CNN
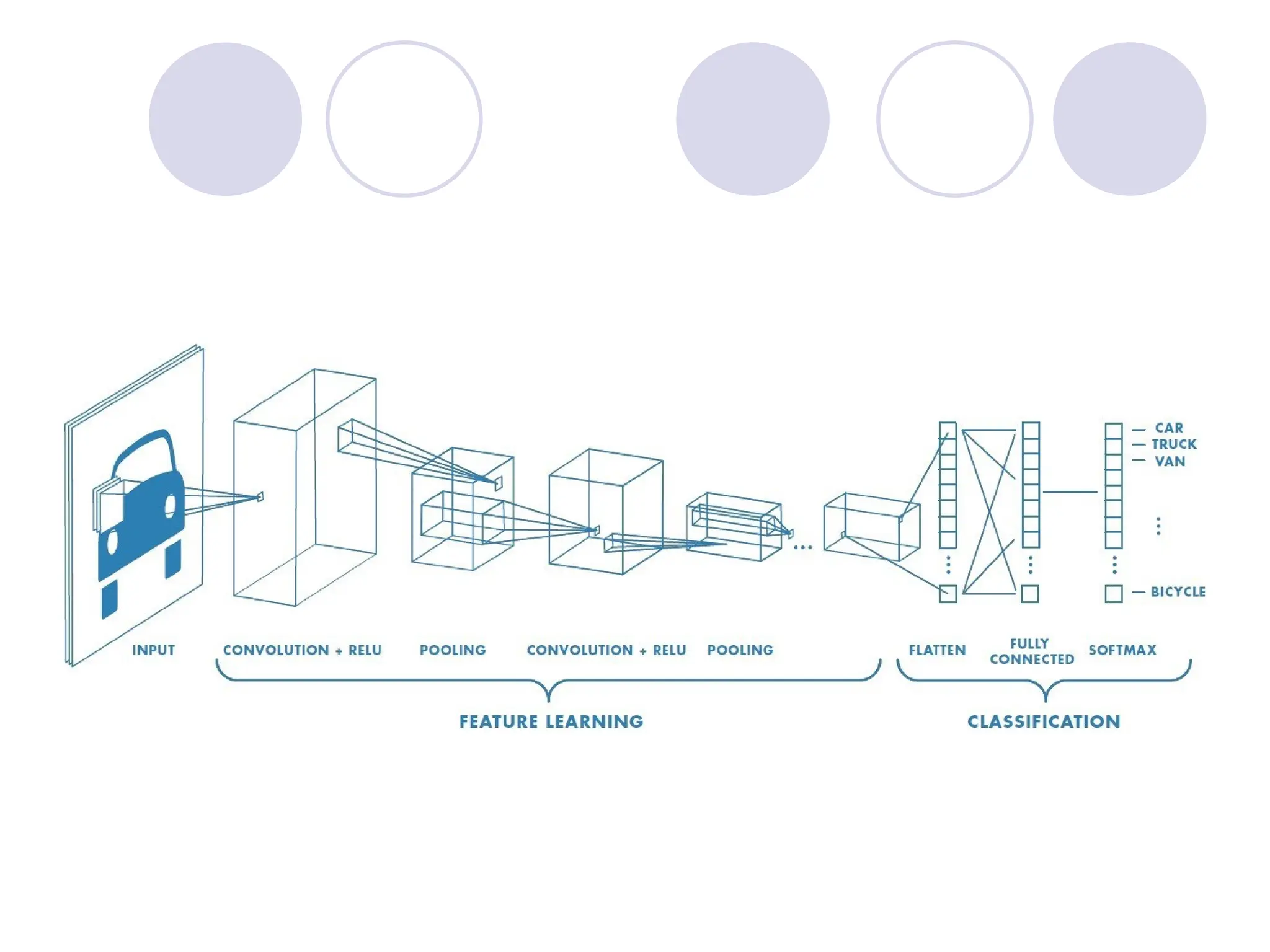
A convolutional neuralnetwork can have tens or hundreds of layers that each learn to
detect different features of an image. Filters are applied to each training image at
different resolutions, and the output of each convolved image is used as the input to
the next layer. The filters can start as very simple features, such as brightness and
edges, and increase in complexity to features that uniquely define the object.
2.
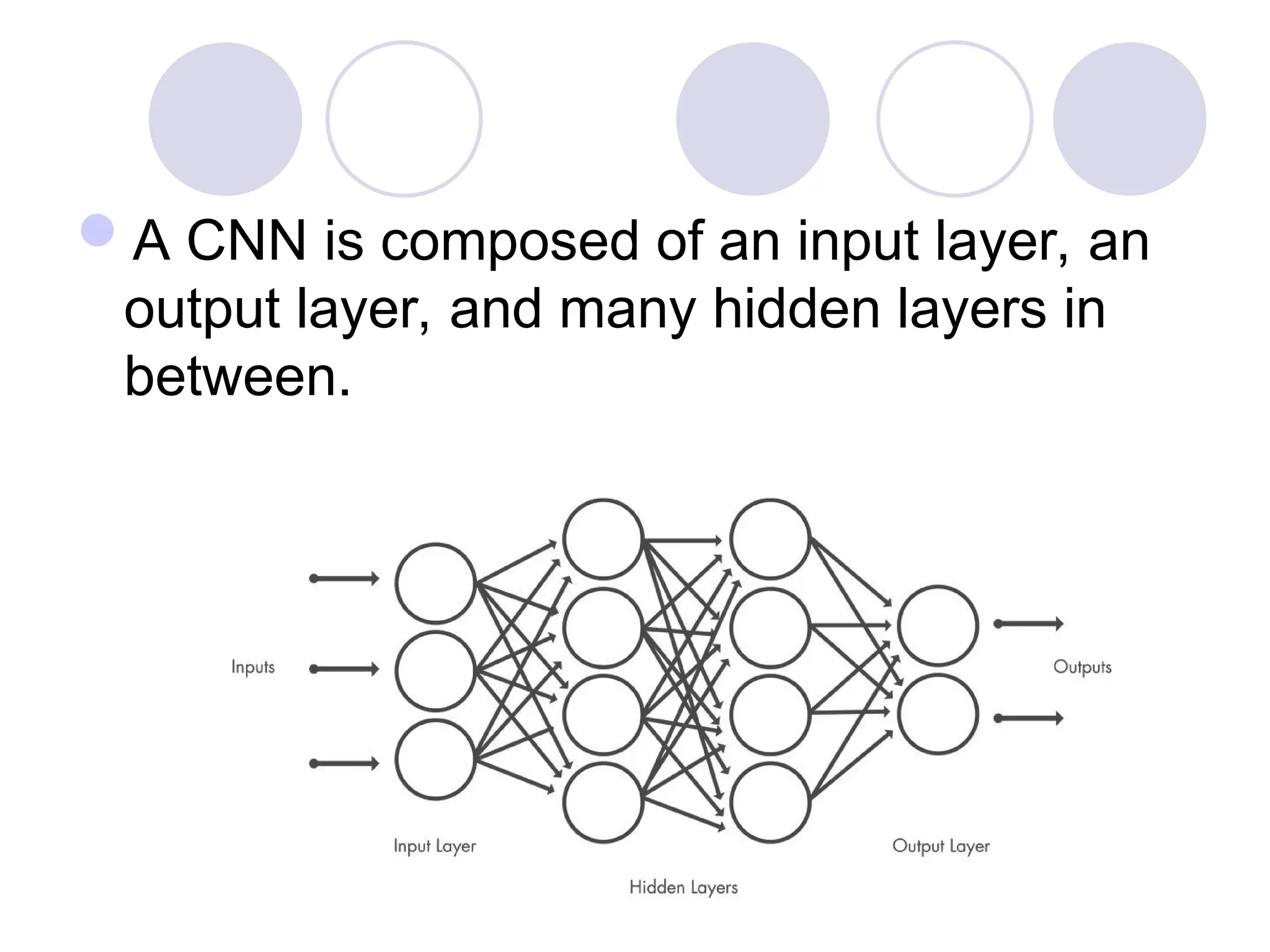
A CNN iscomposed of an input layer, an
output layer, and many hidden layers in
between.
3.
These layersperform operations that alter the data with the intent of
learning features specific to the data. Three of the most common layers are
convolution, activation or ReLU, and pooling.
Convolution puts the input images through a set of convolutional filters,
each of which activates certain features from the images.
Rectified linear unit (ReLU) allows for faster and more effective training by
mapping negative values to zero and maintaining positive values. This is
sometimes referred to as activation, because only the activated features are
carried forward into the next layer.
Pooling simplifies the output by performing nonlinear downsampling,
reducing the number of parameters that the network needs to learn.
These operations are repeated over tens or hundreds of layers, with each
layer learning to identify different features.
5.
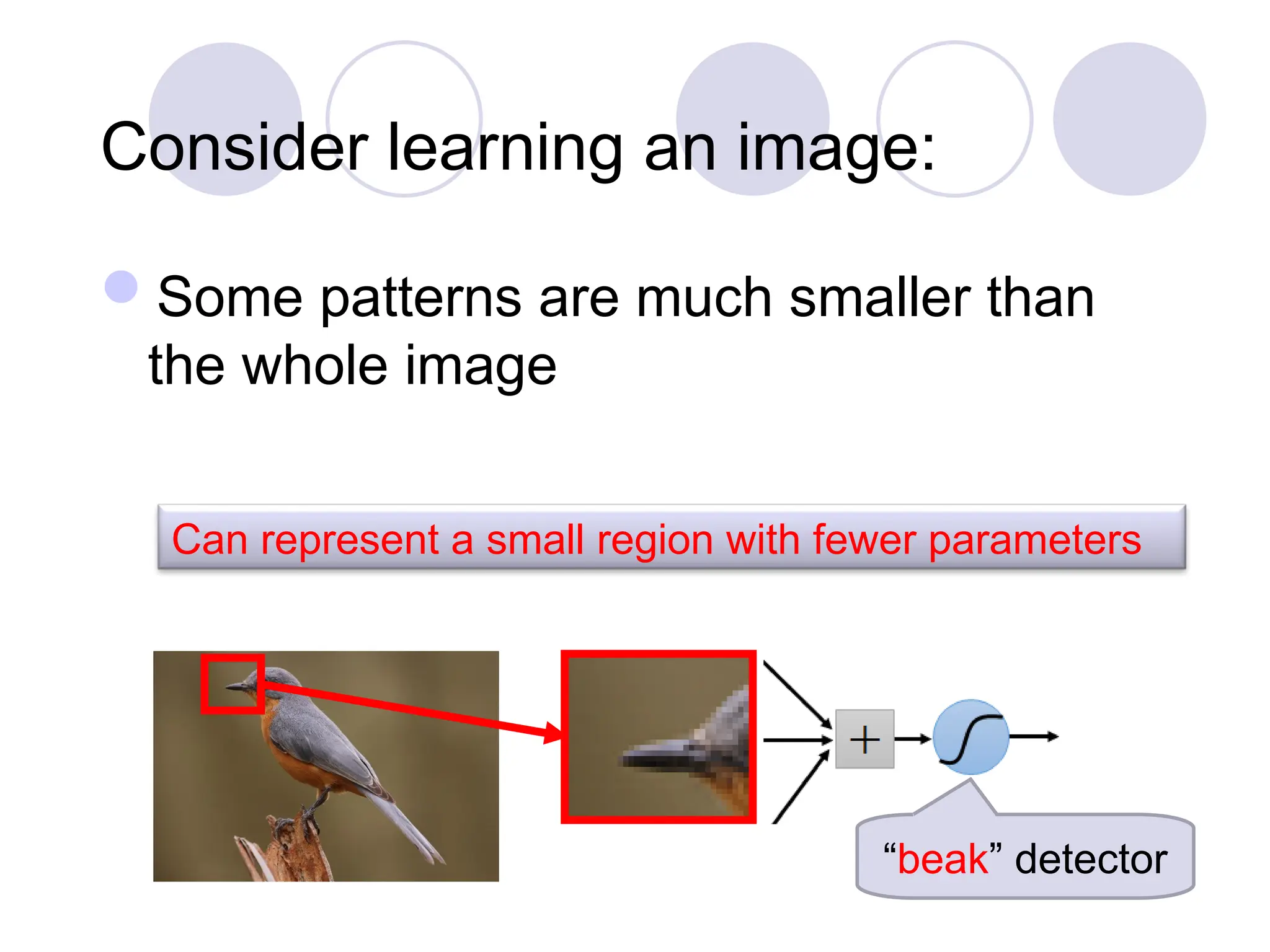
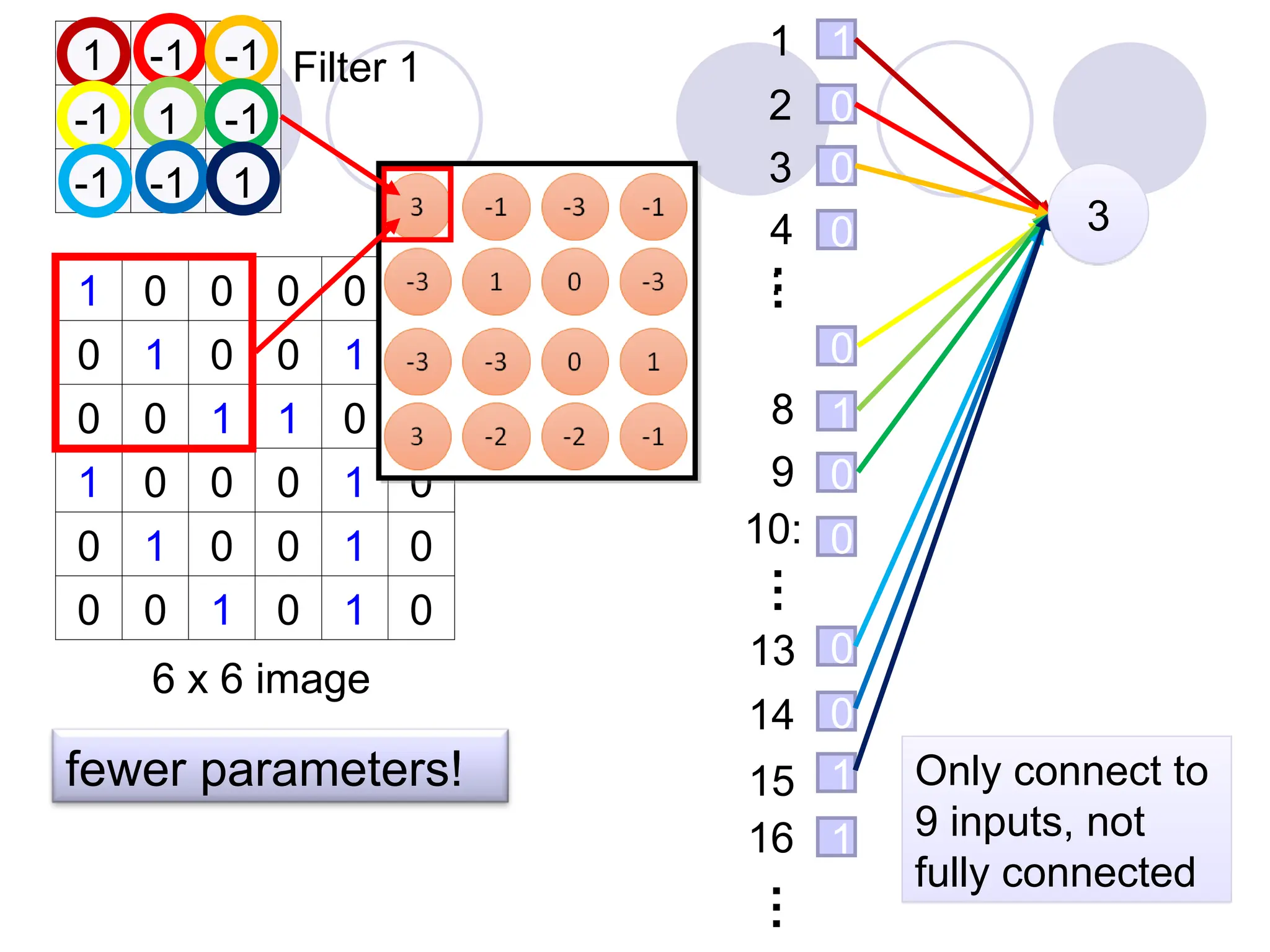
Consider learning animage:
Some patterns are much smaller than
the whole image
“beak” detector
Can represent a small region with fewer parameters
6.
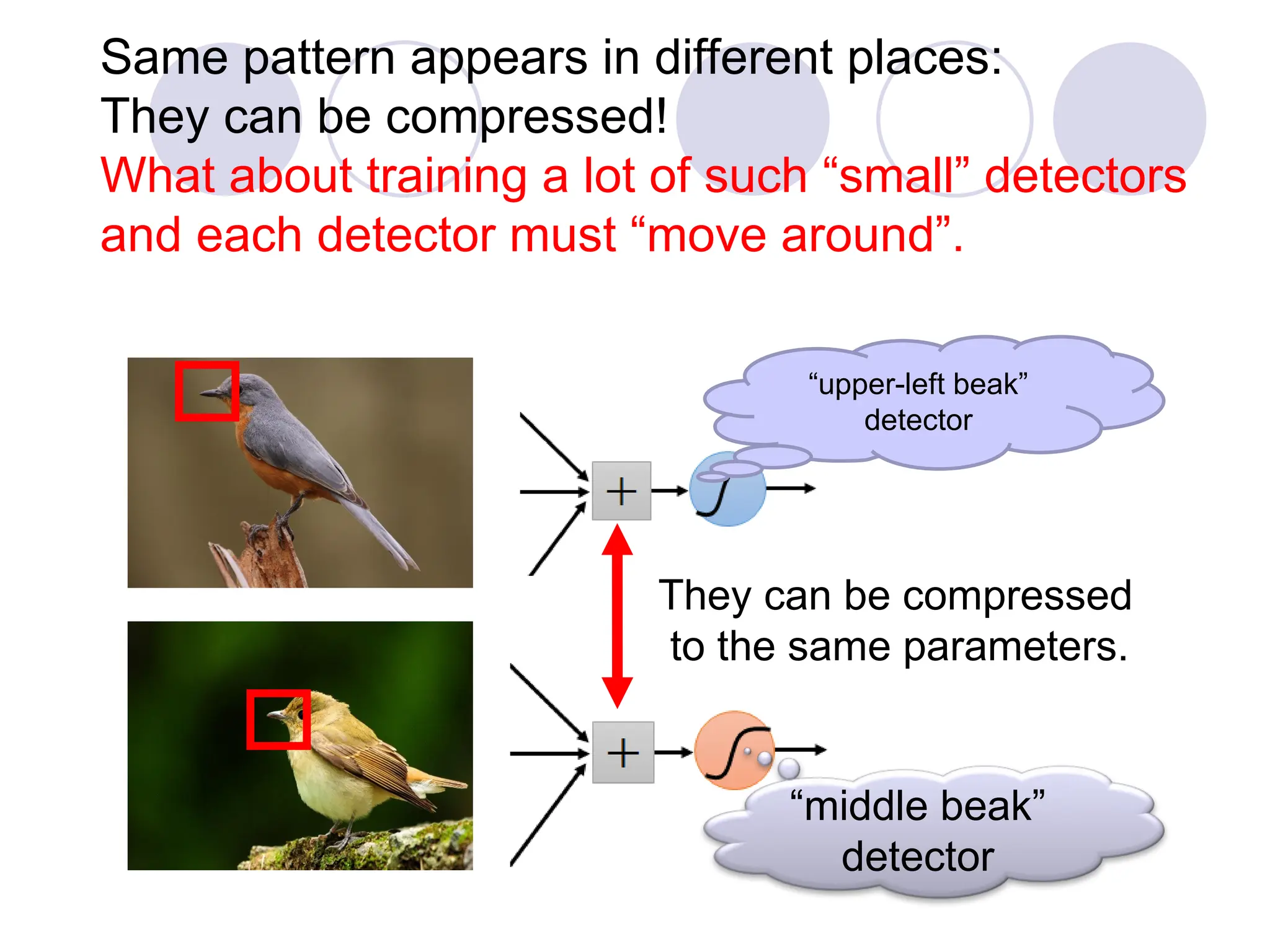
Same pattern appearsin different places:
They can be compressed!
What about training a lot of such “small” detectors
and each detector must “move around”.
“upper-left beak”
detector
“middle beak”
detector
They can be compressed
to the same parameters.
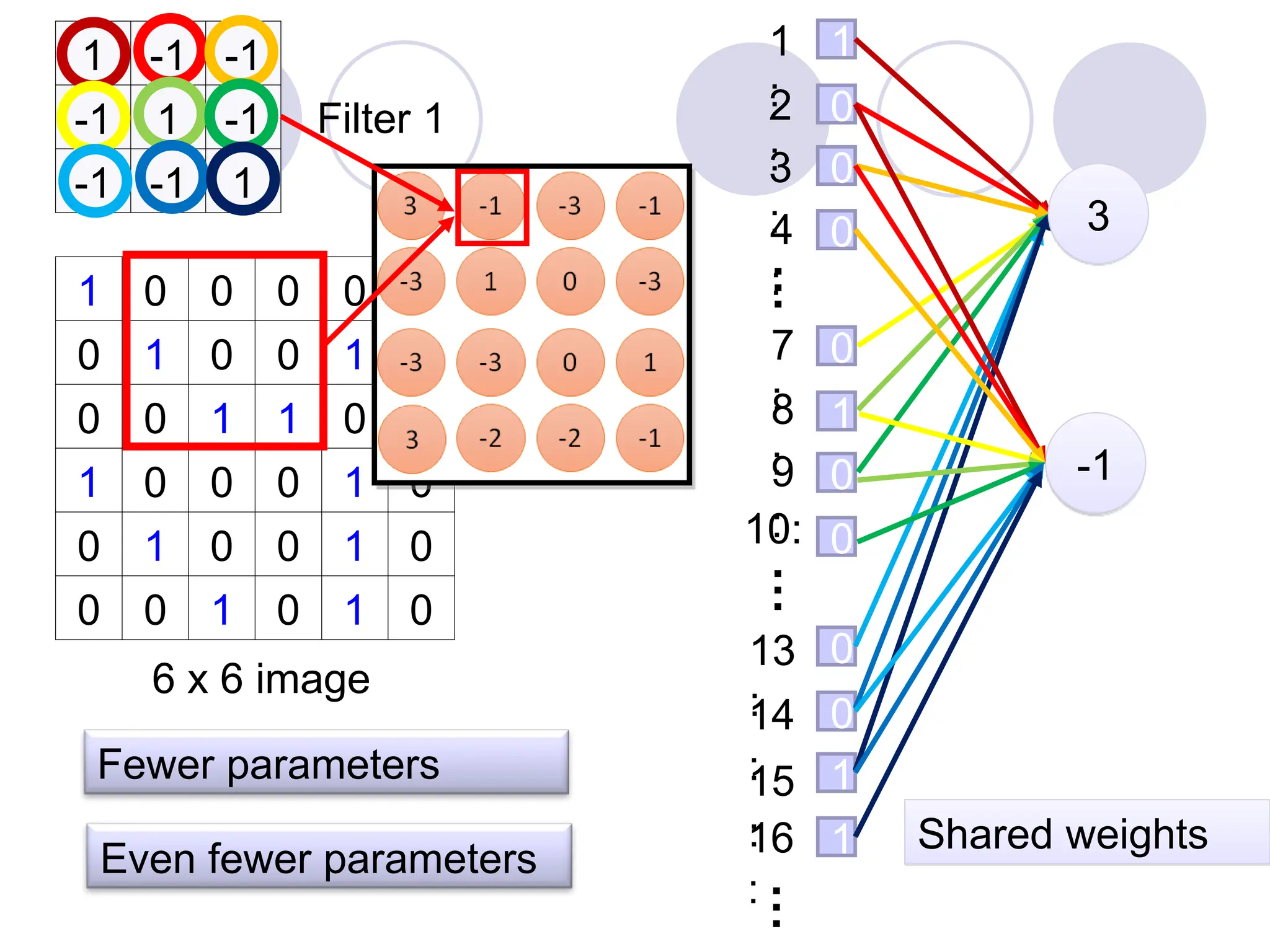
7.
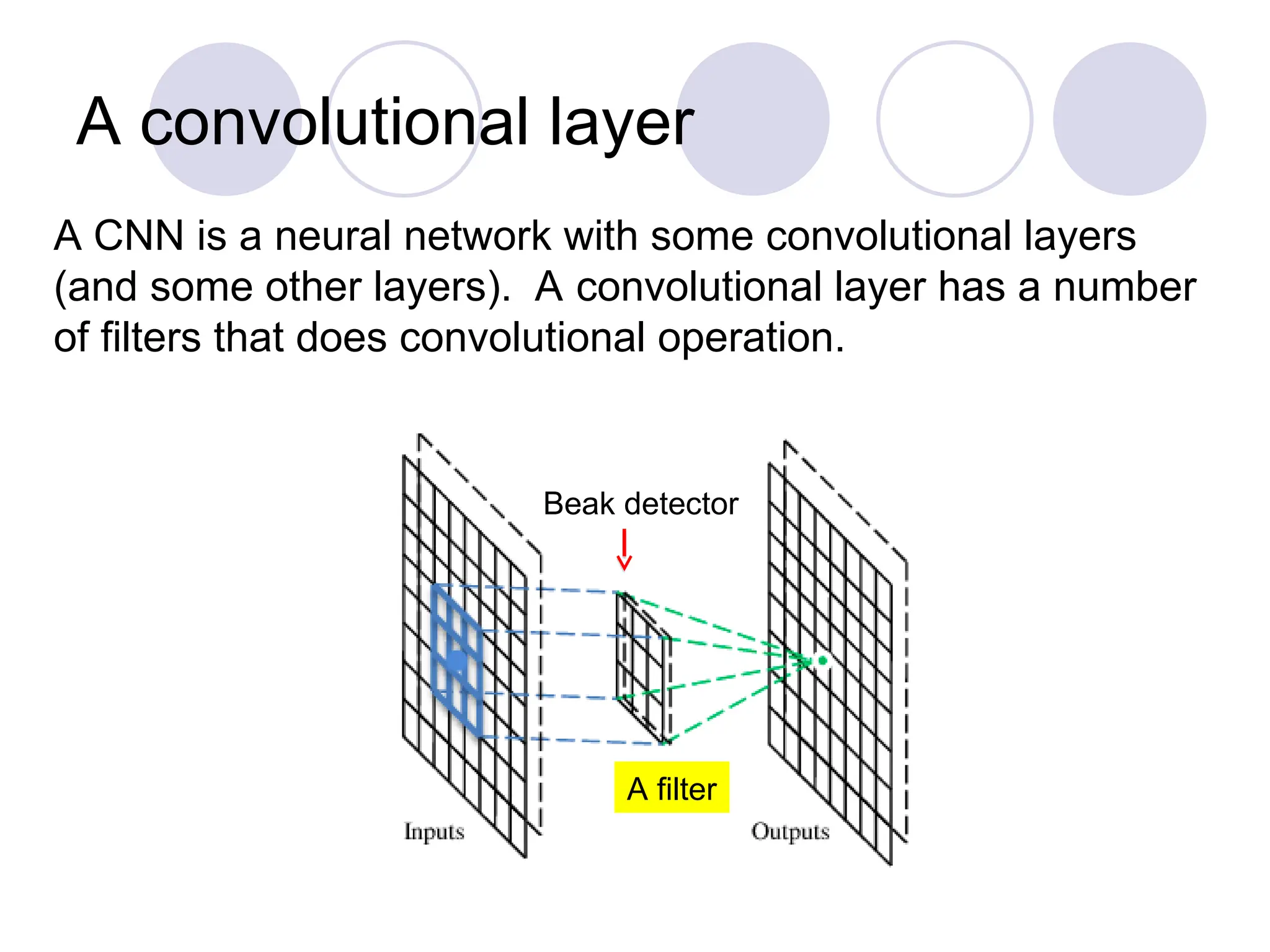
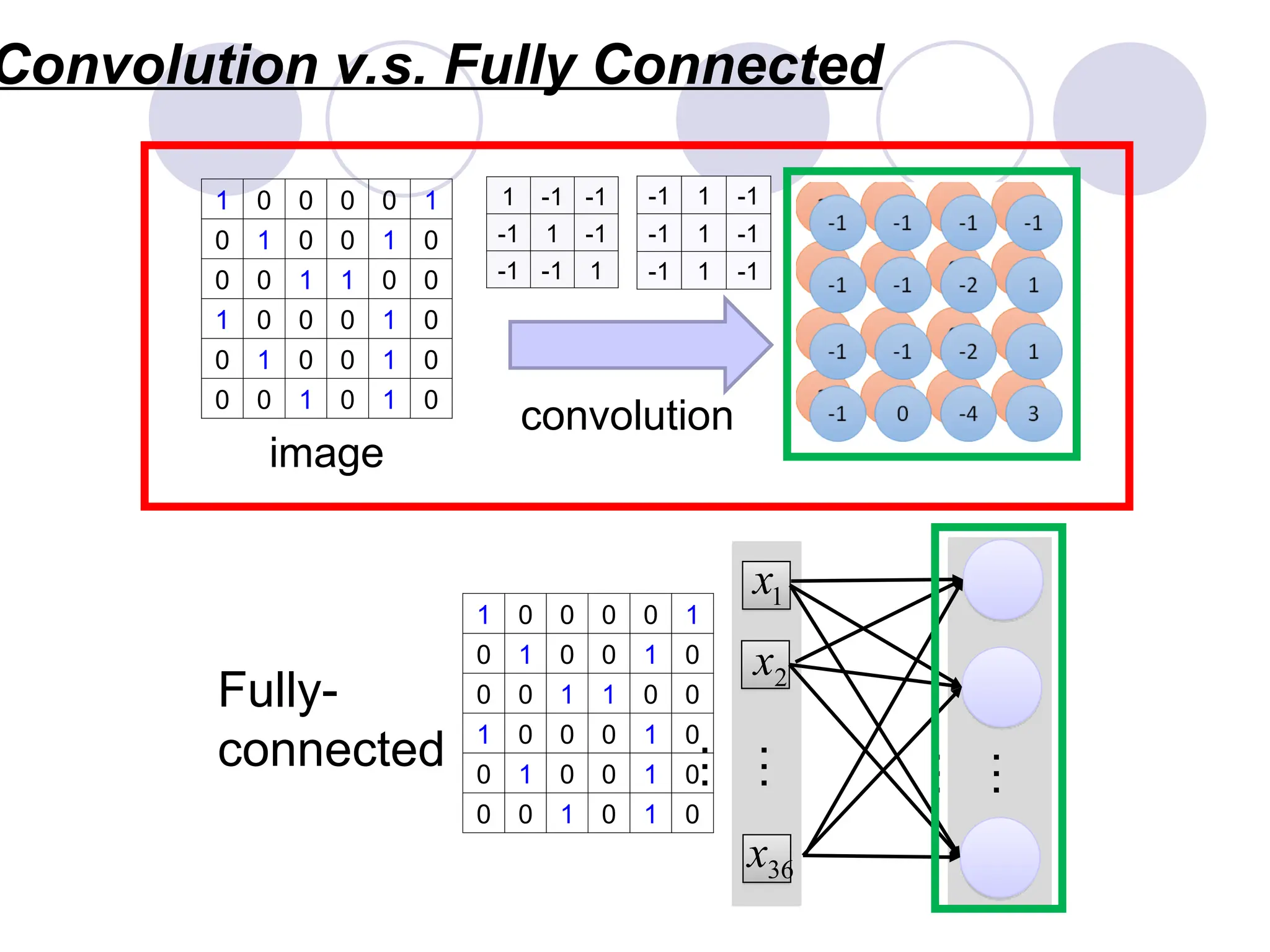
A convolutional layer
Afilter
A CNN is a neural network with some convolutional layers
(and some other layers). A convolutional layer has a number
of filters that does convolutional operation.
Beak detector
8.
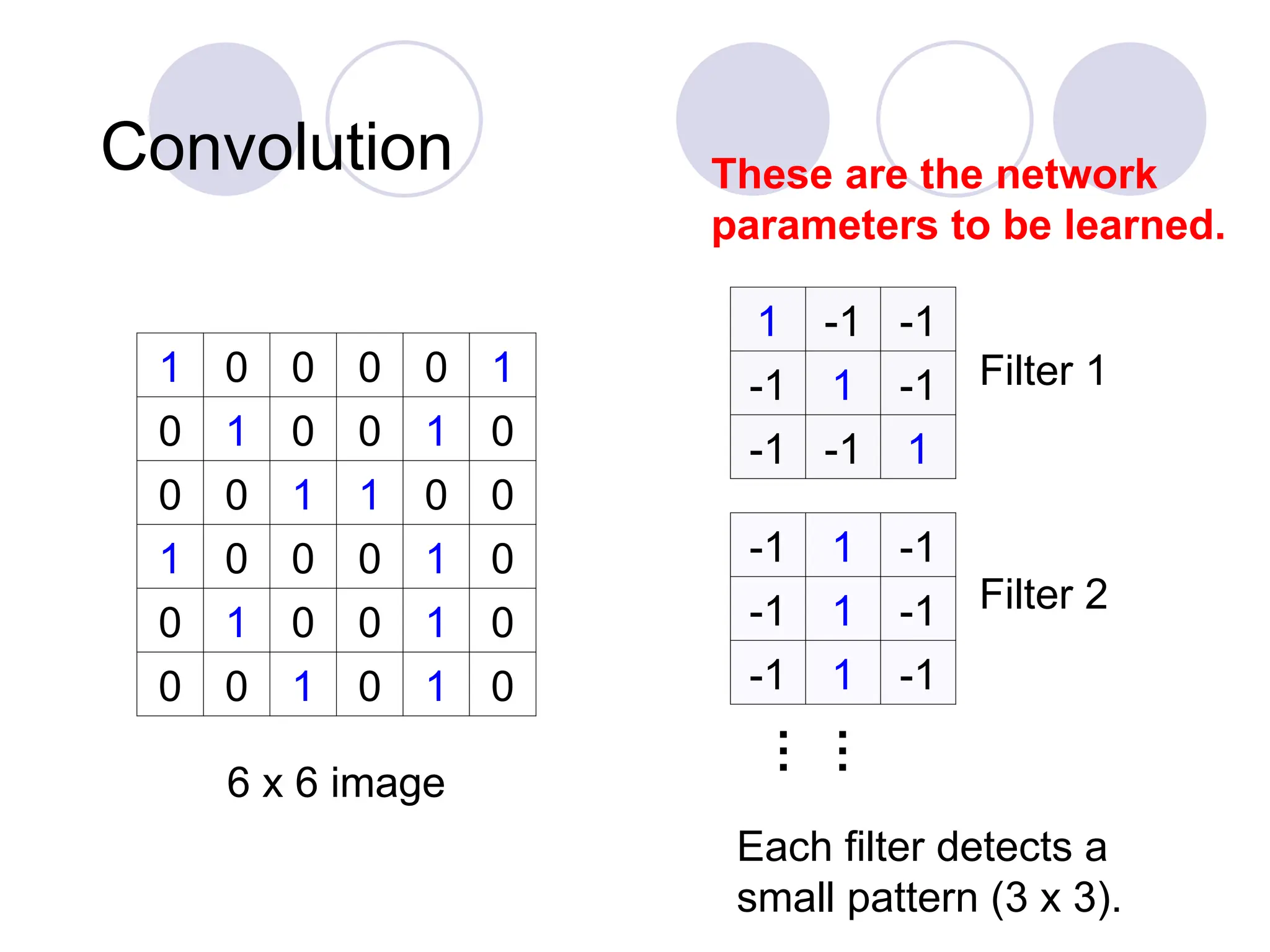
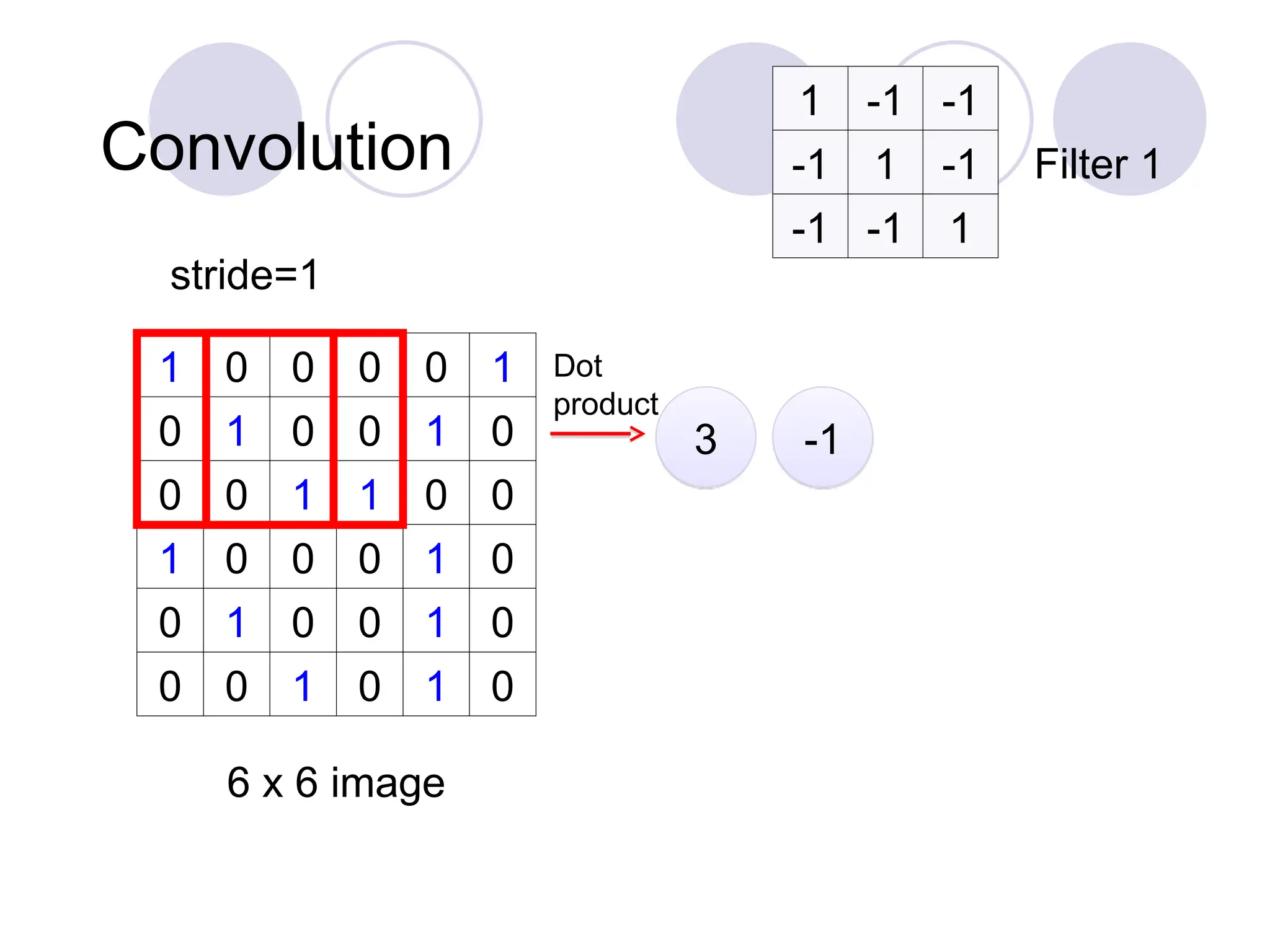
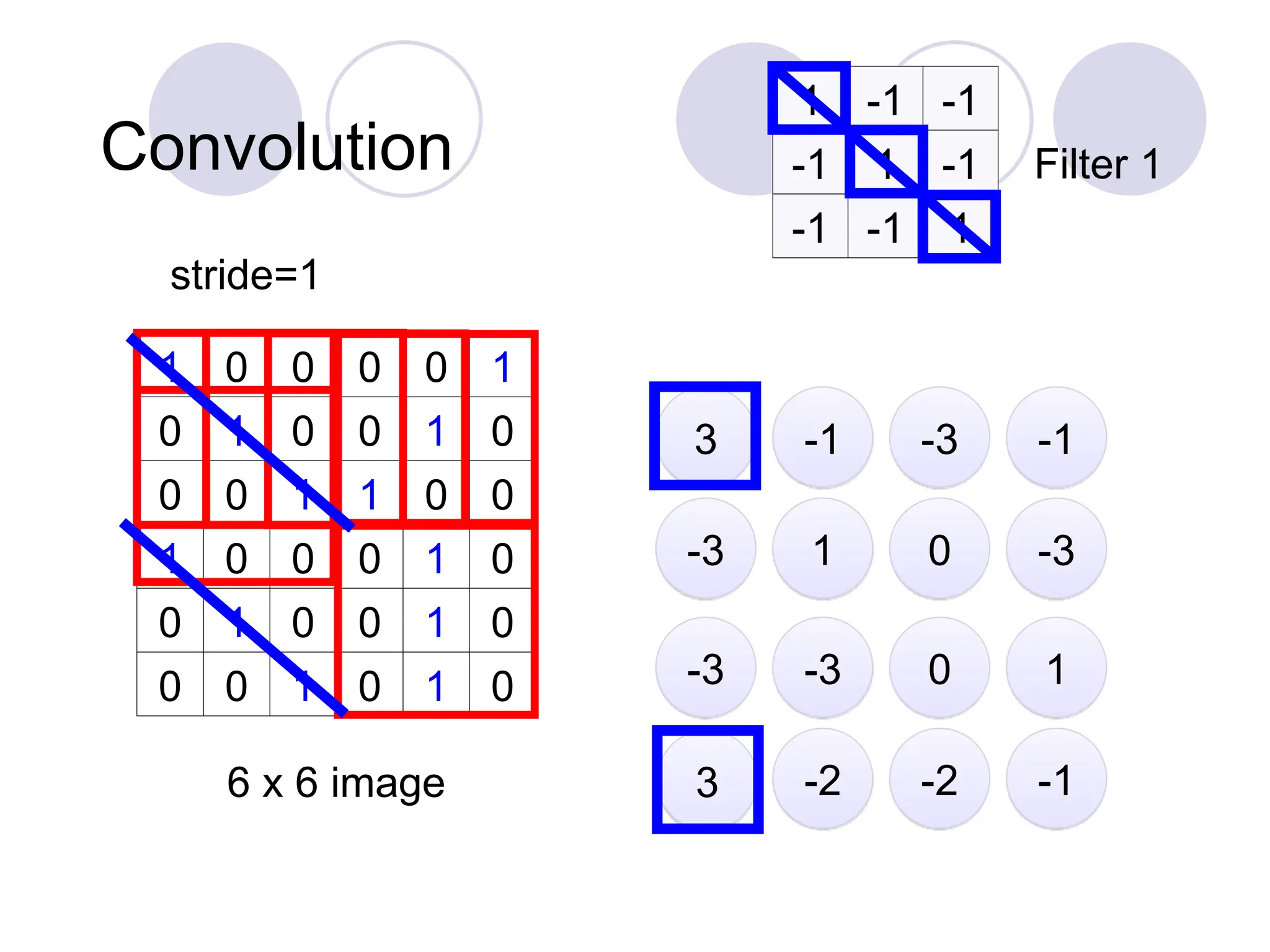
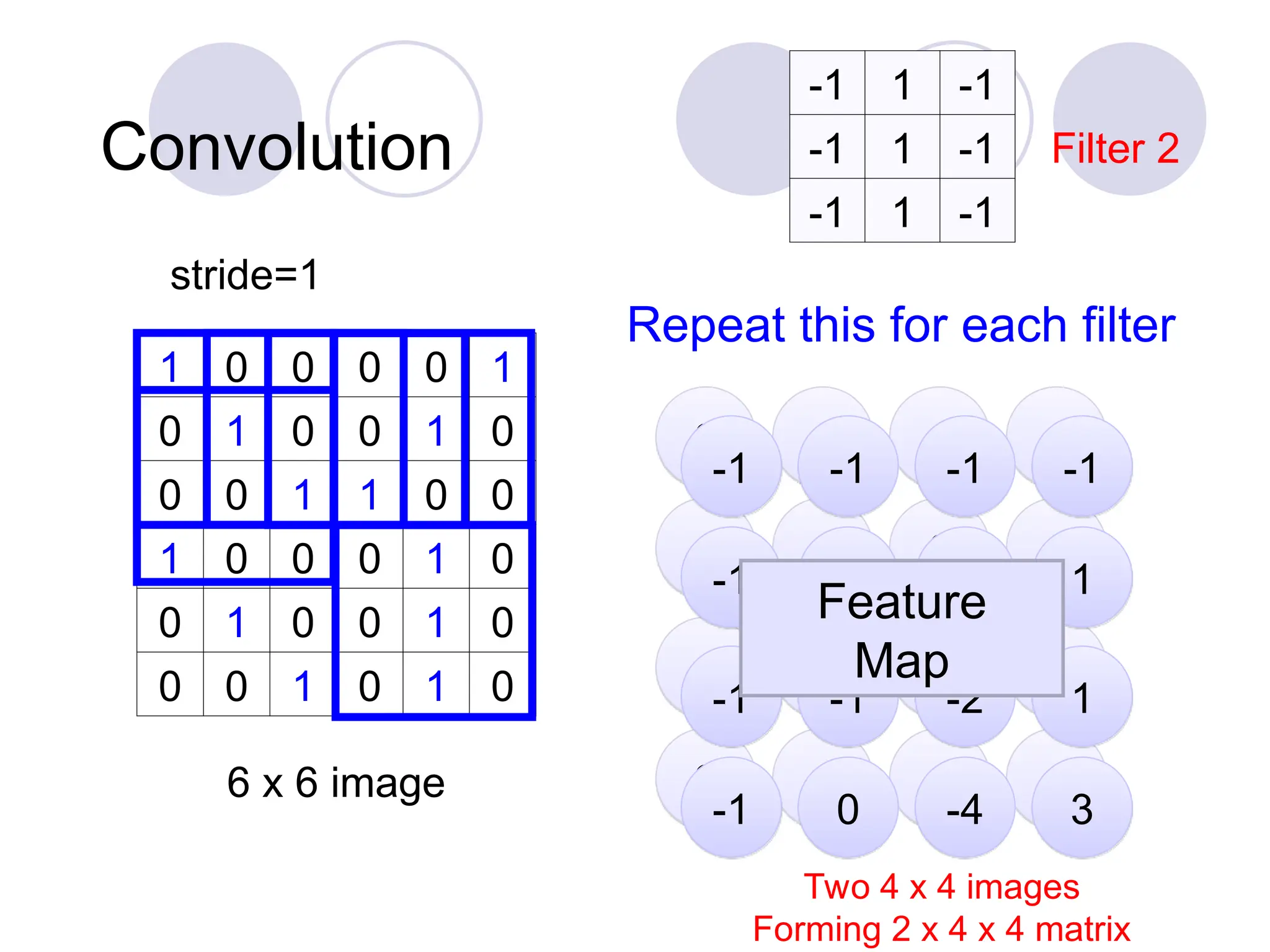
Convolution
1 0 00 0 1
0 1 0 0 1 0
0 0 1 1 0 0
1 0 0 0 1 0
0 1 0 0 1 0
0 0 1 0 1 0
6 x 6 image
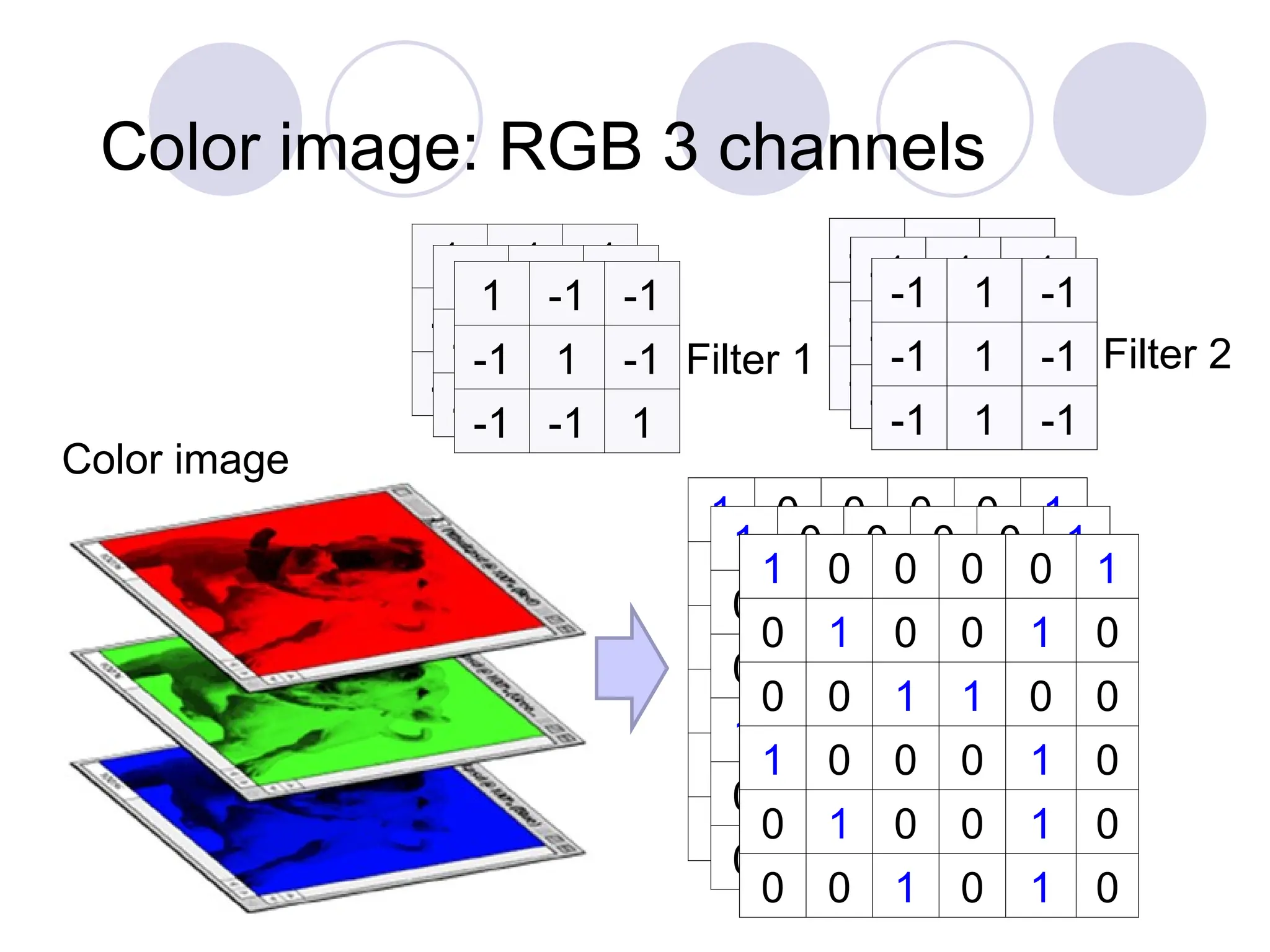
1 -1 -1
-1 1 -1
-1 -1 1
Filter 1
-1 1 -1
-1 1 -1
-1 1 -1
Filter 2
…
…
These are the network
parameters to be learned.
Each filter detects a
small pattern (3 x 3).
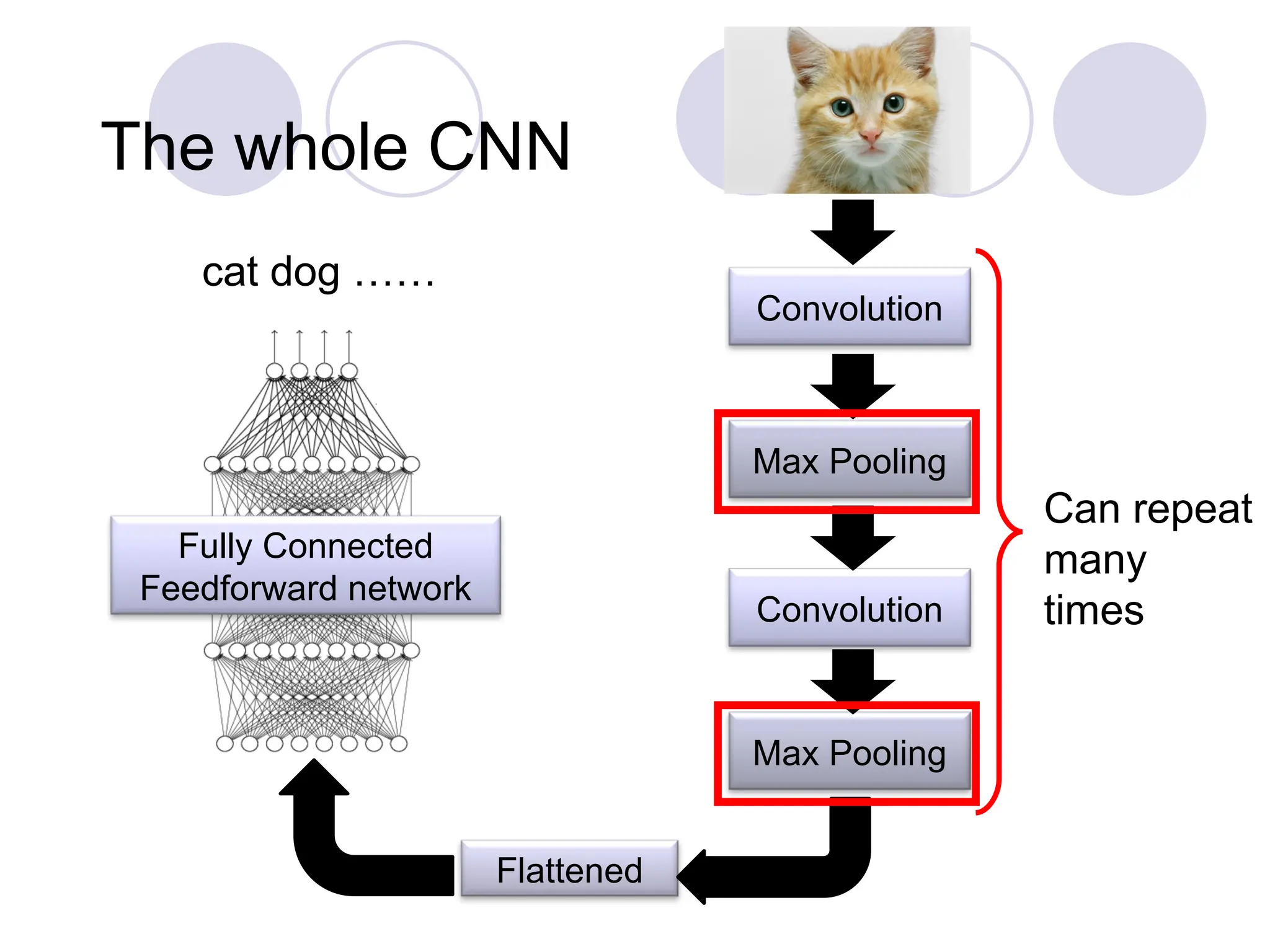
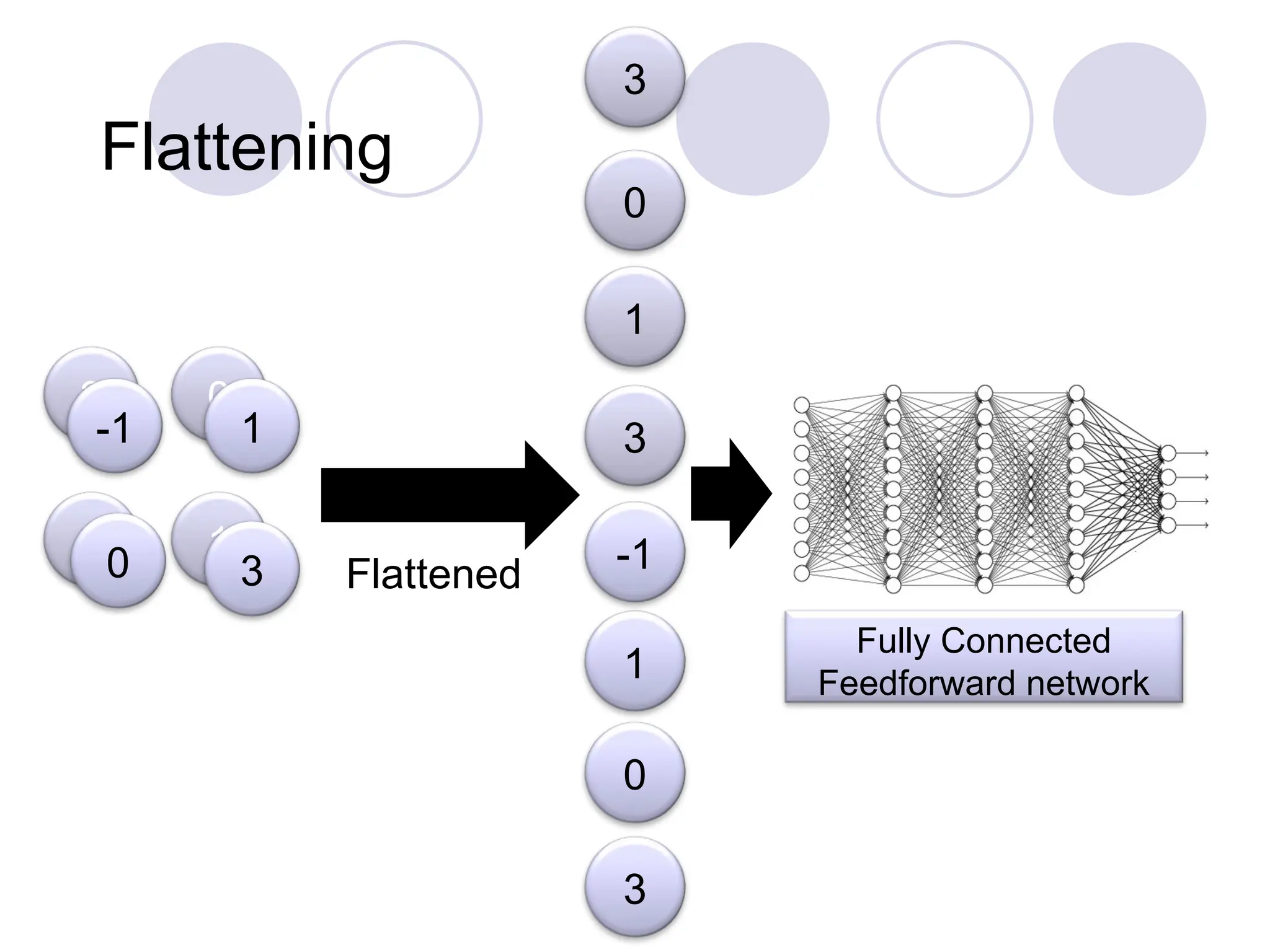
The whole CNN
FullyConnected
Feedforward network
cat dog ……
Convolution
Max Pooling
Convolution
Max Pooling
Flattened
Can repeat
many
times
17.
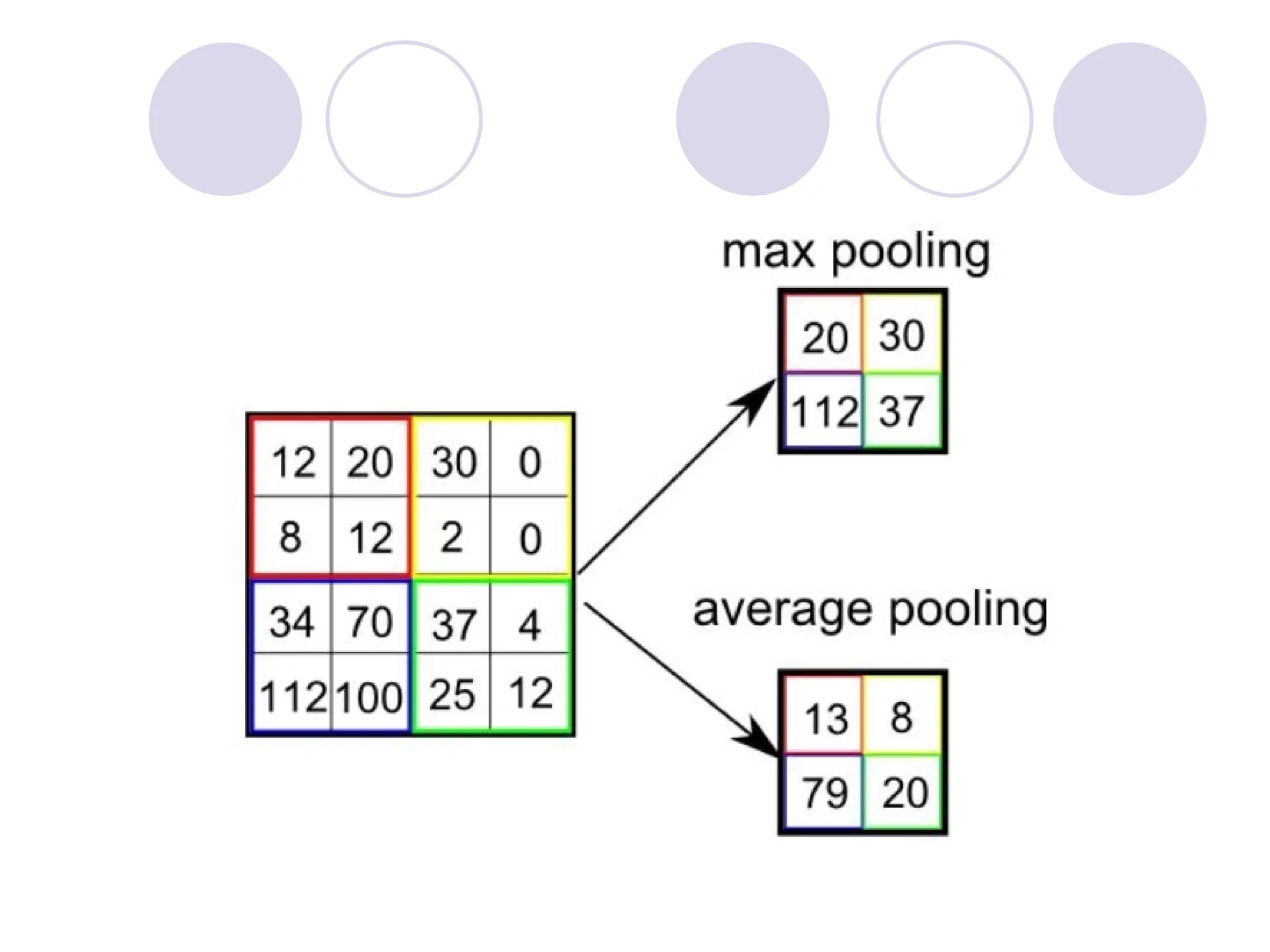
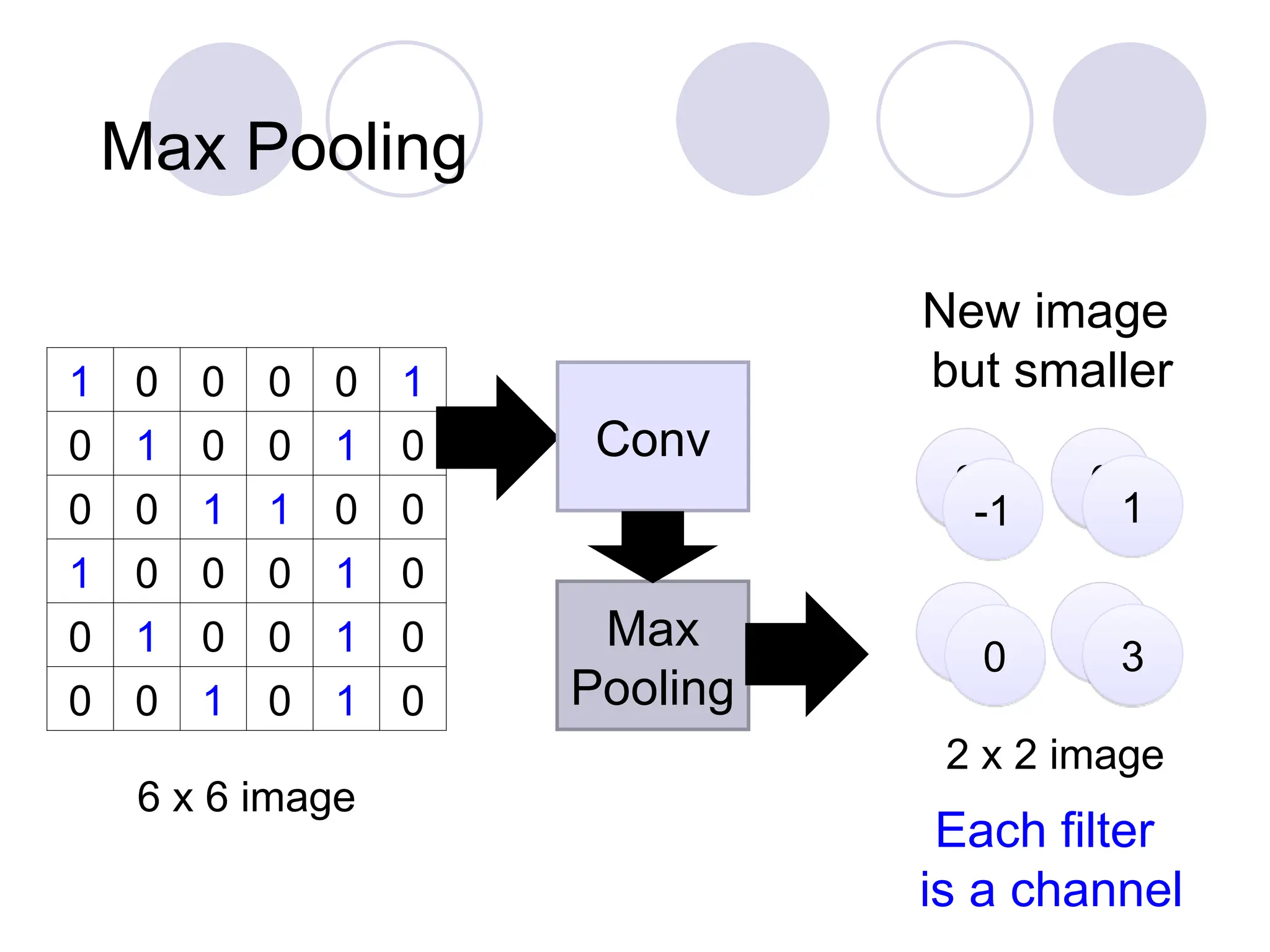
There are twotypes of Pooling: Max
Pooling and Average Pooling. Max
Pooling returns the maximum value from
the portion of the image covered by the
Kernel. On the other hand, Average
Pooling returns the average of all the
values from the portion of the image
covered by the Kernel.
Why Pooling
Subsampling pixelswill not change the object
Subsampling
bird
bird
We can subsample the pixels to make image smaller
fewer parameters to characterize the image
21.
A CNN compressesa fully connected
network in two ways:
Reducing number of connections
Shared weights on the edges
Max pooling further reduces the complexity
22.
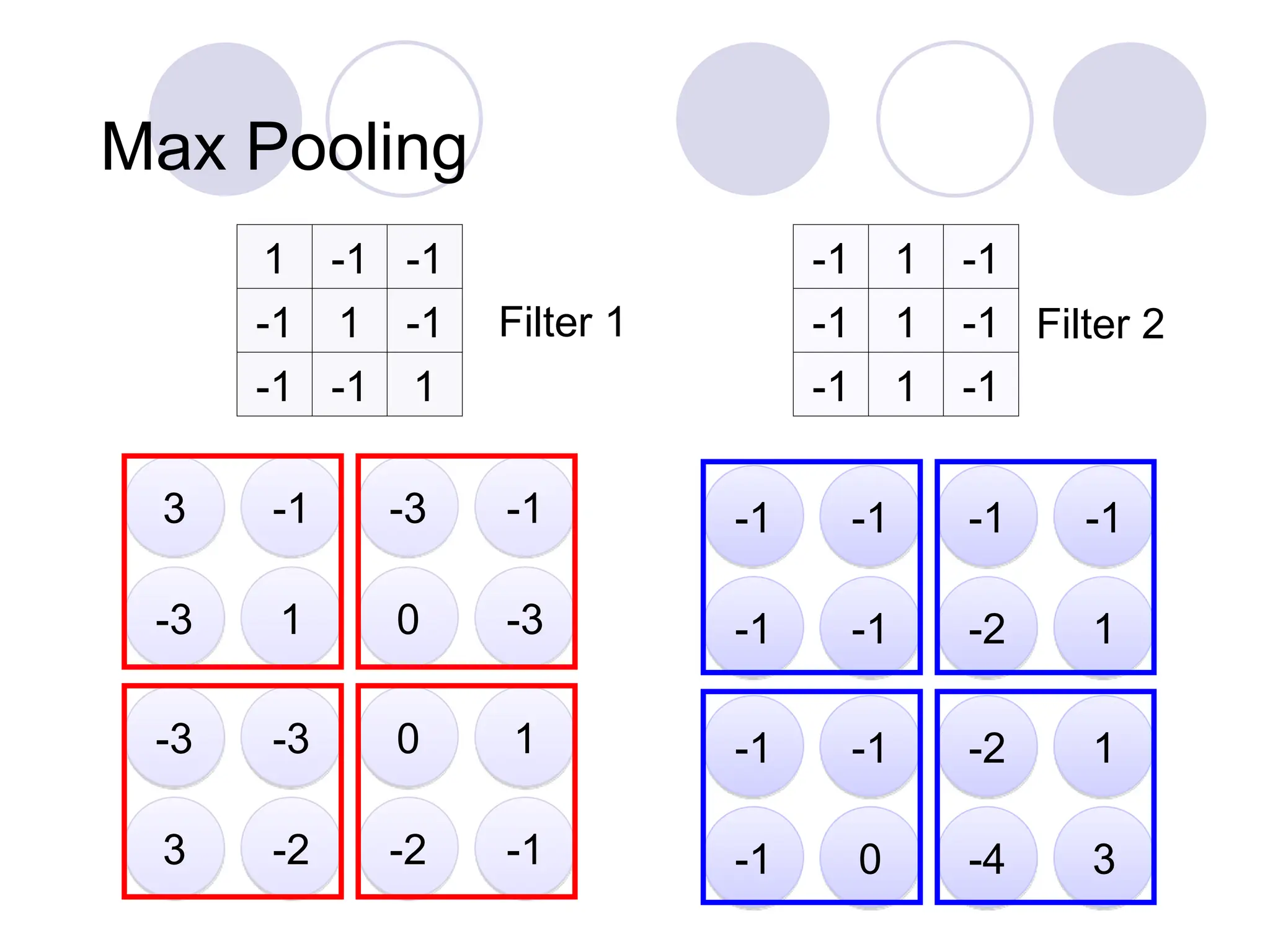
Max Pooling
1 00 0 0 1
0 1 0 0 1 0
0 0 1 1 0 0
1 0 0 0 1 0
0 1 0 0 1 0
0 0 1 0 1 0
6 x 6 image
3 0
1
3
-1 1
3
0
2 x 2 image
Each filter
is a channel
New image
but smaller
Conv
Max
Pooling
23.
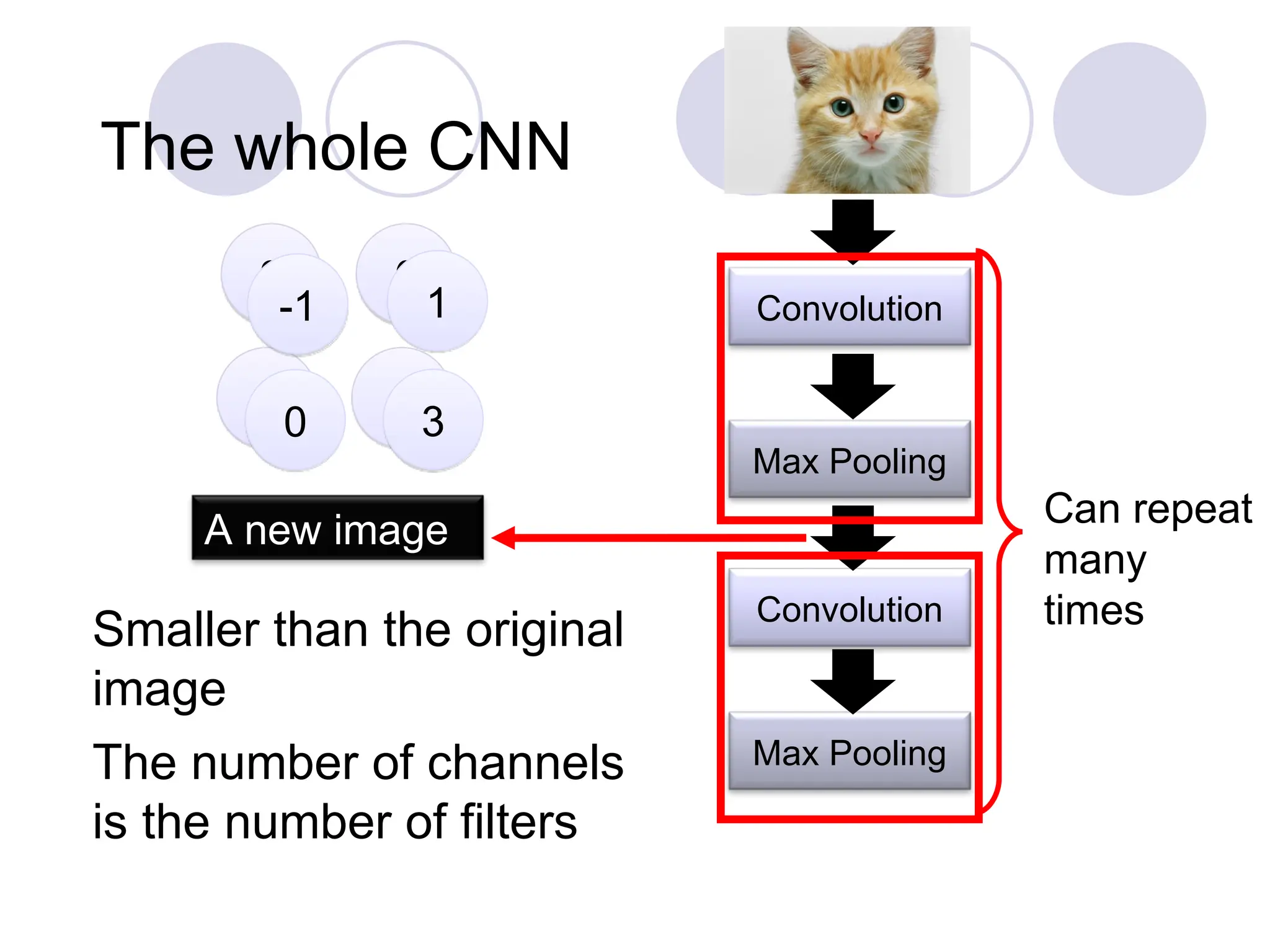
The whole CNN
Convolution
MaxPooling
Convolution
Max Pooling
Can repeat
many
times
A new image
The number of channels
is the number of filters
Smaller than the original
image
3 0
1
3
-1 1
3
0
24.
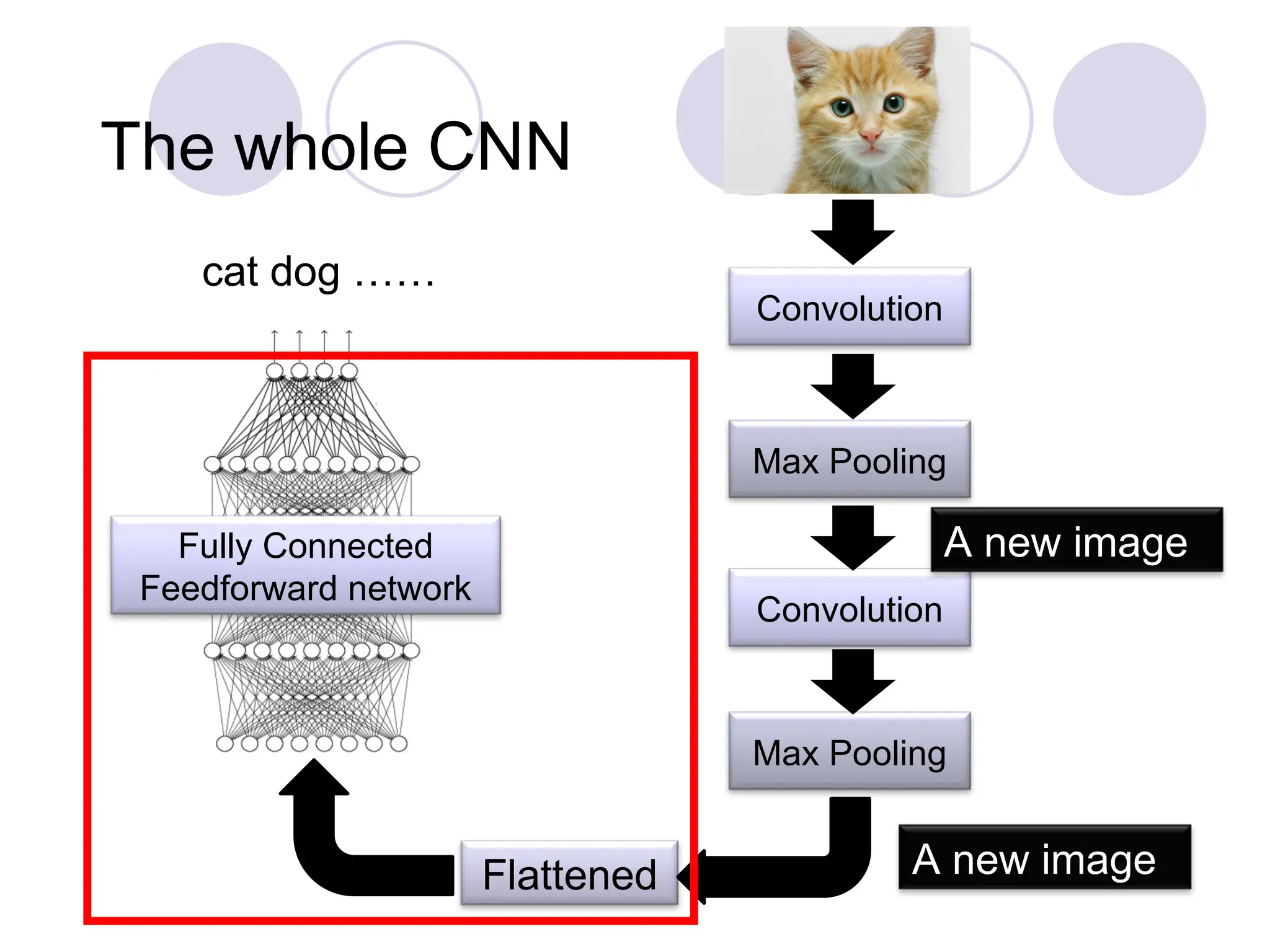
The whole CNN
FullyConnected
Feedforward network
cat dog ……
Convolution
Max Pooling
Convolution
Max Pooling
Flattened
A new image
A new image
25.
The flattened outputis fed to a feed-
forward neural network and
backpropagation is applied to every
iteration of training. Over a series of
epochs, the model is able to distinguish
between dominating and certain low-level
features in images and classify them using
the Softmax Classification technique.
There are variousarchitectures of CNNs available which have been key in
building algorithms which power and shall power AI as a whole in the
foreseeable future. Some of them have been listed below:
LeNet
AlexNet
VGGNet
GoogLeNet
ResNet
ZFNet
https://ch.mathworks.com/help/deeplearning/ug/pretrained-convolutional-neural
-networks.html
https://ch.mathworks.com/help/gpucoder/ug/load-pretrained-networks-for-code-
generation.html