Download to read offline





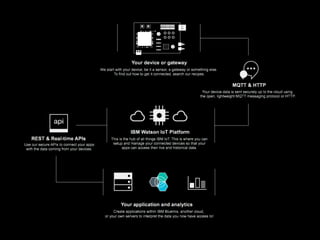
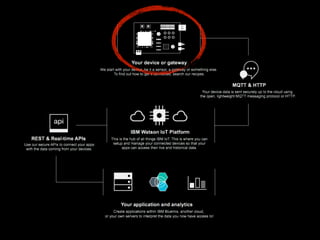
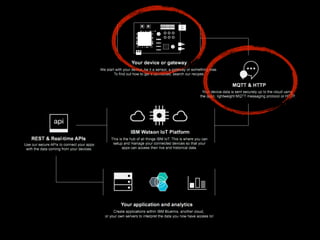
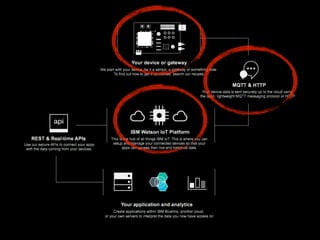
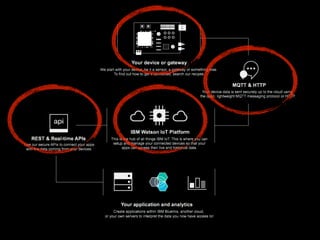
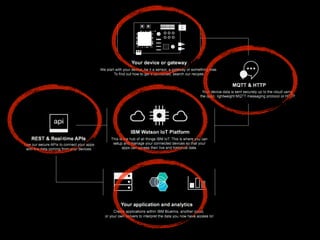
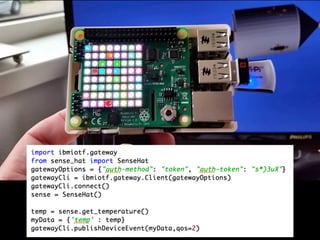




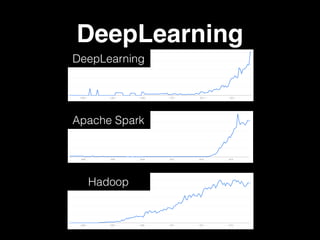

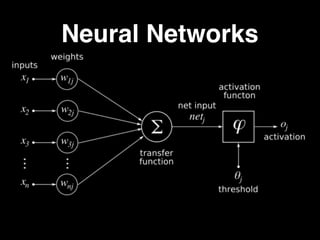
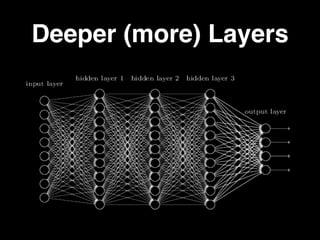





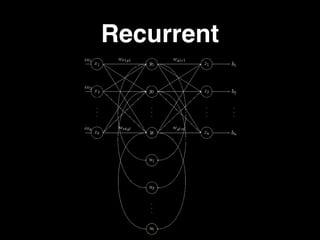
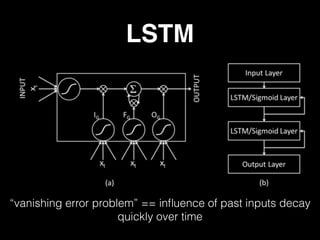





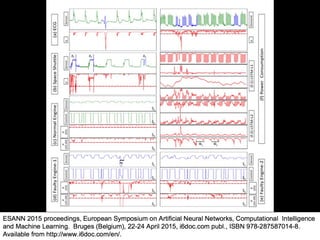
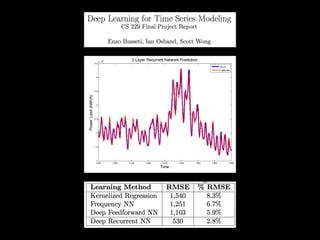



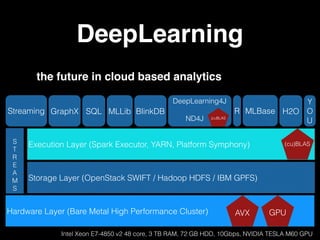
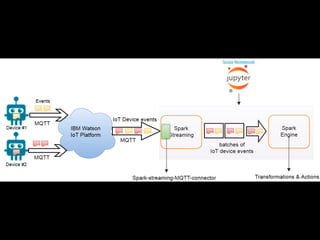

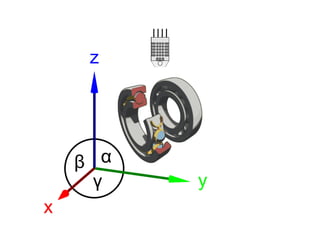
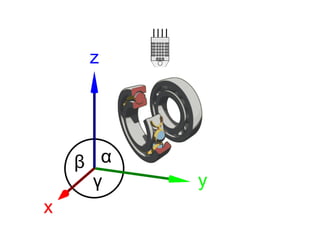
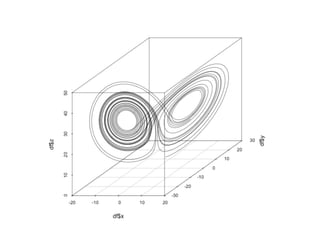
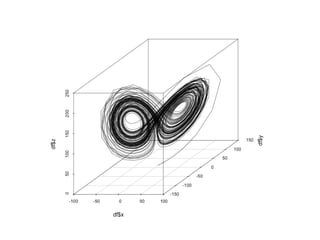
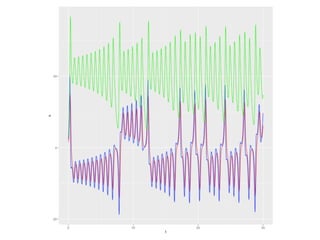
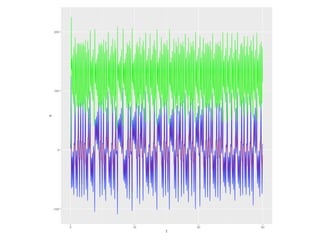
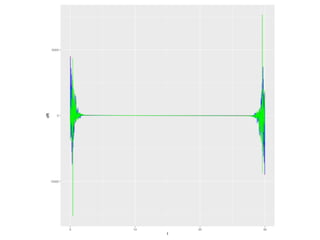
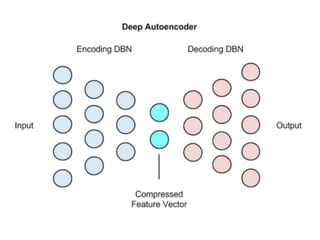

The document discusses the growth of connected devices and the Internet of Things. It then summarizes machine learning approaches for IoT data, including online learning which allows real-time model updates and historic learning which enables algorithmic improvements but requires high storage. Deep learning techniques for IoT like neural networks, convolutional neural networks, and LSTMs are also overviewed. Finally, the document presents challenges of deep learning and potential solutions like distributed hardware.




































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)


















