More Related Content

PPT

PPTX

PPTX
Distributed Systems 第1章 Introduction 
PDF
P2Pネットワークを利用した分散ファイルシステムの開発 
PPT

PPTX
SoR系 分散業務処理システムでのもろもろ考慮点(勢い版 2017.07 
KEY

PPTX
HPCフォーラム2015 B-1RandD 100 Award 受賞記念講演 常温水冷スパコンHP Apollo 8000開発エンジニアによる誕生秘話 N... Similar to Data Center As A Computer 2章前半

PDF

PPTX

PDF

PDF
20121019 engineer startup_meeting 
PDF
Amazon Ec2 S3実践セミナー 2009.07 
PDF

PDF

PDF
20100520 【qpstudy01】 チームでトライ!インフラ構築のススメ 
PPT
楽天インターネットスケーラブルコンピューティング;丸山先生レクチャーシリーズ2010第3回@楽天 
PPT
Performance and Scalability of Web Service 
PDF

PDF

PDF
Open stack reference architecture v1 2 
PDF

PDF
【18-C-3】システムアーキテクチャ構築の実践手法 
PDF
「はじめてのAmazon Web Services」 JAWS-UG 長崎第1回勉強会 
PDF

PDF

PDF

PDF
20121124 学生セミナー「基礎からわかる! IT業界とプログラミング」 More from Akinori YOSHIDA

PDF

PDF

ODP
Datacenter As Acomputer 第8章 
ODP
Datacenter As Acomputer 第6章 
PDF
Data Center As A Computer 5章前半 
PDF
Data Center As A Computer 2章前半
- 1.
- 2.
2章
● Workloads and Software Instracture
– 負荷とソフトウェアインフラストラクチャ
● WSCs環境のアプリケーションはシステム設計
に影響を与える
– 大規模インターネットサービスにおけるソフトウェ
ア
– 構築のためのシステムソフトウェアとツール
- 3.
用語
● WSC環境下での3つのソフトウェアレイヤ
– プラットフォームレベルソフトウェア
● ファームウェア、カーネル、OS、ライブラリなど1台の
サーバのハードウェア群を抽象化するソフトウェア
– クラスターレベルインフラストラクチャ
● クラスタレベルでのリソース管理をしたりサービス提供
するソフトウェアの集合体
● データセンターにおけるOS
– 分散ファイルシステム/スケジューラ/RPC/プログラミングモデ
ル(ex. MapReduce,hadoop,Sawzall,BigTable,Dynamo など)
– アプリケーションレベルソフトウェア
● 実際のサービスに使われるソフトウェア
● オンライン: GoogleMaps,Gmail
● オフライン: 大規模データ解析/処理(インデックス作
成、画像処理)
- 4.
- 5.
並列処理
● データ並列処理
– ウェブページやログなど大量の互いに独立なデータ
セットによる
– 通信や同期のオーバーヘッドをなくすため、計算を
必要とする
● リクエストレベルの並列処理
– 大量のユーザアクセス
– 例
● 検索リクエストは独立 & リードオンリーDBでOK
– 計算はリクエスト内でも、別のリクエストの間でも分けやす
い??
● メールユーザデータを変更するが、処理はユーザ毎に独
立
- 6.
負荷が変化しやすい
● デプロイサイクルが早い
– 週単位 vs 年単位
– システム設計者はベンチマークを取りにくい
● 人気が出てユーザが増えると、すぐ負荷が増大
する
– ハードウェアアーキテクトは一つのコードでよいパ
フォーマンスを出す必要がない (デプロイサイク
ル早いから)
– しかし、新しいハードウェアの特徴を生かすための
ソフトウェア書き直しが求められる
- 7.
プラットフォームが均質
● ソフトウェアのデプロイ対象としては、データ
センターは均一である
● 不均一性
– コスト効率のよいハードが出てきたときに出現
● スケジューリングと負荷分散が単純になる
● プラットフォームレベルソフトウェア
(driver,firmware etc)のメンテナンスの苦し
みが少ない
● サプライチェーンと修理の効率化
● 種類少ない方が修理楽
● デスクトップは何百万ものハード構成がありサ
ポートが大変
- 8.
データセンター vs. デスクトップ
まとめ
● Helpful
– 並列処理
– プラットフォームの均一性
– 単純
● Not Helpful
– スケール
– ハードウェア故障
– 負荷変動のスピード
- 9.
Performance and Availabilitytoolbox
● いくつかのプログラミングコンセプト
– インフラレベル、アプリケーションレベル両方で
– ハイパフォーマンス、高可用性においての適用性が
広いため
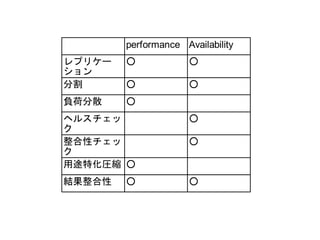
● 一般的な概念
– レプリケーション
– 分割
– 負荷分散
– ヘルスチェックとウォッチドック
– 整合性チェック
– 特定用途圧縮
– 結果整合性
- 10.
- 11.
- 12.
分割
● データを分割して、多数のノードに分配
● オペレーションは各ノードで行われて、結果は
統合される
● 分割ポリシーはいろいろ
– パフォーマンス重視
– 容量重視
● 細かく分割されたデータ断片のリカバリは大き
いデータより早い
- 13.
負荷分散
● 一番遅いレスポンダが支配的
– レスポンスタイムの分散を少なくすることが重要
● 負荷分散は各サーバあたりのWorkを同じにす
る分割ポリシーを加えることによって到達
● レプリが動いてる環境
– ロードバランサがどのサーバにリクエストを投げる
か動的に調整する
– 完全なロードバランスは難しい
- 14.
- 15.
整合性チェック
● 失敗はデータ破損によってもおこる
● 頻度は低いがおきる
– ハードウェアチェックやソフトウェアチェックでは
見つけられない
● データ欠損はさらなるソフトウェアチェックで
減らせる
– 潜在的なエンコードを変更する
– 信頼性の高い整合性チェックをする
- 16.
用途特化圧縮
● 最近のデータセンターでの機器コストの大部分
はストレージレイヤにある
● 高スループットのサービスではデータの大部分
をDRAMに置くことが重要
● それゆえ、圧縮技術が重要になってくる
● CPUで展開するオーバーヘッドは、データが
ディスクに乗ってしまうことに比べれば、相当
小さい
● 一般的な圧縮アルゴリズムは結構いい
● でも用途特化した圧縮は、もっとよい
- 17.
結果整合性
● レプリをいっぱいふやす
– 複雑さが増える
– パフォーマンスに影響
– 分散アプリの可用性を減らす
- 18.
● 大規模並行アプリケーションのレスポンスタイ
ムは高信頼性計算テクニックで改善できる
– 一つの遅いワーカで、大規模並行タスクのレスポン
スタイムが決定する
– そういう遅いワーカを別のワーカで代替する
- 19.
クラスタレベルの基盤ソフトウェア
● OSが、1台のコンピュータの、リソースマネジ
メントと基本サービスを提供するように、多数
のコンピュータ、ネットワーク機器、ストレー
ジのある環境でも、OSに類似した機能を提供
するソフトウェアが必要である。
● これをクラスタレベルの基盤と呼ぶ
● クラスタレベルの基盤をなす、4つの大きなグ
ループを解説する
- 20.
1.リソース管理
● 不可欠
● ユーザタスクをハードウェアに割り当てる
● 優先度と上限をつける
● タスクマネジメント
● 一番単純な形
– ハードウェアをユーザやジョブに割り当てる
- 21.
2.ハードウェア抽象化
● 大規模分散アプリケーションは、いくつかの基
本機能が必要
● 分散ストレージ、メッセージパッシング、同期
● 大規模システムでこれらをパフォーマンスと可
用性を保ちつつ実現するのは複雑で難しい
● 各アプリケーションで実装するのは賢くない
● 共通モジュール/サービスをつくるべし
● GFS、Dynamo、Chubby、など
- 22.
3.デプロイとメンテナンス
● 監視重要
– 小規模デプロイでのマニュアル実行は大規模システ
ムでは適切なインフラが必要
– ソフトウェアイメージ配布と構成管理、パフォーマ
ンスと品質の監視、緊急事態のトリアージ
● 例: Autopiot system from Microsoft
– ハードウェア監視、自動診断、自動修理
● 例: GoogleのSystem Health Infrastructure
– パフォーマンスデバッグと最適化
● 例: X-Trace by UCBerkley 監視インフラ
- 23.
4.プログラミングフレームワーク
● これまで述べたのはハードウェアのデプロイと
効率的な利用
● プログラマにとっての複雑さは隠蔽できてない
● プラグラマの視点から
– メモリ/ストレージの階層が複雑
– 故障しがち
– メモリ、ネットワークバンド幅が少ない
– 不均質
● 一部はプログラミングフレームワークをつくる
ことで解決
– MapReduce,BigTable,Dynamo
– データ分割、配布、耐障害性を自動的に処理
- 24.
Fault free 運用
● 何千台もサーバがあると数時間に一回は故障す
る
● MTBFが1年はPCレベルではリーズナブルで
も、データセンターレベルのサービスではこれ
は嘘
● 故障は日常的
● クラスターレベルシステムソフトウェアはアプ
リケーションソフトウェアからそういったのを
隠さないといけない
– 全部のアプリに対してそれを実現するのは難しい