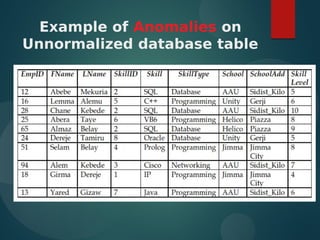
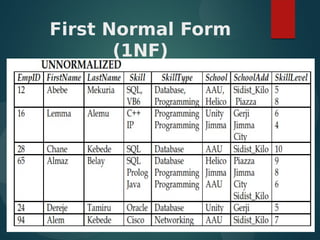
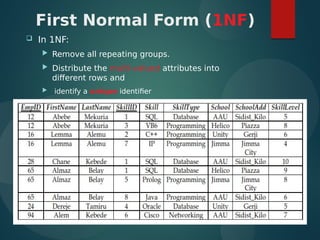
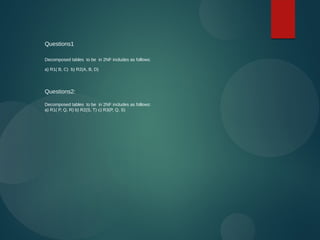
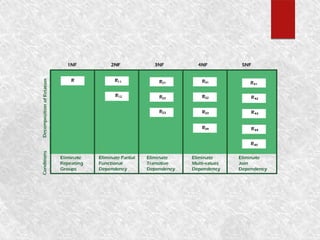
The document discusses normalization and relational algebra. It defines normalization as a process of structuring a database into tables to reduce data redundancy and inconsistencies. The document covers various normal forms including 1st normal form (1NF), 2nd normal form (2NF), and 3rd normal form (3NF). It defines functional dependencies and different types of dependencies and anomalies. Examples are provided to illustrate how to determine the normal forms of relations and decompose relations to higher normal forms by removing dependencies.