Download as PDF, PPTX














![Regular Expressions
Simplest regex: [^s]+
More advanced regex:
w+|[!"#$%&'*+,./:;<=>?@^`~…() {}[|]⟨⟩ ‒–—
«»“”‘’-]―
Even more advanced regex:
[+-]?[0-9](?:[0-9,.]*[0-9])?
|[w@](?:[w'’`@-][w']|[w'][w@'’`-])*[w']?
|["#$%&*+,/:;<=>@^`~…() {}[|] «»“”‘’']⟨⟩ ‒–—―
|[.!?]+
|-+](https://image.slidesharecdn.com/nlp-crash2-160412135512/75/Crash-Course-in-Natural-Language-Processing-2016-16-2048.jpg)
![Post-processing
* concatenate abbreviations and decimals
* split contractions with regexes
2-character:
i['‘’`]m|(?:s?he|it)['‘’`]s|(?:i|you|s?he|we|they)
['‘’`]d$
3-character:
(?:i|you|s?he|we|they)['‘’`](?:ll|[vr]e)|n['‘’`]t$](https://image.slidesharecdn.com/nlp-crash2-160412135512/75/Crash-Course-in-Natural-Language-Processing-2016-17-2048.jpg)













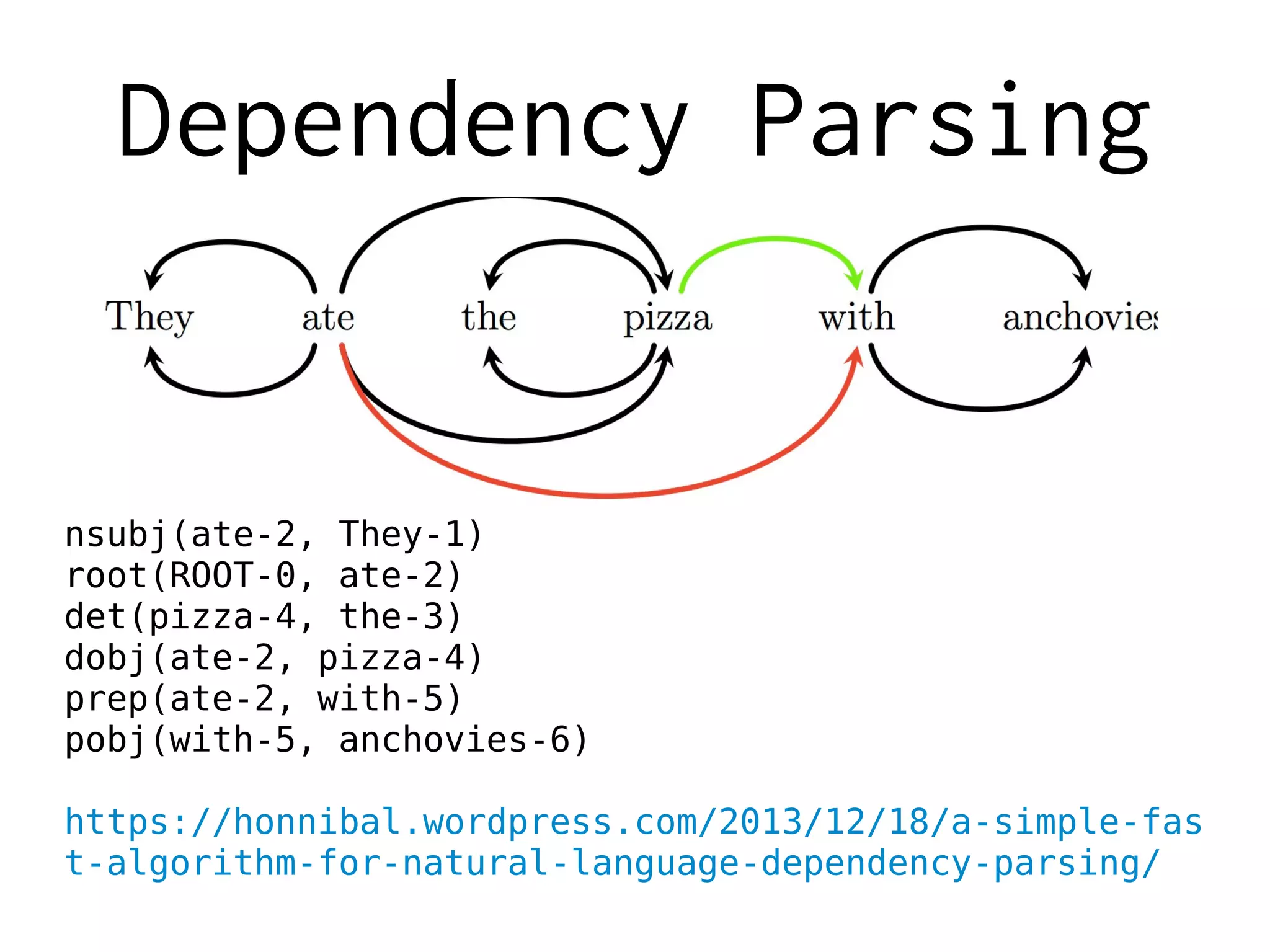
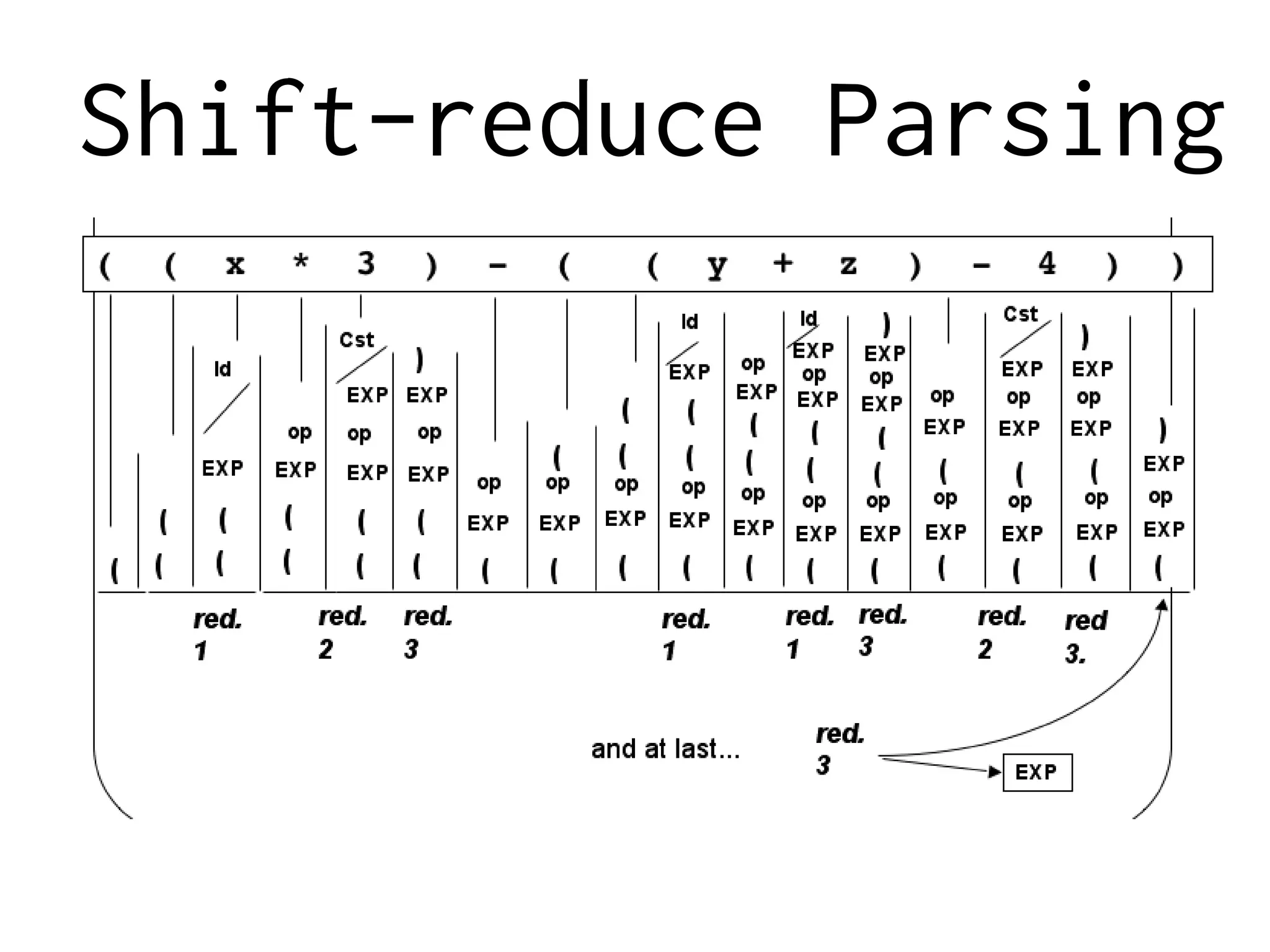
![ML-based Parsing
The parser starts with an empty stack, and a buffer index at 0, with no
dependencies recorded. It chooses one of the valid actions, and applies it to
the state. It continues choosing actions and applying them until the stack is
empty and the buffer index is at the end of the input.
SHIFT = 0; RIGHT = 1; LEFT = 2
MOVES = [SHIFT, RIGHT, LEFT]
def parse(words, tags):
n = len(words)
deps = init_deps(n)
idx = 1
stack = [0]
while stack or idx < n:
features = extract_features(words, tags, idx, n, stack, deps)
scores = score(features)
valid_moves = get_valid_moves(i, n, len(stack))
next_move = max(valid_moves, key=lambda move: scores[move])
idx = transition(next_move, idx, stack, parse)
return tags, parse](https://image.slidesharecdn.com/nlp-crash2-160412135512/75/Crash-Course-in-Natural-Language-Processing-2016-35-2048.jpg)
![Averaged Perceptron
def train(model, number_iter, examples):
for i in range(number_iter):
for features, true_tag in examples:
guess = model.predict(features)
if guess != true_tag:
for f in features:
model.weights[f][true_tag] += 1
model.weights[f][guess] -= 1
random.shuffle(examples)](https://image.slidesharecdn.com/nlp-crash2-160412135512/75/Crash-Course-in-Natural-Language-Processing-2016-36-2048.jpg)












This document provides an overview of natural language processing (NLP) including: 1. An introduction to NLP and its intersection with computational linguistics, computer science, and statistics. 2. A discussion of common NLP problems like tokenization, tagging, parsing, and their rule-based and statistical approaches. 3. An explanation of machine learning techniques for NLP like language models, naive Bayes classifiers, and dependency parsing. 4. Steps for developing an NLP system including translating requirements, experimentation, and going to production.





































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)










