Download as PDF, PPTX





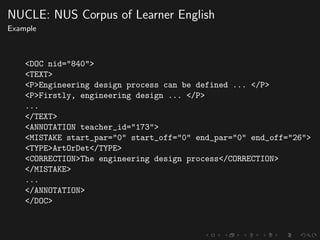

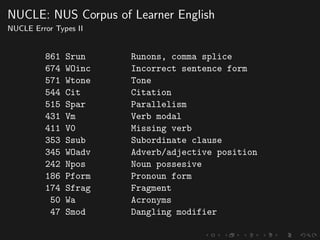

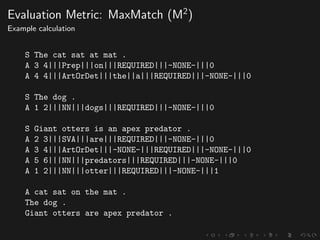
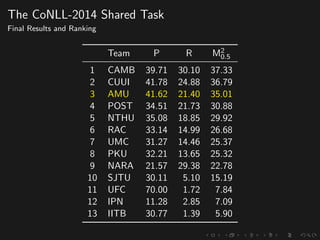


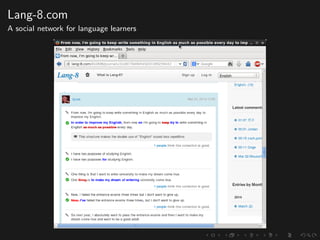
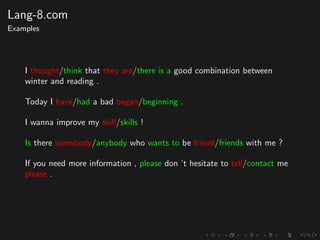
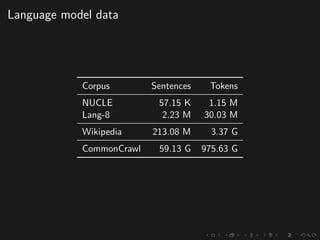
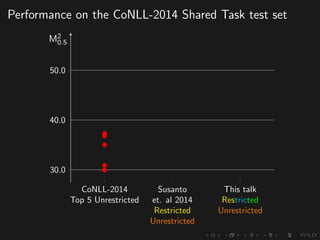
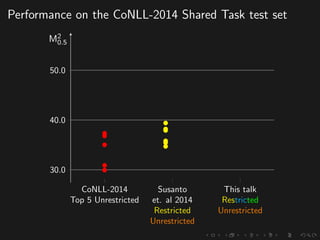
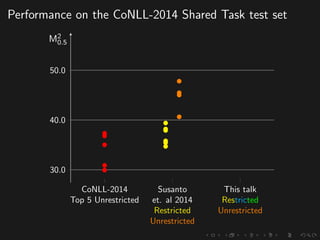
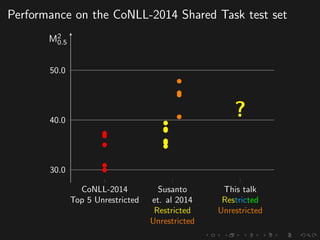



















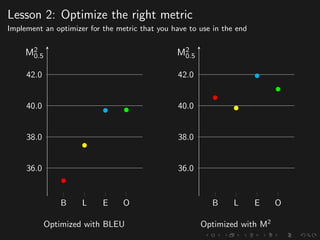
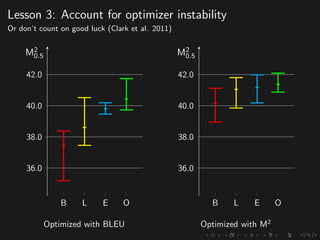
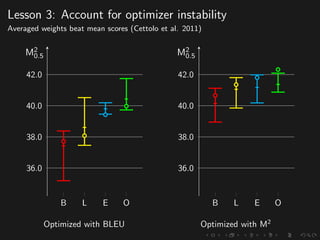
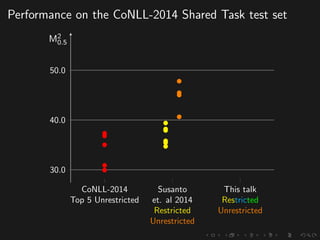
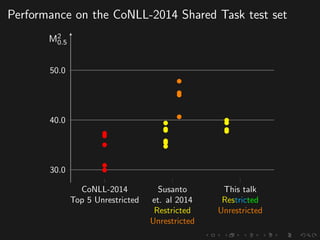
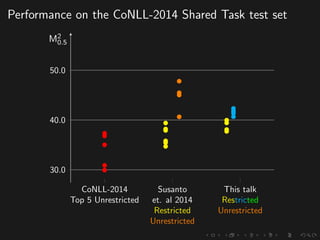





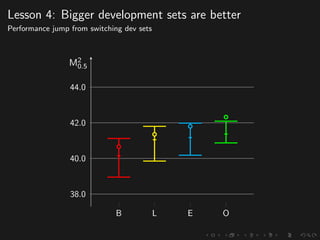
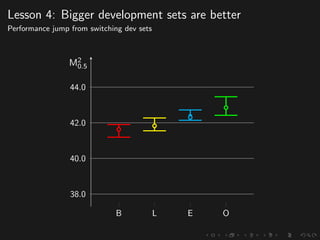
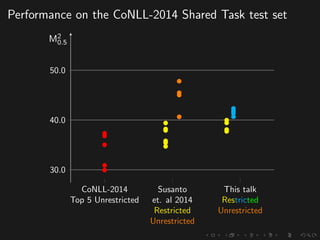
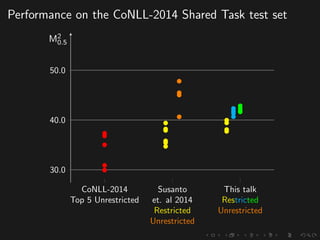
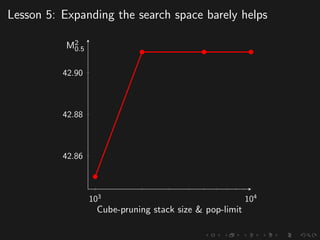
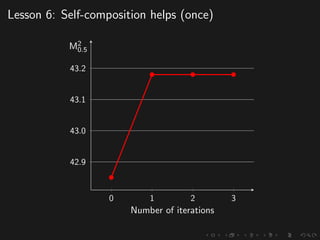



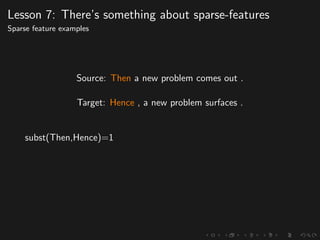



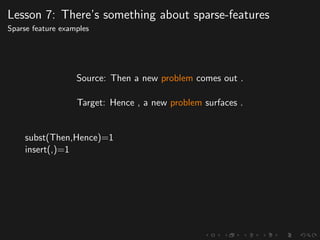
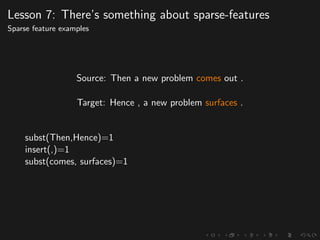








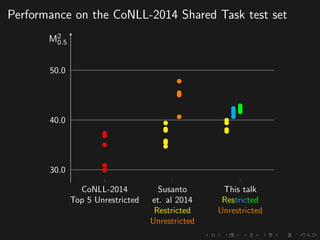
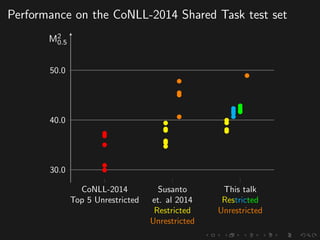



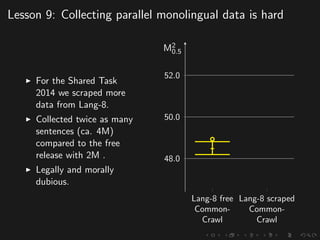
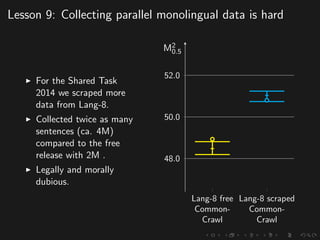
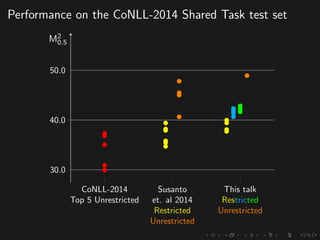
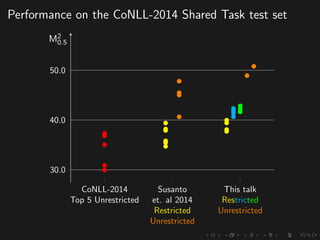




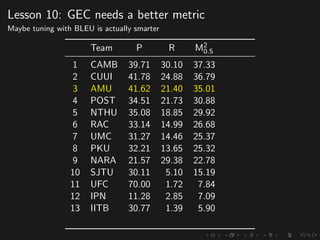
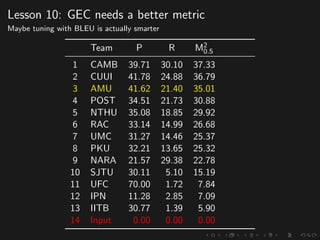
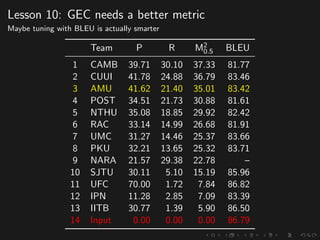
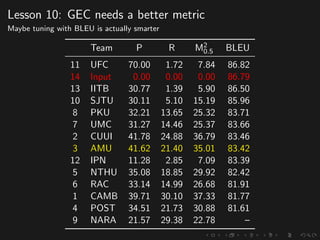











The document discusses advancements in grammatical error correction (GEC) for English as a second language (ESL) learners, detailing the evolution of the CONLL shared tasks and participation from various teams. It presents the NUCLE corpus, evaluation metrics like MaxMatch, system combinations, and lessons learned from the 2014 shared task, emphasizing the importance of feature engineering and large training datasets. Key takeaways include optimizing metrics for GEC systems and the significance of task-specific features in improving correction strategies.
















![[Paper Introduction] Translating into Morphologically Rich Languages with Syn...](https://cdn.slidesharecdn.com/ss_thumbnails/mt-study-20150917-151015052123-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
































































![谷歌留痕技术 [ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130174328-3833018c-thumbnail.jpg?width=640&height=640&fit=bounds)




