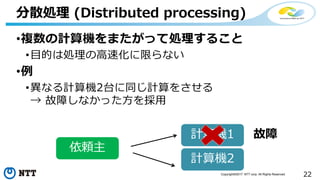
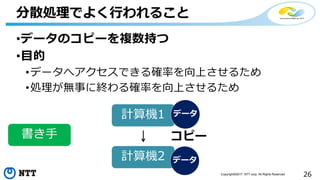
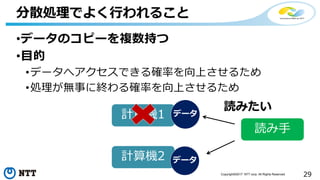
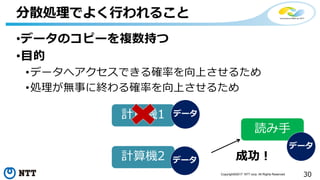
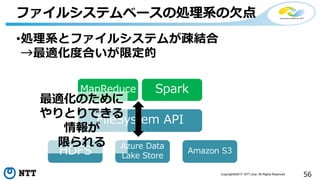
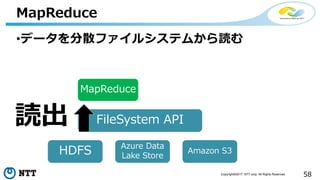
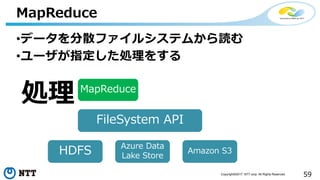
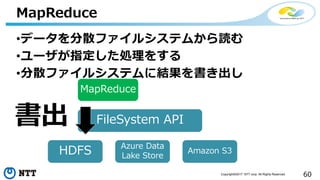
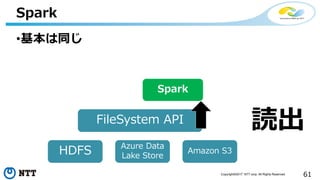
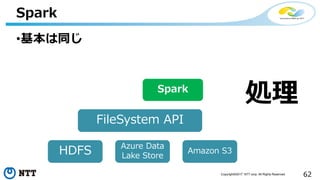
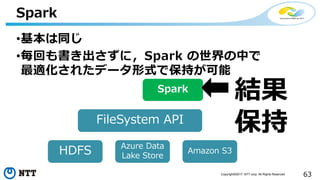
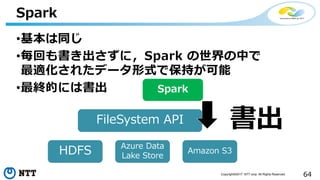
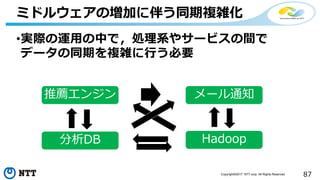
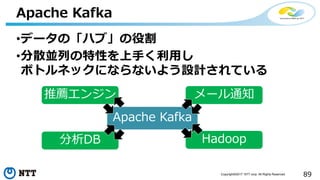
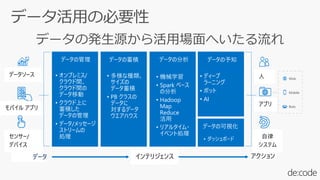
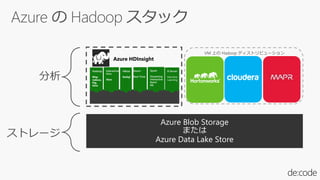
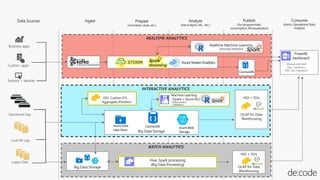
本セッションでは、並列分散処理の基本をおさえつつ、データベースと MapReduce 処理系のアーキテクチャと特性の違い、そしてどのような場面で利用すべきかについて、解説を行います.また、オープンソース分散処理系の最新動向についても解説します。Hadoop や Spark のマネージド サービス「Azure HDInsight」のアップデートもお伝えします。
受講対象: 並列処理・分散処理の基本について知りたい方、並列処理・分散処理の使いどころについて知りたい方、最近のオープンソース分散処理の動向について知りたい方
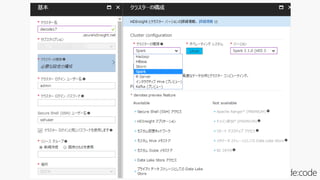
関連リソース 1: Azure HDInsight (https://azure.microsoft.com/ja-jp/services/hdinsight/)
関連リソース 2: 小沢 健史 (http://www.sic.ecl.ntt.co.jp/member/tsuyoshi-ozawa/)
関連リソース 3: [AI04] Scaling Machine Learning to Big Data Using SparkML and SparkR (https://www.microsoft.com/ja-jp/events/decode/2017/sessions.aspx#AI04)
製品/テクノロジ: DevOps/開発言語/OSS
小沢 健史
日本電信電話株式会社
ソフトウェアイノベーションセンタ
研究員
佐藤 直生 (NEO)
日本マイクロソフト株式会社
デベロッパー エバンジェリズム統括本部
エバンジェリスト



















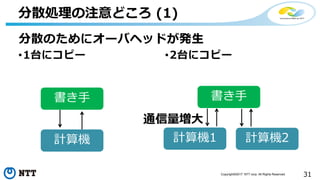
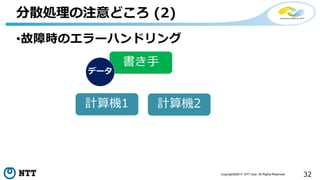
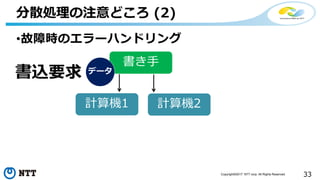
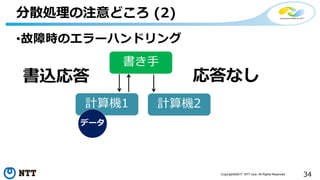
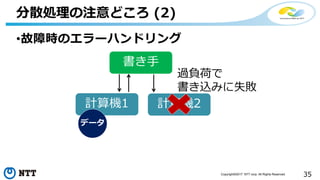
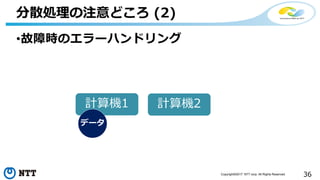
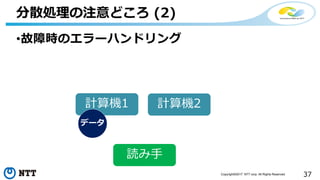
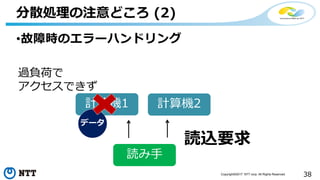











































![[de:code 2017] 並列分散処理の考え方とオープンソース分散処理系の動向](https://cdn.slidesharecdn.com/ss_thumbnails/20170524decode17di06hdinsight-170702125017-thumbnail.jpg?width=640&height=640&fit=bounds)







![[CWT2017]Infrastructure as Codeを活用したF.O.Xのクラウドビッグデータ環境の変化](https://cdn.slidesharecdn.com/ss_thumbnails/dlcwt2017infrastructureascodef-171108044056-thumbnail.jpg?width=640&height=640&fit=bounds)











![[C31]世界最速カラムナーDBは本物だ! by Daisuke Hirama](https://cdn.slidesharecdn.com/ss_thumbnails/c31hirama-131121192150-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)




![[db tech showcase Tokyo 2016] B31: Spark Summit 2016@SFに参加してきたので最新事例などを紹介しつつデ...](https://cdn.slidesharecdn.com/ss_thumbnails/1oula7aqkczs8b8nxbbw-signature-52b95cf478429666da1eac73ad45213570cae72b7e57434c17b4c128f24099d3-poli-160722095519-thumbnail.jpg?width=640&height=640&fit=bounds)






















![[AI08] 深層学習フレームワーク Chainer × Microsoft で広がる応用](https://cdn.slidesharecdn.com/ss_thumbnails/ai08-170705031536-thumbnail.jpg?width=640&height=640&fit=bounds)
![[AI10] ゲームキャラクターのための人工知能と社会への応用 ~ FINAL FANTASY XV を事例として ~](https://cdn.slidesharecdn.com/ss_thumbnails/ai10-170628010423-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DO07] マイクロサービスに必要な技術要素はすべて Spring Cloud にある](https://cdn.slidesharecdn.com/ss_thumbnails/do07-170620022806-thumbnail.jpg?width=640&height=640&fit=bounds)
![[SC09] パッチ待ちはもう古い!Windows 10 最新セキュリティ技術とゼロデイ攻撃攻防の実例](https://cdn.slidesharecdn.com/ss_thumbnails/sc09-170616054924-thumbnail.jpg?width=640&height=640&fit=bounds)
![[SC10] 自社開発モバイルアプリの DLP 対応化を Microsoft Intune で可能に](https://cdn.slidesharecdn.com/ss_thumbnails/sc10-170616054043-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DI12] あらゆるデータをビジネスに活用! Azure Data Lake を中心としたビックデータ処理基盤のアーキテクチャと実装](https://cdn.slidesharecdn.com/ss_thumbnails/di12-170616053736-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DI10] IoT を実践する最新のプラクティス ~ Azure IoT Hub 、SDK 、Azure IoT Suite ~](https://cdn.slidesharecdn.com/ss_thumbnails/di10-170616053735-thumbnail.jpg?width=640&height=640&fit=bounds)
![[AI03] AI × 導入の速さを武器に。 ” 人工知能パーツ ” Cognitive Services の使いどころ](https://cdn.slidesharecdn.com/ss_thumbnails/ai03-170616034922-thumbnail.jpg?width=640&height=640&fit=bounds)
![[SP04] これからのエンジニアに必要な「マネジメント」の考え方](https://cdn.slidesharecdn.com/ss_thumbnails/sp04-170616025029-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DO17] セゾン情報システムズの CTO 小野氏による、伝統的 Sier におけるモダン開発への挑戦](https://cdn.slidesharecdn.com/ss_thumbnails/do17-170616023531-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DO13] 楽天のクラウドストレージ使いこなし術 Azure と OSS で少しずつ進めるレガシー脱却](https://cdn.slidesharecdn.com/ss_thumbnails/do13-170616023513-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DO11] JOY, Inc. : あなたの仕事場での喜びは何ですか?](https://cdn.slidesharecdn.com/ss_thumbnails/do11-170616023509-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DO08] 『変わらない開発現場』を変えていくために ~エンプラ系レガシー SIer のための DevOps 再入門~](https://cdn.slidesharecdn.com/ss_thumbnails/do08-170616023458-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DO06] Infrastructure as Code でサービスを迅速にローンチし、継続的にインフラを変更しよう](https://cdn.slidesharecdn.com/ss_thumbnails/do06-170616023433-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DO05] システムの信頼性を上げるための新しい考え方 SRE ( Site Reliability Engineering ) in Azure, o...](https://cdn.slidesharecdn.com/ss_thumbnails/do05-170616023431-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DO04] アジャイル開発サバイバルガイド 〜キミが必ず直面する課題と乗り越え方を伝えよう!〜](https://cdn.slidesharecdn.com/ss_thumbnails/do04-170616023428-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DO02] Jenkins PipelineとBlue Oceanによる、フルスクラッチからの継続的デリバリ](https://cdn.slidesharecdn.com/ss_thumbnails/do02-170616023407-thumbnail.jpg?width=640&height=640&fit=bounds)
![[SP03] 「怠惰の美徳~言語デザイナーの視点から」](https://cdn.slidesharecdn.com/ss_thumbnails/sp03-170616022212-thumbnail.jpg?width=640&height=640&fit=bounds)
![[SP02] Developing autonomous vehicles with AirSim](https://cdn.slidesharecdn.com/ss_thumbnails/sp02-170616022210-thumbnail.jpg?width=640&height=640&fit=bounds)
![[SP01] CTO が語る! 今注目すべきテクノロジー](https://cdn.slidesharecdn.com/ss_thumbnails/sp01-170616022208-thumbnail.jpg?width=640&height=640&fit=bounds)