2xxixrxqdxvrb5wca-6-251205085714-ab09a2ac-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Dragan Vucic - Building the Learning Organization - How AI Tr...](https://cdn.slidesharecdn.com/ss_thumbnails/8brigo2sbu6qur6gxrra-7-251205085715-6ae07d24-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Andy Cotgreave - Nothing is new in analytics.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/mba4vzcurvoh5lfrd5zw-6-251205194645-341bbbbe-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Max Talanov - Non digital NNs.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/wif8tr3gtua74qvtopke-non-digital-nns-251205090438-26b0eea6-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Marija Vlajkovic & Andrea Radonjanin - Integration of AI tool...](https://cdn.slidesharecdn.com/ss_thumbnails/qf1jrglttoc3bm8s3aop-final-integration-of-ai-tools-251208151905-394f3a6a-thumbnail.jpg?width=640&height=640&fit=bounds)



