Download to read offline











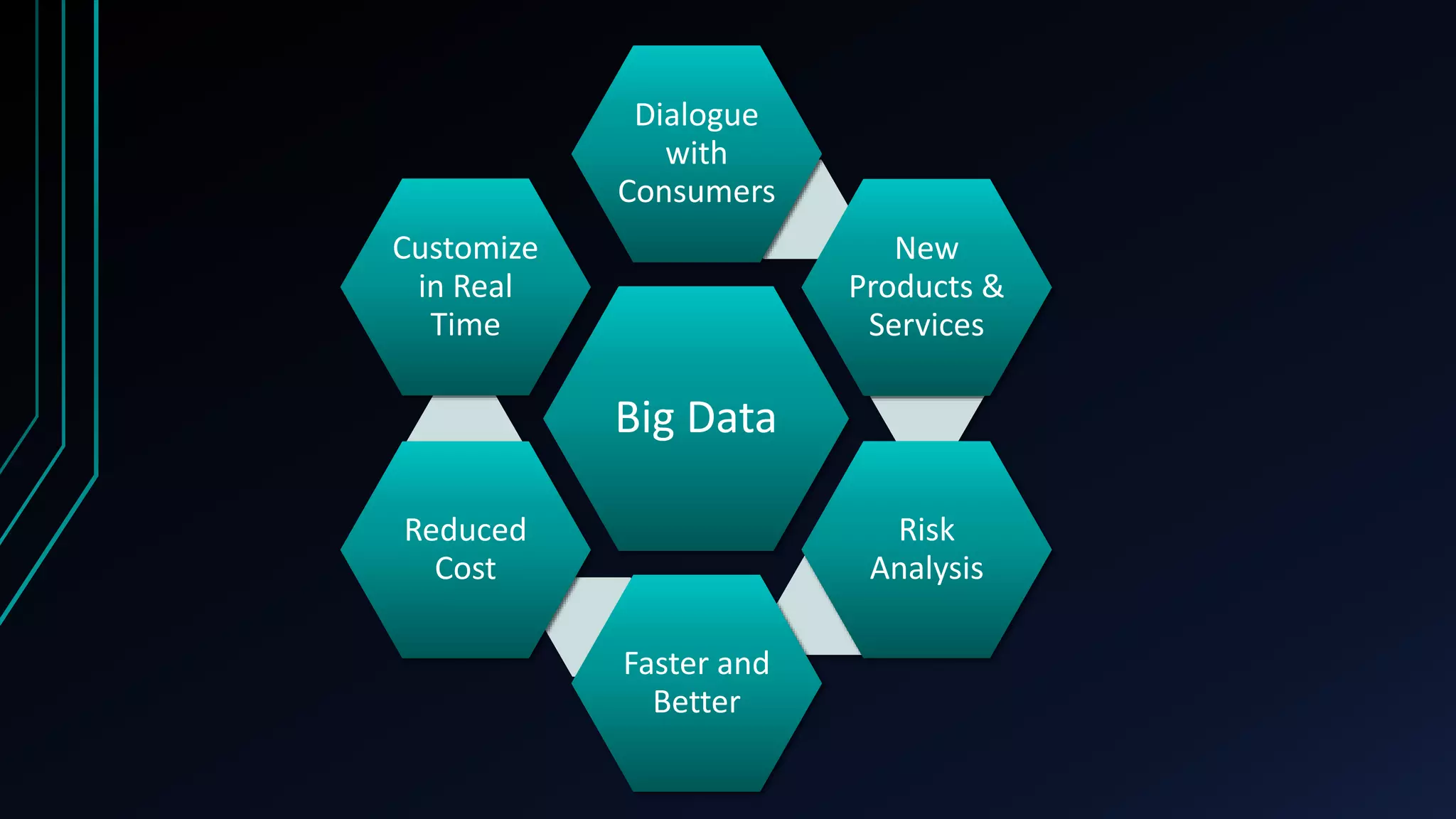

This document discusses real-time analytics in big data ecosystems. It describes how big data is generated at an enormous scale today and explains some key technologies like Apache Kafka, Apache Storm, Spark and Druid that can be used for real-time analytics. It also summarizes offerings from companies like Mindtree, Cognizant, Cybage and Persistent for big data solutions and services. Benefits of analyzing big data include enabling new products and services, better risk analysis, faster and improved decision making and reduced costs.


























































![Big_Data_ppt[1] (1).pptx](https://cdn.slidesharecdn.com/ss_thumbnails/bigdatappt11-230720100552-10b674be-thumbnail.jpg?width=640&height=640&fit=bounds)



![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)
















