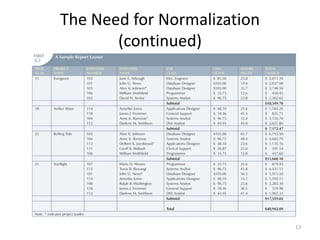
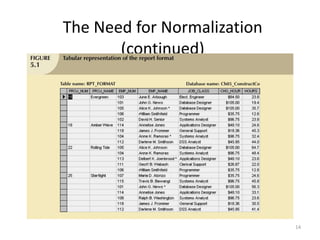
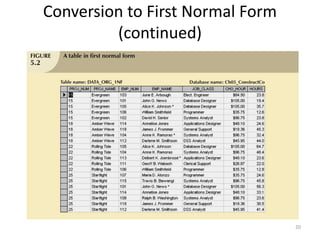
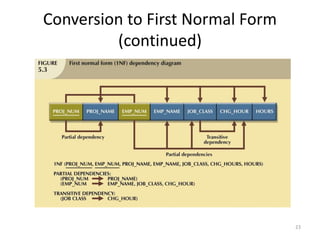
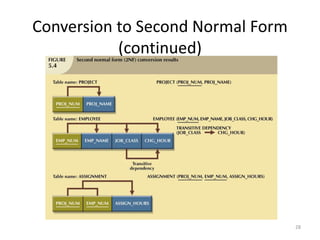
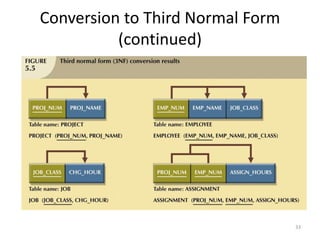
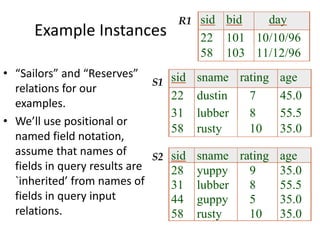
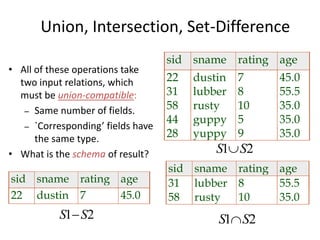
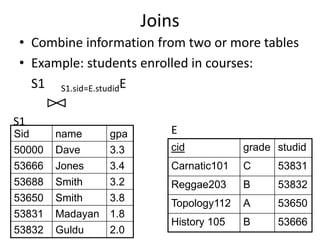
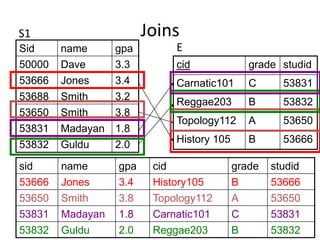
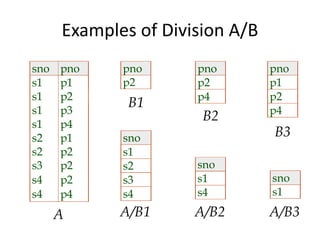
The document provides an overview of relational database management systems (RDBMS) and the relational data model. It discusses three key components of the relational model: the data structure which organizes data into tables with rows and columns, data manipulation using SQL, and data integrity rules. The document then covers database normalization through third normal form to reduce data redundancy and anomalies. It provides examples of converting tables from lower to higher normal forms through identifying functional dependencies.