Downloaded 69 times












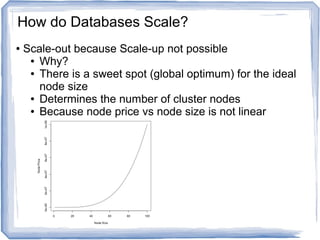


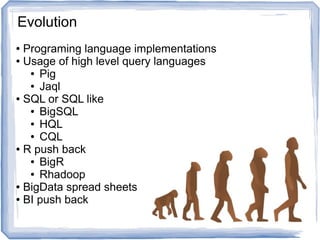


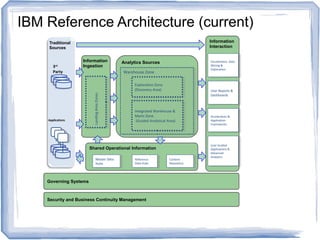
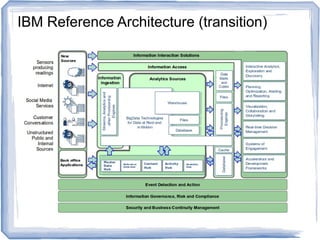
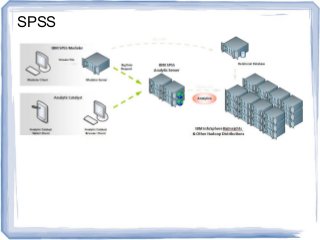
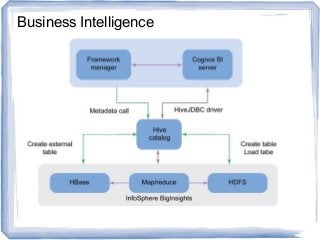


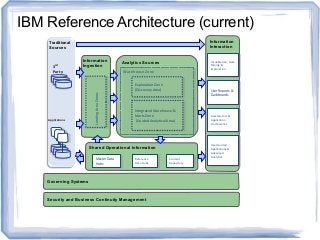
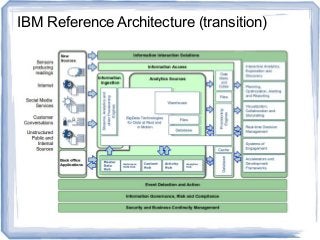

The document discusses reference architectures for enterprise big data use cases. It begins by providing background on how databases have scaled over time and the evolution of large-scale data processing. It then discusses the basic idea behind big data use cases, which is to use all available data regardless of structure or source. The document outlines some key requirements like fault tolerance, dynamic scaling, and processing all data types. It proposes an architectural approach using NoSQL databases and cloud computing alongside traditional data warehousing. Finally, it shares two reference architectures - the current IBM approach and a transitional approach.

































































































![How Big Brands are Taking Your Traffic in Alberta [Data Inside].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/howbigbrandsaretakingyourtrafficinalbertadatainside-260123180142-42d276f3-thumbnail.jpg?width=640&height=640&fit=bounds)