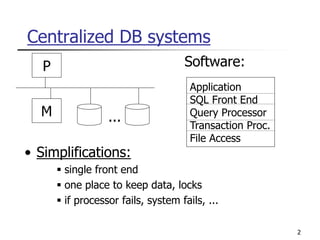
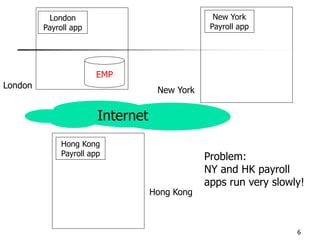
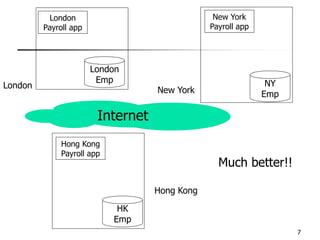
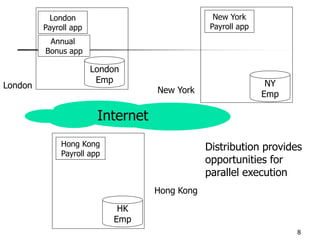
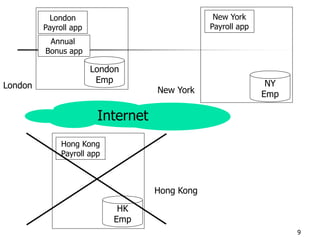
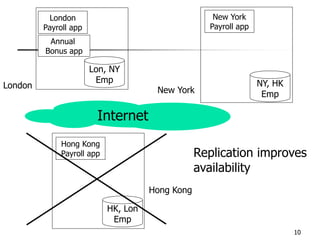
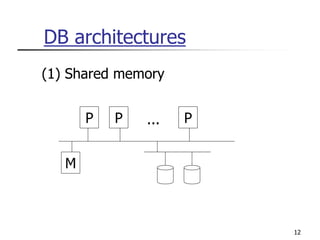
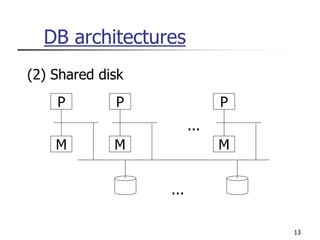
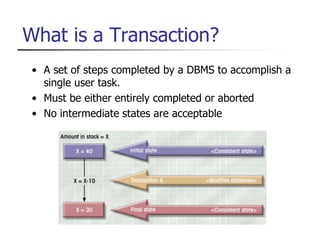
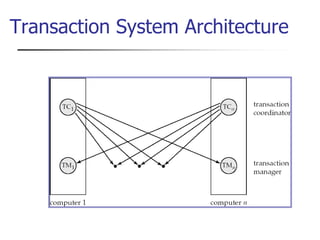
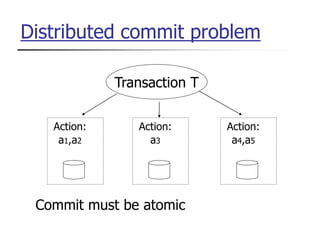
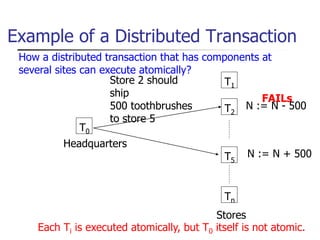
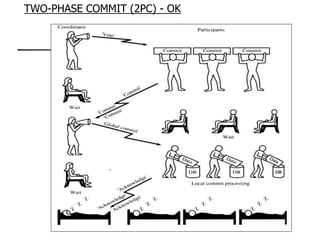
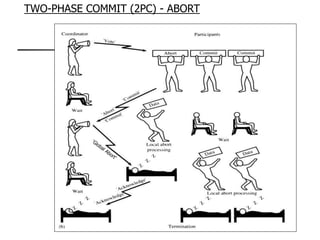
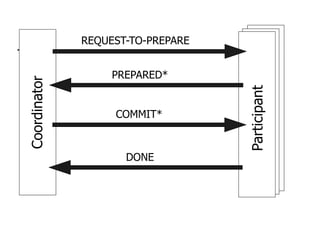
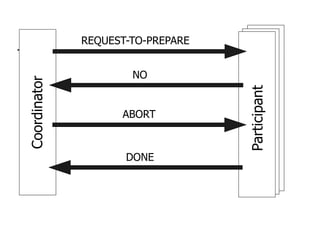
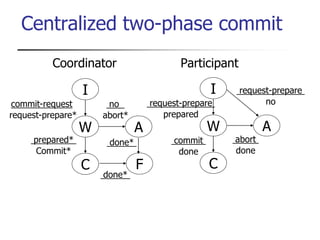
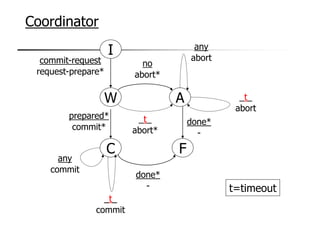
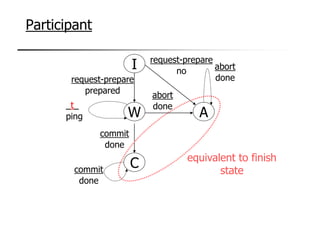
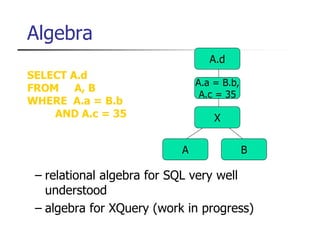
This document provides an overview of distributed database management systems, detailing their architectures, advantages, and challenges in terms of design, replication, and fragmentation. It compares centralized and distributed systems, emphasizing the need for parallel execution and efficient data access patterns, while also discussing transaction management and query processing in a distributed environment. The text highlights both the benefits, such as improved availability and local autonomy, and the drawbacks, including architectural complexity and security concerns.
















































































![7.__Developing_a_Research_Proposal[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/7-260131073037-df92dd7d-thumbnail.jpg?width=640&height=640&fit=bounds)






