Spark + S3+ R3 을 이용한
데이터 분석 시스템 만들기
VCNC 개발팀 김명보
AWS 한국 유저 그룹 (#awskrug)
2014.12.20
2.
발표자 소개
• 김명보
•VCNC에서 비트윈을 개발하고 있는 개발자
• 서버팀과 데이터 팀에서 잡다한 것들을 고치는 중
• 회사에서 AWS에 돈을 쓰는 것을 담당
3.
비트윈
• 커플들을 위한모바일 서비스
• 아이폰, 안드로이드 어플리케이션 제공
• 채팅, 기념일, 사진, 메모, 캘린더 기능 제공
• 전 세계에서 1000만+ 다운로드 (as of 2014.12)
• http://between.us
• http://engineering.vcnc.co.kr
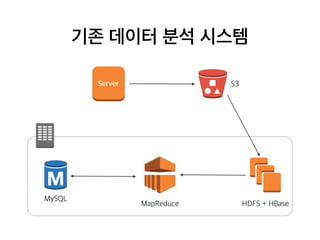
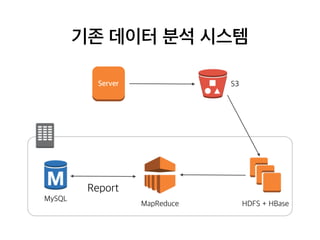
기존 데이터 분석시스템
S3Server
HDFS + HBaseMapReduce
MySQL
Upload log
8.
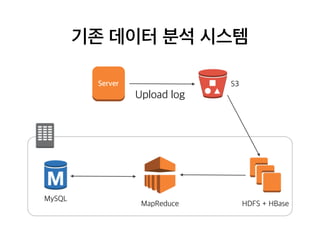
기존 데이터 분석시스템
S3Server
HDFS + HBaseMapReduce
MySQL
Download log
Bulk insert
9.
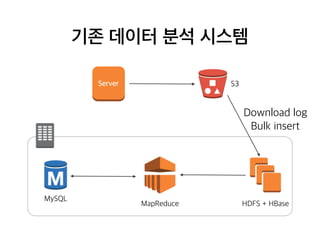
기존 데이터 분석시스템
S3Server
HDFS + HBaseMapReduce
MySQL
Analysis
10.
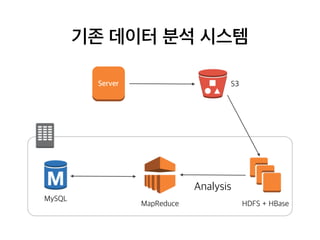
기존 데이터 분석시스템
S3Server
HDFS + HBaseMapReduce
MySQL
Report
11.
기존 데이터 분석시스템
• 매일 돌리는 주기적인 분석 작업과 On-demand 분석이 요구됨
• 서버가 Json 으로 로그를 남김
• {"who":{"address":"10.1xx.2xx.1xx","userId":"123456","userAgent":"Between 1.3.21
(SHV-E170K; Android 4.0.4; ko_KR)"},"what":
{"objectId":"12345_xxxx","parentId":"12345","objectType":"USER_THREAD_MESSAG
E","message":{"length":12}},"how":{"action":"ADD"},"when":{"timeMillis":
1356998401010},"version":1}
• 서버에서 하루에 한 번씩 S3로 업로드
• 회사 내에 데이터 분석용 HDFS + HBase + MapReduce 클러스터 존재
• 아침에 S3로부터 로그를 받아와서 HBase에 쏟아부음
• 분석을 돌려 결과를 MySQL을 저장함
12.
기존 데이터 분석시스템
• 처음엔 1시간 밖에 안 걸리고 좋았죠…
• 구성후 2년이 지나니 10시간도 넘게 걸림
• 지금부터 유저 수가 2배가 되면????
• 여러 대의 서버와 오픈 소스 스택을 직접 관리해야 함
• 갖가지 난관과 장애의 연속
13.
갖가지 장애 -하드웨어
• 하드 디스크
• 메모리
• 하둡 2.0.0 쯤에 corruption 이 퍼지는 버그 존재
• 메모리는 삼성!
• 네트워크
• 1G는 병목, 10G 는 비쌈
Spark 예제 -메세지 보낸 유저수
• val logs = sc.textFile(“s3n://my-logs/logs.2014-12-20*”)
• val msgLogs = logs.filter(_.contains(“ADD_MSG”))
• val msgUsers = msgLogs.map(_.toActionLog.userId).distinct
• val msgUserCounts = msgUsers.count
30.
PC 사용량 Cohort구하기
• val logs = sc.textFile(“s3n://logs-between/log.2014-*")
• val pcAAs = logs.filter(_.contains(“Between-PC”)).map(_.toAA)
• val pcUserDates = pcAAs.map(log => (log.userId, format.format(log.when.timeMillis)).distinct
• val pcUserFirstDate = pcUserDates.groupByKey().map(kv => (kv._1, kv._2.toList.sorted.head))
• val pcUserFirstDateActiveDate = pcUserFirstDate.join(pcUserDates)
• val result = pcUserFirstDateActiveDate.map((_._2, 1)).reduceByKey(_+_).sortByKey(true)
Spark + S3
•로그를 저장해 주는 HDFS layer를 따로 운영하지 않아도 됨
• s3n / s3 file system을 통해서 Hadoop에 잘 integration 되어 있음
• S3 <-> EC2 간 데이터 전송이 무료!
36.
Spark + S3
•EC2에서 S3의 접근 속도도 좋음
• r3.8xlarge (10GB NIC) 에서 200~330MBytes/sec 나옴
37.
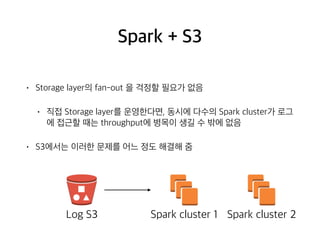
Spark + S3
•Storage layer의 fan-out 을 걱정할 필요가 없음
• 직접 Storage layer를 운영한다면, 동시에 다수의 Spark cluster가 로그
에 접근할 때는 throughput에 병목이 생길 수 밖에 없음
• S3에서는 이러한 문제를 어느 정도 해결해 줌
Spark cluster 1 Spark cluster 2Log S3
38.
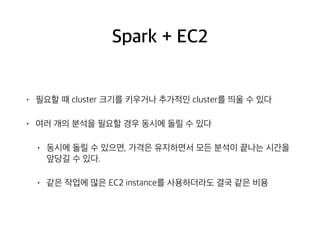
Spark + EC2
•필요할 때 cluster 크기를 키우거나 추가적인 cluster를 띄울 수 있다
• 여러 개의 분석을 필요할 경우 동시에 돌릴 수 있다
• 동시에 돌릴 수 있으면, 가격은 유지하면서 모든 분석이 끝나는 시간을
앞당길 수 있다.
• 같은 작업에 많은 EC2 instance를 사용하더라도 결국 같은 비용
39.
Spark + R3instance
• R3 instance
• 최근에 출시된, 메모리 optimized instance
• 메모리 244GB ( r3.8xlarge기준 )
• 320GB SSD x 2
• Shuffle 결과 임시 저장할 때 유리함
• Spark에 최적화된 instance type
40.
Spark + PlacementGroup
• Placement Group
• instance 간의 network latency가 낮아짐
• wide-dependency shuffle operation에서 유리함
41.
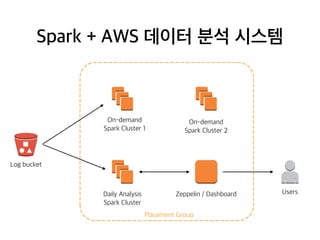
Spark + AWS데이터 분석 시스템
Log bucket
On-demand
Spark Cluster 1
On-demand
Spark Cluster 2
Daily Analysis
Spark Cluster
Placement Group
Zeppelin / Dashboard Users
42.
Spark로 옮긴 후…
• 하루치 분석 10시간 -> 1시간 내외로 감소
• 한 번 Cache 해서 iterative 하게 돌 수 있음
• 하드웨어 관리와 여러 스택의 소프트웨어 관리의 괴로움에서 벗어남
• HDFS/HBase/MapReduce -> Spark
• In-house cluster에 비해서 순수 비용은 비슷하거나 다소 비쌀듯
• 훨씬 다양한 시도들이 가능해 짐
43.
Spark로 옮긴 후…
• 1년치 데이터에 대해서 분석을 해보고 싶어!
• 과거에는 당일 분석을 중단시키면서 오래 걸리는 분석을 돌리기 어려움
• 현재는 당일 분석과 시간이 오래 걸리는 분석을 동시에 실행 가능
• 비트윈의 버그/이슈 추적에 큰 도움이 됨
• 어떤 유저가 앱이 로그아웃 되었다는 데 이유를 모르겠다
• 서버의 버그 + 유저의 3달 전의 행동에 의해서 생긴 문제
• 3달 치의 해당 유저의 행동 로그와 Exception 로그를 비교 분석하여 원인 발견
• 진입 장벽이 낮아져 더 많은 개발 팀원들이 데이터 분석에 관심을 가지기 시작함
Spark Tips
• Shuffle할 때 생기는 임시 저장 파일들이 개수가 엄청 많이 생길 수 있음
• 디스크는 남는데 inode 가 모자란 사태 발생
• mkfs.ext4 -i 4096 같은 옵션으로 커버
• mdadm 으로 SSD 두 개 묶어서 Spark temp 폴더에 mount
46.
Spark Tips
• S3에서 읽어와서 처리할 경우 파일이 비슷한 크기로 쪼개져 있는 게 유리
• 크기가 100, 100, 100, 20, 20 인 로그들로 저장되어 있는 것보다 10
짜리 32개가 있는게 유리함
• core를 모두 사용하자
• 원래 서버에서 하루에 한 번 로그를 업로드하던 것을 한 시간에 한 번으로
변경함
47.
Spark Tips -Zeppelin
• 데이터 분석을 위한 웹기반 노트북 + 데이터 visualization tool
• Spark 및 Spark SQL과 연동해서 편리하게 데이터 처리, 그래프 그리는 작
업 등을 진행 할 수 있음
• 따로 대쉬보드를 만들 필요가 없어짐
• Tajo등 다른 데이터 분석 툴과의 통합도 진행중










































![[KAIST 채용설명회] 데이터 엔지니어는 무슨 일을 하나요?](https://cdn.slidesharecdn.com/ss_thumbnails/temp-180502031907-thumbnail.jpg?width=640&height=640&fit=bounds)
![[236] 카카오의데이터파이프라인 윤도영](https://cdn.slidesharecdn.com/ss_thumbnails/236-161025031702-thumbnail.jpg?width=640&height=640&fit=bounds)
![[NDC18] 야생의 땅 듀랑고의 데이터 엔지니어링 이야기: 로그 시스템 구축 경험 공유 (2부)](https://cdn.slidesharecdn.com/ss_thumbnails/ndc2018-2-180430180517-thumbnail.jpg?width=640&height=640&fit=bounds)
![[NDC18] 야생의 땅 듀랑고의 데이터 엔지니어링 이야기: 로그 시스템 구축 경험 공유](https://cdn.slidesharecdn.com/ss_thumbnails/ndc2018-1-180430181759-thumbnail.jpg?width=640&height=640&fit=bounds)





![[MLOps KR 행사] MLOps 춘추 전국 시대 정리(210605)](https://cdn.slidesharecdn.com/ss_thumbnails/mlops-basic-210605064957-thumbnail.jpg?width=640&height=640&fit=bounds)




![[215] Druid로 쉽고 빠르게 데이터 분석하기](https://cdn.slidesharecdn.com/ss_thumbnails/215druid-181012071910-thumbnail.jpg?width=640&height=640&fit=bounds)







![[우리가 데이터를 쓰는 법] 모바일 게임 로그 데이터 분석 이야기 - 엔터메이트 공신배 팀장](https://cdn.slidesharecdn.com/ss_thumbnails/5-160415084345-thumbnail.jpg?width=640&height=640&fit=bounds)



![[Aurora事例祭り]Amazon Aurora を使いこなすためのベストプラクティス](https://cdn.slidesharecdn.com/ss_thumbnails/amazonauroratips-170307140000-thumbnail.jpg?width=640&height=640&fit=bounds)


































![[AWS Hero 스페셜] 서버리스 기반 검색 서비스 구축하기 - 이상현(스마일벤처스) :: AWS Community Day Online ...](https://cdn.slidesharecdn.com/ss_thumbnails/aa-201017071333-thumbnail.jpg?width=640&height=640&fit=bounds)

![[AWS Hero 스페셜] Amazon Personalize를 통한 개인화/추천 서비스 개발 노하우 - 소성운(크로키닷컴) :: AWS C...](https://cdn.slidesharecdn.com/ss_thumbnails/amazonpersonalize-201017065918-thumbnail.jpg?width=640&height=640&fit=bounds)



