Download as PDF, PPTX




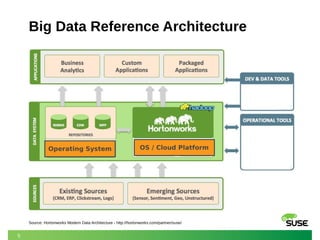
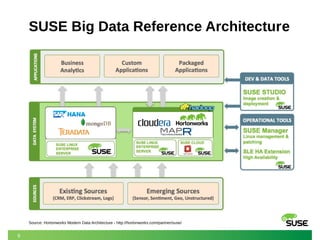
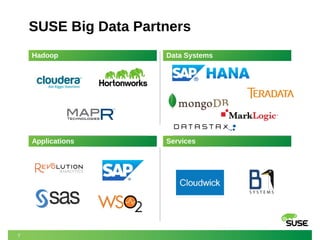
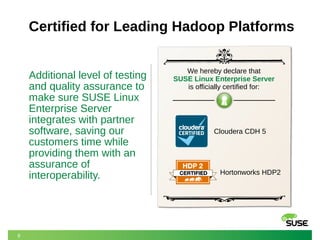






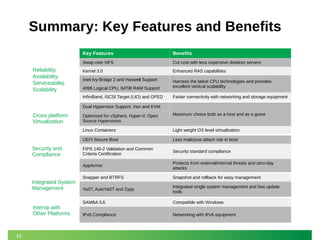










The document outlines SUSE's offerings and partnerships related to Hadoop and big data, highlighting its certified compatibility with leading Hadoop platforms. It emphasizes features such as reliability, scalability, security, and management capabilities of SUSE Linux Enterprise Server, making it a suitable foundation for Hadoop deployments. Additionally, it provides resources for best practices in deploying and managing Hadoop on SUSE systems.





















































































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)










