Download to read offline




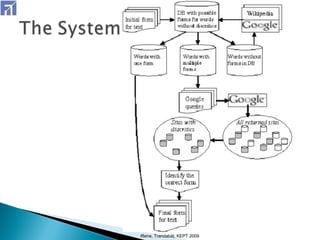











The document describes a 7-step method for restoring diacritics to Romanian text using web-found contexts. Step 1 splits text into words and sentences. Step 2 searches a database for possible diacritic variants of words. Steps 3-5 build queries to search the web, download relevant pages, and identify files with correct diacritics. Step 6 identifies the most appropriate form for words with multiple forms. Step 7 improves context using backward, forward, and maximization rules. The method achieved accuracy similar to existing systems but has the advantage of using free resources and tools.































![Ipa pronunciation session[1]](https://cdn.slidesharecdn.com/ss_thumbnails/ipapronunciationsession1-100503153304-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)











































