Download as PDF, PPTX



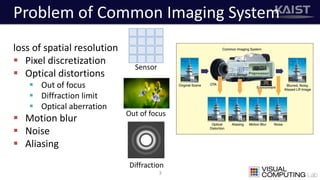


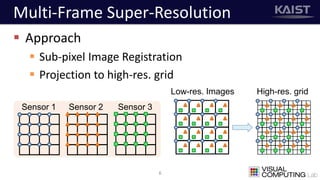

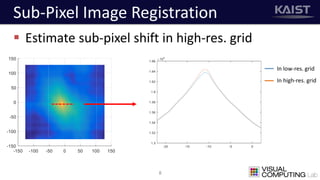
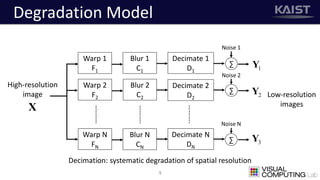



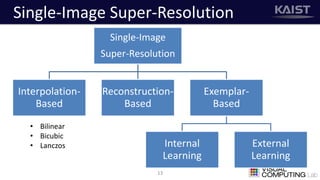
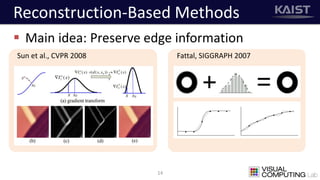

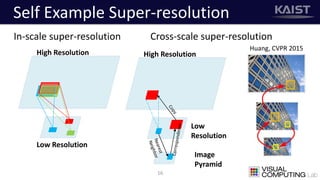
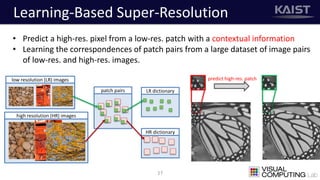
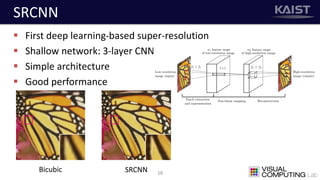
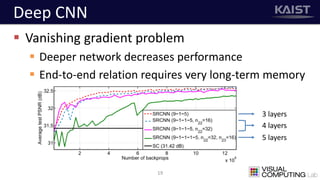
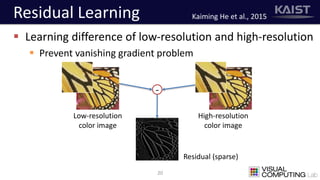
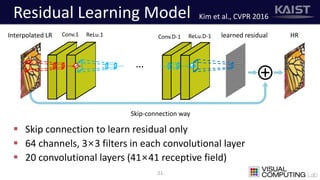


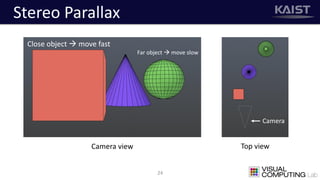
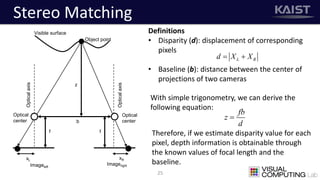






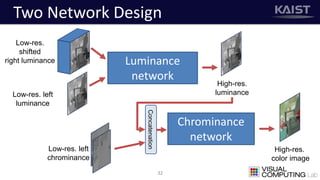

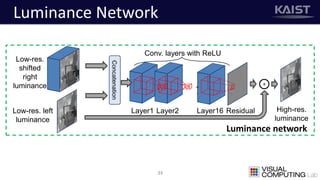

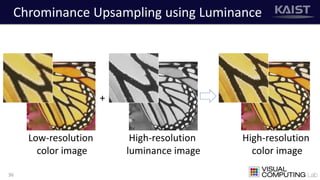
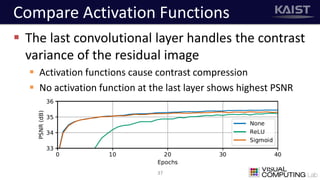
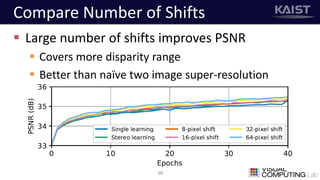
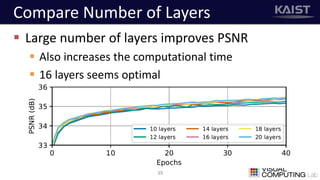
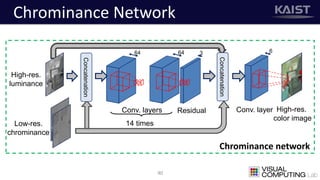
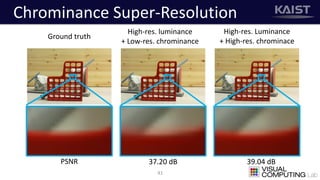
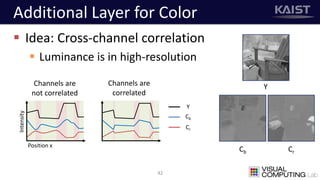
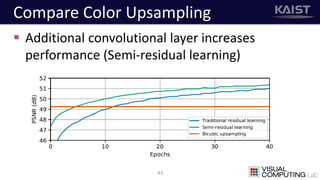




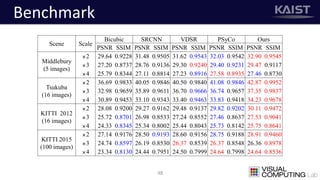


The document discusses a deep learning-based approach for stereo super-resolution, which aims to enhance the spatial resolution of stereo images using a parallax prior. The method addresses common imaging system issues and surpasses traditional techniques by reconstructing high-resolution images without direct disparity calculation, demonstrating promising performance metrics. Results indicate the proposed method outperforms existing state-of-the-art approaches in stereo imaging applications.









![[OSGeo-KR Tech Workshop] Deep Learning for Single Image Super-Resolution](https://cdn.slidesharecdn.com/ss_thumbnails/osgeo-krdeeplearningforsingleimagesuper-resolution-180223175347-thumbnail.jpg?width=640&height=640&fit=bounds)

































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)










