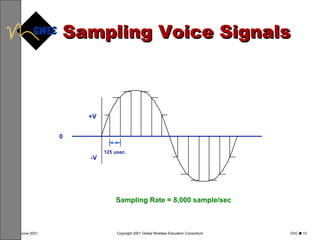
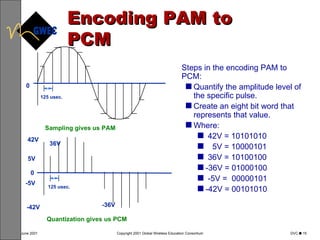
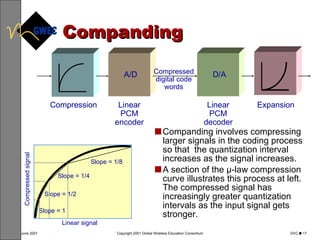
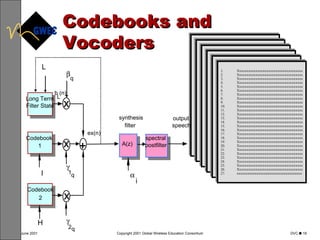
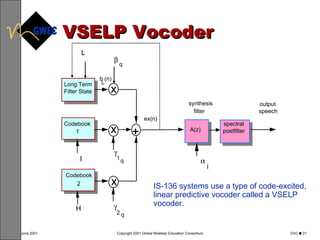
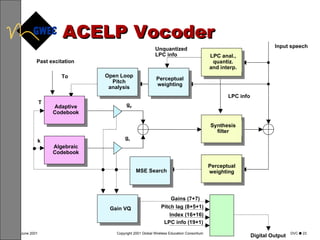
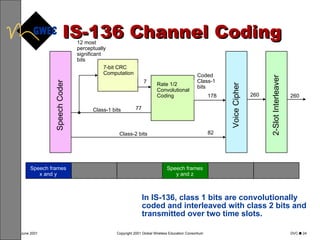
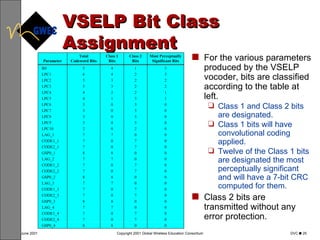
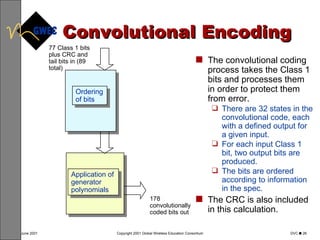
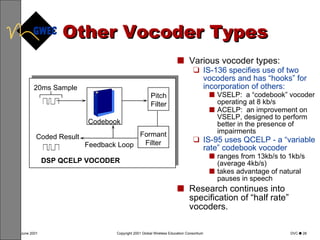
This document provides an overview of digital voice coding techniques used in wireless telecommunications, including pulse code modulation, linear predictive coding, and code excited linear prediction. It describes the objectives of the module as explaining analog to digital conversion, various vocoding methods like CELP, VSELP, and ACELP, and how these techniques allow more efficient use of frequency spectrum. The table of contents lists topics like PCM, linear predictive coders, and the various code excited linear prediction methods that will be covered.










































![[NUGU CONFERENCE 2019] 트랙 A-4 : Zero-shot learning for Personalized Text-to-S...](https://cdn.slidesharecdn.com/ss_thumbnails/a-4-191031082438-thumbnail.jpg?width=640&height=640&fit=bounds)


![[NUGU CONFERENCE 2019] 트랙 A-2 : NUGU call 적용 기술 및 서비스 소개](https://cdn.slidesharecdn.com/ss_thumbnails/a-2-191031082217-thumbnail.jpg?width=640&height=640&fit=bounds)



























































