Download as PDF, PPTX


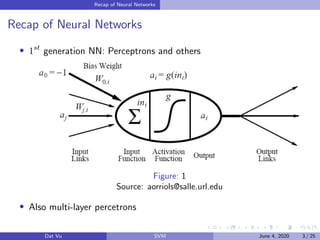
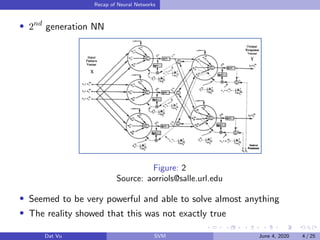

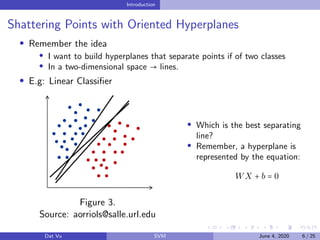
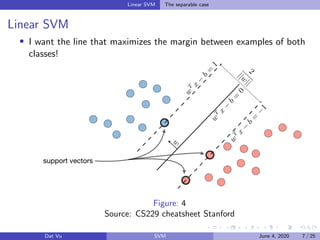





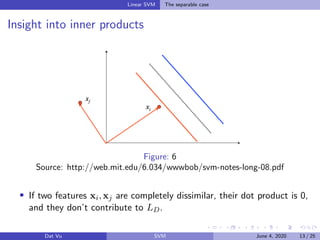
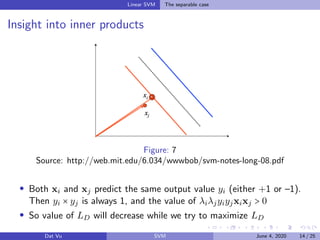
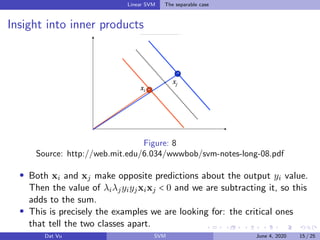

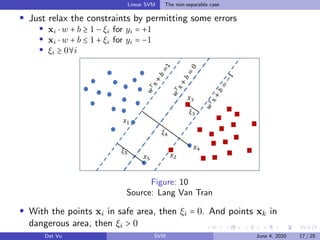

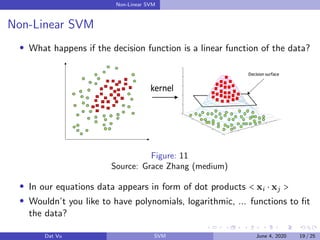



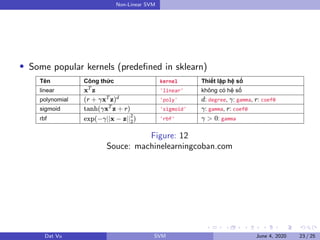


This document summarizes a presentation on support vector machines (SVMs). It begins with a recap of neural networks and then provides an introduction to SVMs, explaining how they use hyperplanes to separate data points of different classes. It covers linear SVMs for both separable and non-separable data, explaining how support vectors and slack variables handle non-separable cases. It concludes by discussing how kernels allow SVMs to find non-linear decision boundaries by projecting data into higher-dimensional spaces.



































































