Downloaded 15 times





















![HOME
2nd Normal Form Example
Consider the following example:
This table has a composite primary key [Customer ID, Store ID]. The
non-key attribute is [Purchase Location]. In this case, [Purchase
Location] only depends on [Store ID], which is only part of the primary
key. Therefore, this table does not satisfy second normal form.](https://image.slidesharecdn.com/year11dataproc1sttermm-151103081958-lva1-app6892/85/Year-11-DATA-PROCESSING-1st-Term-22-320.jpg)
![HOME
To bring this table to second
normal form, we break the table
into two tables, and now we
have the following:
What we have done is to remove
the partial functional
dependency that we initially had.
Now, in the table [TABLE_STORE],
the column [Purchase Location]
is fully dependent on the primary
key of that table, which is [Store
ID].](https://image.slidesharecdn.com/year11dataproc1sttermm-151103081958-lva1-app6892/85/Year-11-DATA-PROCESSING-1st-Term-23-320.jpg)

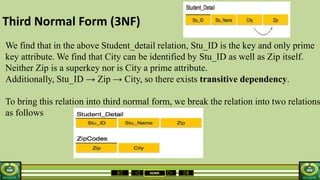















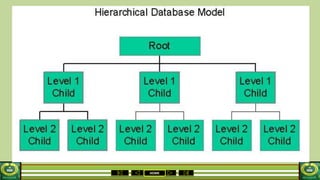


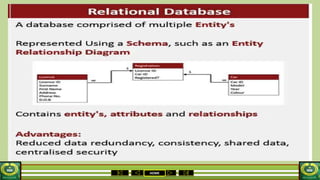
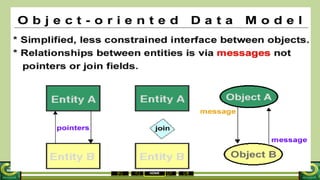
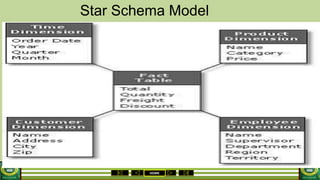






















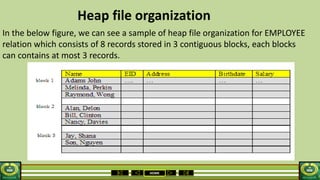
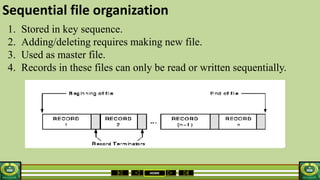
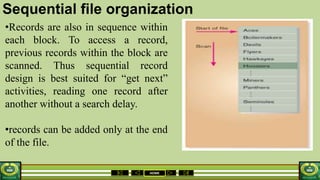




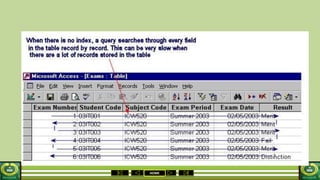





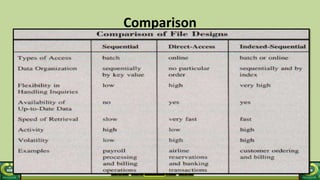


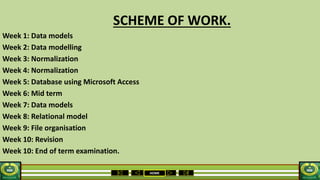
The document provides an overview of the topics covered in a data processing course over 10 weeks. Week 1 covers data models and data types. Week 2 discusses data modelling and the components and importance of data models. Weeks 3 and 4 focus on database normalization, including 1NF, 2NF, 3NF and denormalization. Week 5 introduces the star schema model. Weeks 6-8 cover using Microsoft Access and relational data models. Week 9 reviews file organization techniques. Week 10 is for revision and exams.















































