Download to read offline



![Existing approaches
Two main word-level approaches:
Local context (e.g. Word2Vec, [Mikolov2013])
Co-occurence matrix decomposition (e.g. GloVe, [Pennington2014])
Drawbacks:
A model need to recognize the word exactly.
Out of vocabulary words.
V. Malykh (MIPT) Robust Word Vectors for Russian Language AINL 2016 4 / 27](https://image.slidesharecdn.com/qykuopcntcgbwcsmpvu8-signature-d44f3dc49ced19d32cf58a94b539231fc918cb1ad2eec178432f13789e2c54f8-poli-161116133321/85/AINL-2016-Malykh-4-320.jpg)
![Existing approaches (2)
Char-level approach:
Read the letters and try to predict the word, which it represents. E.g.
[Pennington2015]
Drawback:
Again out of vocabulary words.
V. Malykh (MIPT) Robust Word Vectors for Russian Language AINL 2016 5 / 27](https://image.slidesharecdn.com/qykuopcntcgbwcsmpvu8-signature-d44f3dc49ced19d32cf58a94b539231fc918cb1ad2eec178432f13789e2c54f8-poli-161116133321/85/AINL-2016-Malykh-5-320.jpg)









![Corpus Description
News headings corpus in Russian
3 classes: strong paraphrase, weak paraphrase, and non-paraphrase
Firstly introduced in 2015 in [Pronoza2015], in 2016 extended
version.
V. Malykh (MIPT) Robust Word Vectors for Russian Language AINL 2016 16 / 27](https://image.slidesharecdn.com/qykuopcntcgbwcsmpvu8-signature-d44f3dc49ced19d32cf58a94b539231fc918cb1ad2eec178432f13789e2c54f8-poli-161116133321/85/AINL-2016-Malykh-21-320.jpg)







![Corpus Description
Plagiarism detection in scientific papers.
150 pairs of articles’ titles & descriptions in Russian.
3 human experts should produce their evaluation in [0, 1].
V. Malykh (MIPT) Robust Word Vectors for Russian Language AINL 2016 21 / 27](https://image.slidesharecdn.com/qykuopcntcgbwcsmpvu8-signature-d44f3dc49ced19d32cf58a94b539231fc918cb1ad2eec178432f13789e2c54f8-poli-161116133321/85/AINL-2016-Malykh-30-320.jpg)
![Corpus Description
Plagiarism detection in scientific papers.
150 pairs of articles’ titles & descriptions in Russian.
3 human experts should produce their evaluation in [0, 1].
Was introduced in 2014 in work [Derbenev2014].
V. Malykh (MIPT) Robust Word Vectors for Russian Language AINL 2016 21 / 27](https://image.slidesharecdn.com/qykuopcntcgbwcsmpvu8-signature-d44f3dc49ced19d32cf58a94b539231fc918cb1ad2eec178432f13789e2c54f8-poli-161116133321/85/AINL-2016-Malykh-31-320.jpg)







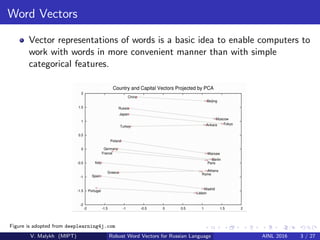
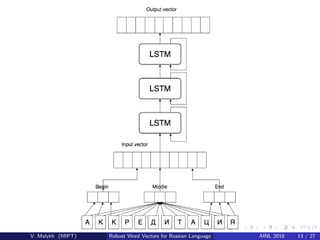
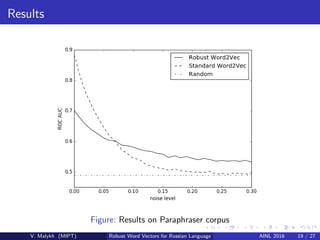
V. Malykh presents an approach for creating robust word vectors for the Russian language that does not rely on a predefined vocabulary or word co-occurrence matrices. The approach uses a LSTM neural network and BME representations of words at the character level to learn word embeddings. Experiments on Russian corpora for paraphrase identification and plagiarism detection show the approach outperforms standard word2vec models, especially in noisy conditions with character substitutions and additions/deletions.

































































































