Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Shunsuke Aihara
6,734 views
MapReduce解説
とりあえず不正確な場所は多々有りますがなんでMapReduceがこんなにフォーカスされたのかの説明になっていればと思います
Read more
18
Save
Share
Embed
Embed presentation
1
/ 45
2
/ 45
3
/ 45
4
/ 45
5
/ 45
6
/ 45
7
/ 45
8
/ 45
9
/ 45
10
/ 45
11
/ 45
12
/ 45
13
/ 45
14
/ 45
15
/ 45
16
/ 45
17
/ 45
18
/ 45
19
/ 45
20
/ 45
21
/ 45
22
/ 45
23
/ 45
24
/ 45
25
/ 45
26
/ 45
27
/ 45
28
/ 45
29
/ 45
30
/ 45
31
/ 45
32
/ 45
33
/ 45
34
/ 45
35
/ 45
36
/ 45
37
/ 45
38
/ 45
39
/ 45
40
/ 45
41
/ 45
42
/ 45
43
/ 45
44
/ 45
45
/ 45
More Related Content
PDF
Hadoop / MapReduce とは
by
Takeshi Matsuoka
PDF
MapReduce入門
by
Satoshi Noto
PDF
ただいまHadoop勉強中
by
Satoshi Noto
PPT
Apache Hive 紹介
by
あしたのオープンソース研究所
PPTX
今さら聞けないHadoop セントラルソフト株式会社(20120119)
by
Toru Takizawa
PDF
Hadoopのシステム設計・運用のポイント
by
Cloudera Japan
ODP
Hadoop for programmer
by
Sho Shimauchi
PDF
Hadoop入門
by
Preferred Networks
Hadoop / MapReduce とは
by
Takeshi Matsuoka
MapReduce入門
by
Satoshi Noto
ただいまHadoop勉強中
by
Satoshi Noto
Apache Hive 紹介
by
あしたのオープンソース研究所
今さら聞けないHadoop セントラルソフト株式会社(20120119)
by
Toru Takizawa
Hadoopのシステム設計・運用のポイント
by
Cloudera Japan
Hadoop for programmer
by
Sho Shimauchi
Hadoop入門
by
Preferred Networks
What's hot
PDF
40分でわかるHadoop徹底入門 (Cloudera World Tokyo 2014 講演資料)
by
hamaken
PDF
MapReduceプログラミング入門
by
Satoshi Noto
PDF
Hadoopによる大規模分散データ処理
by
Yoji Kiyota
PPTX
Hadoop Troubleshooting 101 - Japanese Version
by
Cloudera, Inc.
PDF
Hadoopことはじめ
by
均 津田
PDF
オライリーセミナー Hive入門 #oreilly0724
by
Cloudera Japan
PDF
MapR M7 技術概要
by
MapR Technologies Japan
PDF
MapReduce/Spark/Tezのフェアな性能比較に向けて (Cloudera World Tokyo 2014 LT講演)
by
Hadoop / Spark Conference Japan
PPT
Amazon Redshift ベンチマーク Hadoop + Hiveと比較
by
FlyData Inc.
PDF
Hadoopデータプラットフォーム #cwt2013
by
Cloudera Japan
PPTX
Hadoopソースコードリーディング8/MapRを使ってみた
by
Recruit Technologies
PDF
HadoopとRDBMSをシームレスに連携させるSmart SQL Processing (Hadoop Conference Japan 2014)
by
Hadoop / Spark Conference Japan
PDF
Apache Drill を利用した実データの分析
by
MapR Technologies Japan
PPT
Hadoop loves H2
by
Tadashi Satoh
PPTX
SASとHadoopとの連携
by
SAS Institute Japan
PDF
MapR アーキテクチャ概要 - MapR CTO Meetup 2013/11/12
by
MapR Technologies Japan
PDF
Amazon Elastic MapReduce@Hadoop Conference Japan 2011 Fall
by
Shinpei Ohtani
PDF
Apache Drill: Rethinking SQL for Big data – Don’t Compromise on Flexibility o...
by
MapR Technologies Japan
PDF
HBase と Drill - 緩い型付けの SQL がいかに NoSQL に適しているか
by
MapR Technologies Japan
PDF
Hadoop概要説明
by
Satoshi Noto
40分でわかるHadoop徹底入門 (Cloudera World Tokyo 2014 講演資料)
by
hamaken
MapReduceプログラミング入門
by
Satoshi Noto
Hadoopによる大規模分散データ処理
by
Yoji Kiyota
Hadoop Troubleshooting 101 - Japanese Version
by
Cloudera, Inc.
Hadoopことはじめ
by
均 津田
オライリーセミナー Hive入門 #oreilly0724
by
Cloudera Japan
MapR M7 技術概要
by
MapR Technologies Japan
MapReduce/Spark/Tezのフェアな性能比較に向けて (Cloudera World Tokyo 2014 LT講演)
by
Hadoop / Spark Conference Japan
Amazon Redshift ベンチマーク Hadoop + Hiveと比較
by
FlyData Inc.
Hadoopデータプラットフォーム #cwt2013
by
Cloudera Japan
Hadoopソースコードリーディング8/MapRを使ってみた
by
Recruit Technologies
HadoopとRDBMSをシームレスに連携させるSmart SQL Processing (Hadoop Conference Japan 2014)
by
Hadoop / Spark Conference Japan
Apache Drill を利用した実データの分析
by
MapR Technologies Japan
Hadoop loves H2
by
Tadashi Satoh
SASとHadoopとの連携
by
SAS Institute Japan
MapR アーキテクチャ概要 - MapR CTO Meetup 2013/11/12
by
MapR Technologies Japan
Amazon Elastic MapReduce@Hadoop Conference Japan 2011 Fall
by
Shinpei Ohtani
Apache Drill: Rethinking SQL for Big data – Don’t Compromise on Flexibility o...
by
MapR Technologies Japan
HBase と Drill - 緩い型付けの SQL がいかに NoSQL に適しているか
by
MapR Technologies Japan
Hadoop概要説明
by
Satoshi Noto
Similar to MapReduce解説
PDF
Data-Intensive Text Processing with MapReduce(Ch1,Ch2)
by
Sho Shimauchi
PPT
Googleの基盤クローン Hadoopについて
by
Kazuki Ohta
PDF
OSC2011 Tokyo/Spring Hadoop入門
by
Shinichi YAMASHITA
PDF
マイニング探検会#10
by
Yoji Kiyota
PDF
OSC2012 OSC.DB Hadoop
by
Shinichi YAMASHITA
PDF
【17-E-3】Hadoop:黄色い象使いへの道 ~「Hadoop徹底入門」より~
by
Developers Summit
PDF
Large Scale Data Mining of the Mobage Service - #PRMU 2011 #Mahout #Hadoop
by
Koichi Hamada
PDF
CloudSpiral 2014年度 ビッグデータ講義
by
Shin Matsumoto
PDF
MapReduce基礎
by
Joongjin Bae
PDF
Hadoop事始め
by
You&I
PDF
『モバゲーの大規模データマイニング基盤におけるHadoop活用』-Hadoop Conference Japan 2011- #hcj2011
by
Koichi Hamada
PDF
R言語による アソシエーション分析-組合せ・事象の規則を解明する-(第5回R勉強会@東京)
by
Koichi Hamada
PPTX
今さら聞けないHadoop勉強会第2回 セントラルソフト株式会社(20120228)
by
YoheiOkuyama
PDF
Rubyによるお手軽分散処理
by
maebashi
PDF
ソーシャルデザインパターン -評判と情報収集-
by
Koichi Hamada
PDF
MapReduce/YARNの仕組みを知る
by
日本ヒューレット・パッカード株式会社
PDF
夏サミ2013 Hadoopを使わない独自の分散処理環境の構築とその運用
by
Developers Summit
PDF
日々進化するHadoopの 「いま」
by
NTT DATA OSS Professional Services
PDF
MapReduceによる大規模データを利用した機械学習
by
Preferred Networks
PDF
OSC2012 Tokyo/Spring - Hadoop入門
by
Shinichi YAMASHITA
Data-Intensive Text Processing with MapReduce(Ch1,Ch2)
by
Sho Shimauchi
Googleの基盤クローン Hadoopについて
by
Kazuki Ohta
OSC2011 Tokyo/Spring Hadoop入門
by
Shinichi YAMASHITA
マイニング探検会#10
by
Yoji Kiyota
OSC2012 OSC.DB Hadoop
by
Shinichi YAMASHITA
【17-E-3】Hadoop:黄色い象使いへの道 ~「Hadoop徹底入門」より~
by
Developers Summit
Large Scale Data Mining of the Mobage Service - #PRMU 2011 #Mahout #Hadoop
by
Koichi Hamada
CloudSpiral 2014年度 ビッグデータ講義
by
Shin Matsumoto
MapReduce基礎
by
Joongjin Bae
Hadoop事始め
by
You&I
『モバゲーの大規模データマイニング基盤におけるHadoop活用』-Hadoop Conference Japan 2011- #hcj2011
by
Koichi Hamada
R言語による アソシエーション分析-組合せ・事象の規則を解明する-(第5回R勉強会@東京)
by
Koichi Hamada
今さら聞けないHadoop勉強会第2回 セントラルソフト株式会社(20120228)
by
YoheiOkuyama
Rubyによるお手軽分散処理
by
maebashi
ソーシャルデザインパターン -評判と情報収集-
by
Koichi Hamada
MapReduce/YARNの仕組みを知る
by
日本ヒューレット・パッカード株式会社
夏サミ2013 Hadoopを使わない独自の分散処理環境の構築とその運用
by
Developers Summit
日々進化するHadoopの 「いま」
by
NTT DATA OSS Professional Services
MapReduceによる大規模データを利用した機械学習
by
Preferred Networks
OSC2012 Tokyo/Spring - Hadoop入門
by
Shinichi YAMASHITA
MapReduce解説
1.
Introduction to MapReduce
and all that jazz in Gumi Shunsuke AIHARA
2.
Overview • What is
MapReduce? • Product point of view • Computational Model point of view • Framework point of view • Example tasks • Simple experiments in Gumi using amazon elastic mapreduce • Future work
3.
Goal of this
presentation • MapReduceのどこがイケてたのか他と少 し違う視点から説明 • MapReduce型分散処理は使うだけなら 簡単だと言うことを理解していただく • 基本の考えはとても単純 • 難しい部分は隠 されている
4.
What is MapReduce?
5.
MapReduce as a
Product • googleの並列分散処理環境 • 分散ファイルシステムGFS • 並列処理システムMapReduce • Hadoop(+HDFS)はそのクローン • ここからは, MapReduceとHadoopはほぼ 同じものとして扱う
6.
MapReduce as a Computational
Model • MapReduceは並列計算のパラダイムが元 • 並列化しやすい処理パターンを利用 • 並列化しやすい処理? • list処理のmap関数とreduce関数 • 副作用の無い関数型プログラミング 並列プログラミングのデザインパターン (スケルトン並列プログラミング)
7.
map • 関数を受け取ってそれをリストの各要
素に(独立に)適用する高階関数 map f [x1 , x2 , ..., xn ] = [f (x1 ), f (x2 ), ..., f (xn )] • (例)リストの要素をそれぞれ二倍する • map(lambda x: x*2 , [1,2,3,4,5]) 関数 f(x) リスト
8.
reduce • リストと,その要素を結合する二項演算
子を受け取って一つの結果を返す関数 reduce [x1 , x2 , ..., xn ] = x1 x2 , ..., xn • (例)リストの要素の値を足し合わせる • reduce(lambda x,y: x+y),[2,4,6,8,10]) 二項演算 リスト 分散処理の世界では処理によってここが二項演算とは限らない
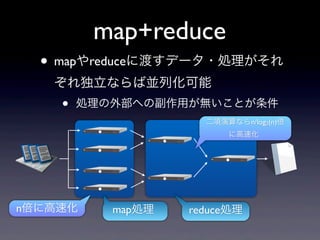
9.
map+reduce •
mapやreduceに渡すデータ・処理がそれ ぞれ独立ならば並列化可能 • 処理の外部への副作用が無いことが条件 二項演算ならn/log2(n)倍 に高速化 n倍に高速化 map処理 reduce処理
10.
Simple distributed
map+reduce • 処理したい巨大な(多数の)ファイルに map+reduceしたい • 分散シェルで複数サーバにタスク分散 • MPIは難しい/大規模データに向かない • 分散シェルはシェルコマンドを他の サーバに投げる/負荷分散も自動化
11.
GXP Grid and
Cluster Shell • 東京大学田浦研作成の分散シェル • pythonによる実装 • クラスタサーバに対してssh接続を行 い接続先サーバ上でコマンドを実行 • GXP ep: 分散シェル+タスクスケジューラ • GXP make: 分散Make(gnu Makeの分散オプ ションを利用)
12.
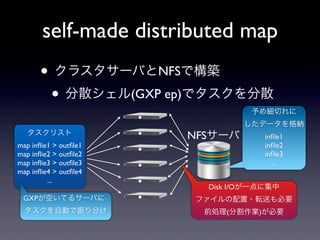
self-made distributed map
• クラスタサーバとNFSで構築 • 分散シェル(GXP ep)でタスクを分散 予め細切れに したデータを格納 タスクリスト NFSサーバ infile1 map inflie1 > outfile1 infile2 map inflie2 > outfile2 infile3 map inflie3 > outfile3 ... map inflie4 > outfile4 ... Disk I/Oが一点に集中 GXPが空いてるサーバに ファイルの配置・転送も必要 タスクを自動で振り分け 前処理(分割作業)が必要
13.
self-made distributed reduce
• map時と構成はほぼ同じ • reduce処理も自分で記述(GXPで分散) タスクに依存があればGXP makeで 中間ファイル タスクリスト(make) を全て保存 tmp1: map1 map2 ... reduce1 map1 map2... .... out1: tmp1 tmp2 ... reduce2 tmp1 tmp2... ... result: out1 out2 ... Disk I/Oが一点に集中 reduce3 out1 out2 ... ファイル転送が必要 複雑なreduce処理を記述 大量の中間ファイル
14.
Bottleneck of distributed
processing for massive data • タスクスケジューラは優秀でも... • ファイルの配置の問題 • ファイルの分割/分散配置を自動化したい • Disk I/Oを分散化 • 計算の局所性の問題 • 配置場所と計算場所は自動的に同じ場所で • ファイル転送を最小限に/タスクを自動生成 並列計算分野(GXP)と大規模データ解析分野(MapReduce)のフォーカスの違い
15.
From map&reduce to
MapReduce • MapReduceはmap+reduceを効率的に並列 分散化するフレームワーク • 効率的な分散処理への工夫と制約 • 面倒な手続きの隠 • ただし、解きたい問題をMapReduceに合 わせて再設計する必要あり
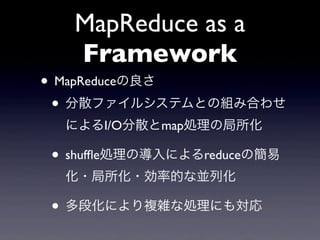
16.
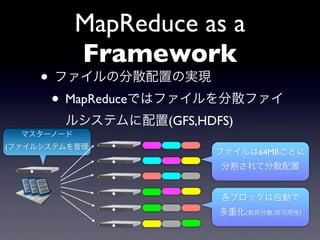
MapReduce as a
Framework • ファイルの分散配置の実現 • MapReduceではファイルを分散ファイ ルシステムに配置(GFS,HDFS) マスターノード (ファイルシステムを管理 ファイルは64MBごとに 分割されて分散配置 各ブロックは自動で 多重化(負荷分散/高可用性)
17.
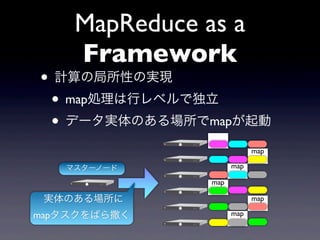
MapReduce as a
Framework • 計算の局所性の実現 • map処理は行レベルで独立 • データ実体のある場所でmapが起動 map map マスターノード map map 実体のある場所に map mapタスクをばら撒く map
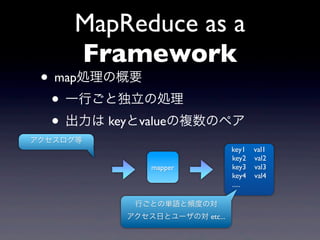
18.
MapReduce as a
Framework • map処理の概要 • 一行ごと独立の処理 • 出力は keyとvalueの複数のペア アクセスログ等 key1 val1 key2 val2 mapper key3 val3 key4 val4 ..... 行ごとの単語と頻度の対 アクセス日とユーザの対 etc...
19.
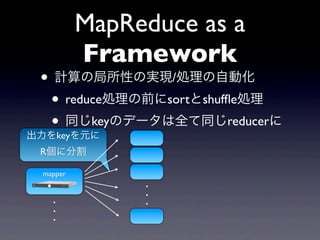
MapReduce as a
Framework • 計算の局所性の実現/処理の自動化 • reduce処理の前にsortとshuffle処理 • 同じkeyのデータは全て同じreducerに mapper . . .
20.
MapReduce as a
Framework • 計算の局所性の実現/処理の自動化 • reduce処理の前にsortとshuffle処理 • 同じkeyのデータは全て同じreducerに 出力をkeyを元に R個に分割 mapper . . . . . .
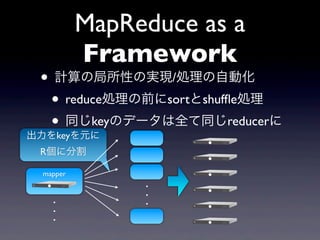
21.
MapReduce as a
Framework • 計算の局所性の実現/処理の自動化 • reduce処理の前にsortとshuffle処理 • 同じkeyのデータは全て同じreducerに 出力をkeyを元に R個に分割 mapper . . . . . .
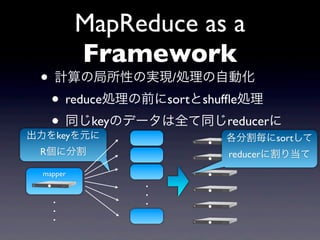
22.
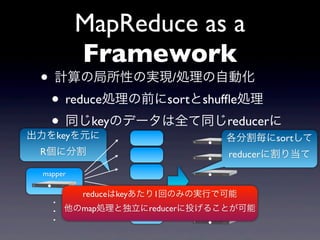
MapReduce as a
Framework • 計算の局所性の実現/処理の自動化 • reduce処理の前にsortとshuffle処理 • 同じkeyのデータは全て同じreducerに 出力をkeyを元に 各分割毎にsortして R個に分割 reducerに割り当て mapper . . . . . .
23.
MapReduce as a
Framework • 計算の局所性の実現/処理の自動化 • reduce処理の前にsortとshuffle処理 • 同じkeyのデータは全て同じreducerに 出力をkeyを元に 各分割毎にsortして R個に分割 reducerに割り当て mapper . reduceはkeyあたり1回のみの実行で可能 . . . . 他のmap処理と独立にreducerに投げることが可能 .
24.
MapReduce as a
Framework • MapReduceはkey-val pairが処理の中心 • 複雑な処理は一回のMapReduceでは難 • MapReduceで複雑な処理 • MapReduceを多段化して対応 • MapReduceは単純だが汎用的
25.
MapReduce as a
Framework • MapReduceの良さ • 分散ファイルシステムとの組み合わせ によるI/O分散とmap処理の局所化 • shuffle処理の導入によるreduceの簡易 化・局所化・効率的な並列化 • 多段化により複雑な処理にも対応
26.
However... • Disk I/Oが少ない
or MapReduceに落とし にくい場合はGXPが便利 • MapReduceを使おうとする前に... • NFSも最近は早い(EMCやNetApp) • 数十G程度ならメモリに乗る • アルゴリズムを見直す • C++やOCamlで書く, sed & awkで処理
27.
Example tasks
28.
simple experiment using
amazon EMR • gumiでもログ解析を分散処理化 • 過去全てのデータに対し新しい処理 • 抽出するデータ • 初回アクセス日からの継続数 • ユーザ間インタラクションレート
29.
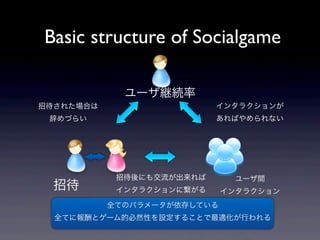
Basic structure of
Socialgame ユーザ継続率 招待された場合は インタラクションが 辞めづらい あればやめられない 招待後にも交流が出来れば ユーザ間 招待 インタラクションに繋がる インタラクション 全てのパラメータが依存している 全てに報酬とゲーム的必然性を設定することで最適化が行われる
30.
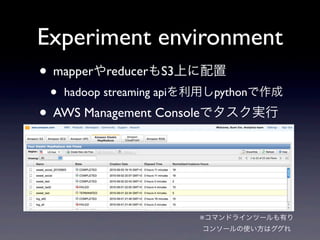
Experiment environment • 全ゲームサーバのapacheログをamazon
S3ストレージに保存 • HadoopのHDFS相当 • ログにはアクセスユーザ識別子を付与 • amazon elastic mapreduceを用いて分散処 理を行う • EC2インスタンス+Hadoopの構成
31.
Experiment environment • 全ゲームサーバのapacheログをamazon
S3ストレージに保存 但しMapReduceが動く場所と • HadoopのHDFS相当 ファイルを保存している場所は別 • ログにはアクセスユーザ識別子を付与 • amazon elastic mapreduceを用いて分散処 理を行う • EC2インスタンス+Hadoopの構成
32.
Experiment environment • mapperやreducerもS3上に配置
• hadoop streaming apiを利用しpythonで作成 • AWS Management Consoleでタスク実行 ※コマンドラインツールも有り コンソールの使い方はググれ
33.
Persistence rate
http://ec2-75-101-191-9.compute-1.amazonaws.com/admin/sweet/ • ユーザが初回アクセスのn日後にもアクセスし ているかどうかをバブルチャートで可視化 • ゲームプレイがルーチン化しているかどうか
34.
Calucurate persistence rate •
map処理の内容 独自apachログパーサー csvモジュール+αを利用してパース 一行ごとに処理 ユーザidをkey,日付のiso表記をvalとしてtab区切りで出
35.
Calucurate persistence rate
• reduce処理の内容 ユーザと日付セットを記憶 一ペアごとに処理 日付をsetの形で記録 ユーザごとにアクセス日を昇順で記録
36.
Calucurate persistence rate
• 後処理 • MapReduceの結果をダウンロードして処理 • amChart(bubble)用のデータに加工 文字列からdateオブジェクトへ 初回アクセス日の取り出し 初アクセス日とオフセットを ペアにしてカウント 集計結果をファイル出力
37.
Result: Persistence rate
http://ec2-75-101-191-9.compute-1.amazonaws.com/admin/sweet/ • 縦軸が初回アクセス日 • 横軸が初回アクセス日からのオフセット • 縦軸横軸共に減衰が少ないことが望ましい
38.
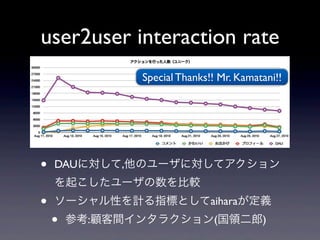
user2user interaction rate
Special Thanks!! Mr. Kamatani!! • DAUに対して,他のユーザに対してアクション を起こしたユーザの数を比較 • ソーシャル性を計る指標としてaiharaが定義 • 参考:顧客間インタラクション(国領二郎)
39.
user2user interaction rate •
コードは少し長いので割愛 • コメント等のURLパターンを分類集計 • DAUは既存の解析済みデータを利用 • mapタスク: • 日付がkey • ユーザーidとアクションのペアがvalue
40.
user2user interaction rate •
reduceタスク: • 日付ごとに処理 • keyをアクション,valueをユーザーidの setとしたdictionaryを作成 • ユーザidのセットを元に, 日-アクショ ン-人数の3つ組を作成
41.
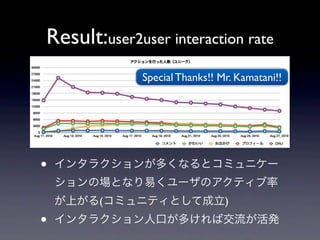
Result:user2user interaction rate
Special Thanks!! Mr. Kamatani!! • インタラクションが多くなるとコミュニケー ションの場となり易くユーザのアクティブ率 が上がる(コミュニティとして成立) • インタラクション人口が多ければ交流が活発
42.
Conclusion • この程度(ログ1ヶ月*6台分)なら •
設計: 5分 • コーディング: 5分 • 実行: 10分(EC2 small instance 10台) • 過去にさかのぼって新しい解析がした い時でも簡単にテストが可能
43.
Future work • MapReduceは小さな処理には向かない
• バッチ処理と上手く組み合わせ • 現在作成中 • インタラクション率はアクションを 行った人だけではなく, 行われた人(コメ ントしてもらった人)も取得 • 鎌谷さんが作成済み!!
44.
Thank you for
your attention!
45.
Thank you for
your attention!
Editor's Notes
#14
make ではマスターのノードでも対応したプロセスが走るので、同時に大量のプロセスを起動すると死ぬ ( 並列数に限界 )
#17
分散配置による負荷分散とデータロストに対する対策 分散ファイルシステム上ではブロックサイズは 64MB だが、ファイルの実体は通常のファイルシステム上に保存されるので、実際の使用容量は通常のファイルシステムのブロックサイズで決まる (HDFS 上ではどんな小さないファイルでも 64MB ととして認識される )
#18
バイトレベルでの分割なので、行の途中で分かれていたりするかもしれない そのあたりの処理がどうなっているかは詳しくは知らない。
#20
reduce 前に shuffle が入ることによって無駄なファイルコピーが存在しなくなる
#27
なので計算の局所性は実はあんまり保たれていない。ファイル転送の無駄が大きい








![map
• 関数を受け取ってそれをリストの各要
素に(独立に)適用する高階関数
map f [x1 , x2 , ..., xn ] = [f (x1 ), f (x2 ), ..., f (xn )]
• (例)リストの要素をそれぞれ二倍する
• map(lambda x: x*2 , [1,2,3,4,5])
関数 f(x) リスト](https://image.slidesharecdn.com/mapreducegumi-100909073448-phpapp02/85/MapReduce-7-320.jpg)
![reduce
• リストと,その要素を結合する二項演算
子を受け取って一つの結果を返す関数
reduce [x1 , x2 , ..., xn ] = x1 x2 , ..., xn
• (例)リストの要素の値を足し合わせる
• reduce(lambda x,y: x+y),[2,4,6,8,10])
二項演算 リスト
分散処理の世界では処理によってここが二項演算とは限らない](https://image.slidesharecdn.com/mapreducegumi-100909073448-phpapp02/85/MapReduce-8-320.jpg)