参考文献
60
• [1] KhurramSoomro and Amir Roshan Zamir. Action Recognition in Realistic Sports Videos, 2015
https://cs.stanford.edu/~amirz/index_files/Springer2015_action_chapter.pdf
• [2] Christian Ledig, et al. Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network, 2016
https://arxiv.org/abs/1609.04802
• [3] Tero Karras (Tero Karras FI). Progressive Growing of GANs for Improved Quality, Stability, and Variation. 2017.
https://arxiv.org/pdf/1710.10196.pdf
• [4] Kunihiko Fukushima, Neocognitron: A Self-organizing Neural Network Model for a Mechanism of Pattern
Recognition Unaffected by Shift in Position, 1980
http://www.cs.princeton.edu/courses/archive/spr08/cos598B/Readings/Fukushima1980.pdf
• [5] Zhe Cao, et al. Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields, 2016
https://arxiv.org/pdf/1611.08050.pdf
• [6] Ching-Hang Chen et al. 3D Human Pose Estimation = 2D Pose Estimation + Matching. In CVPR, 2017.
http://openaccess.thecvf.com/content_cvpr_2017/papers/Chen_3D_Human_Pose_CVPR_2017_paper.pdf
• [7] Julieta Martinez et al. A simple yet effective baseline for 3d human pose estimation. In ICCV, 2017.
http://openaccess.thecvf.com/content_ICCV_2017/papers/Martinez_A_Simple_yet_ICCV_2017_paper.pdf
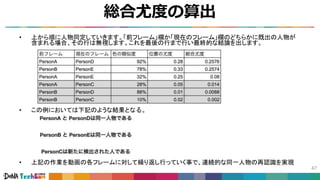
#25 姿勢推定技術が話題になりはじめたのは、今からやく1年前で、
CVPR2017という国際的なカンファレンス、カーネギメロン大学が発表して、Realtime Multi Person Pose Estimationという論文が元になっています。
こちらの論文では、画像や映像に複数の人物が映っている状況においても、その各々のポーズ情報を、リアルタイムで、かつ高精度に検出する事ができる
というのを提唱しています。
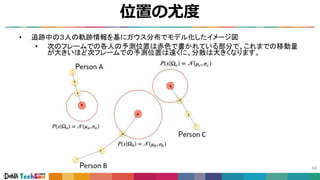
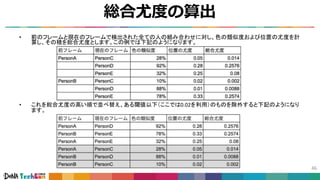
#38 また、正確な検出器を前提として考えた場合には、ある時刻tで検出された人と、次のフレーム時刻t+1で検出された人で対応付けを行う事で、同一人物判定ができます。
例えば、その場合、簡易に対応付けを実現する方法として、Intersection over Union (IoU) の結果を利用するというものが考えられます。
これは、各フレームで検出された人の矩形同士、各々の組みでIoUを求め、その値が大きいもの同士を同一の人物とします。
上の写真の例の場合は、aとcでIOUを求め、aとdでIOUを求め、大きい方が同一の人物であるとします。













![超解像
11
• 解像度の低い画像から解像度の高い画像への復元
• ハイビジョンテレビ等の解像度補完用途に使われる
引用2 [Christian Ledig, et al., 2016]](https://image.slidesharecdn.com/techcon2018-180214015907/85/slide-12-320.jpg)

![画像生成
13
• GAN (Generative Adversarial Networks)
• 画像群の表現空間を学習して、全く新しい画像を生成する
引用3 [Tero Karras FI, 2017]](https://image.slidesharecdn.com/techcon2018-180214015907/85/slide-14-320.jpg)

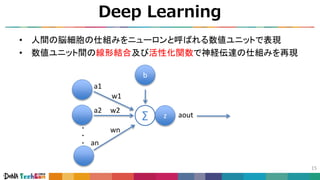
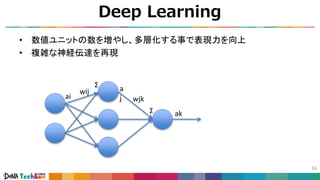
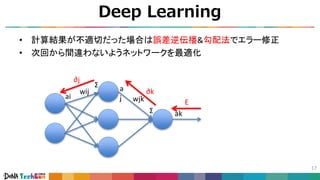
![Convolutional Neural Networks
18
• Neural Networkの仕組みをコンピュータビジョンに応用したもの
• 画像の各ピクセルをそのままネットワークに入力
引用4 [Kunihiko Fukushima, et al., 1980]](https://image.slidesharecdn.com/techcon2018-180214015907/85/slide-19-320.jpg)
![Convolutional Neural Networks
19
• 画像の局所的な周波数を抽出する畳込み層 (単純型細胞)
• 画像の位置ずれを吸収するプーリング層 (複雑型細胞)
引用4 [Kunihiko Fukushima, et al., 1980]](https://image.slidesharecdn.com/techcon2018-180214015907/85/slide-20-320.jpg)
![Convolutional Neural Networks
20
• 画像の特徴抽出を学習
• Neocognitron = 脳の視覚野に関する知見を元に考案
引用4 [Kunihiko Fukushima, et al., 1980]](https://image.slidesharecdn.com/techcon2018-180214015907/85/slide-21-320.jpg)
![VGGNet
21
• 代表的な画像分類用CNNモデル
• 2014年にILSVRCで2位入賞
• 3 × 3 の畳込み層とpooling層のみで構成されたシンプルなモデル
• 今でも多くのCVタスクの特徴抽出器として使用される
引用5 [Zhe Cao, et al., 2016]](https://image.slidesharecdn.com/techcon2018-180214015907/85/slide-22-320.jpg)

![Realtime Multi-Person Pose Estimation
23
• CVPR2017でCMUが発表した論文
• arXiv:1611.08050[cs.CV]
• 画像に映った複数人物をリアルタイムかつ高精度に姿勢推定する技術](https://image.slidesharecdn.com/techcon2018-180214015907/85/slide-24-320.jpg)
![Realtime Multi-Person Pose Estimation
24
• OpenPose (CMUが公開しているCaffe実装のライブラリ)
• https://github.com/CMU-Perceptual-Computing-Lab/openpose
引用5 [Zhe Cao, et al., 2016]](https://image.slidesharecdn.com/techcon2018-180214015907/85/slide-25-320.jpg)
![Realtime Multi-Person Pose Estimation
25
• 畳込み層とプーリング層のみで構成
• VGG19を特徴抽出器として利用
• Multi-branch構造のモデル
引用5 [Zhe Cao, et al., 2016]](https://image.slidesharecdn.com/techcon2018-180214015907/85/slide-26-320.jpg)


![Realtime Multi-Person Pose Estimation
28
• Multi-Stage構造
• StageごとにFeature mapsとConfidence mapsとPAFsを結合
• ステージが進むごとに精度が上がる
引用5 [Zhe Cao, et al., 2016]](https://image.slidesharecdn.com/techcon2018-180214015907/85/slide-29-320.jpg)
















![3D姿勢推定1
51
• 3D Human Pose Estimation = 2D Pose Estimation + Matching
• 入力画像を与える
• 2D姿勢推定
• 3Dライブラリから検索
• 検索結果を歪ませる
• 3Dポーズ推定
引用6 [Ching-Hang Chen et al., In CVPR, 2017]](https://image.slidesharecdn.com/techcon2018-180214015907/85/slide-52-320.jpg)
![3D姿勢推定1
52
• 3D姿勢Xが2D姿勢xを与えた画像Iと条件的に独立していると仮定し、ノンパラメトリック
最近傍法でP(X|x)をモデル化
• 検索結果のXiをそのまま使わず、より一致させるために標本Xiを歪ませる。
• 3D標本座標Xiから奥行きの深度座標を、2Dの姿勢情報から(x、y)座標を使用
歪ませた例
引用6 [Ching-Hang Chen et al., In CVPR, 2017]](https://image.slidesharecdn.com/techcon2018-180214015907/85/slide-53-320.jpg)
![3D姿勢推定2
53
• A simple yet effective baseline for 3d human pose estimation
• 単眼・単一のRGB画像から人の3D姿勢推定
• 2D姿勢情報を入力とし3D姿勢情報を出力とするニューラルネットを使ったRegression
タスク
• Residual コネクションやBatch normalizationやドロップアウトを駆使して、軽量ながらも
効率よく学習できるネットワークを追求
• ネットワーク構成
• 入力は16個の2次元の点、出力は16個の3次元の点、ロス関数は平均2乗誤差
• パラメータの数は400万 – 500万の間
図
引用7 [Julieta Martinez et al., In ICCV, 2017.]](https://image.slidesharecdn.com/techcon2018-180214015907/85/slide-54-320.jpg)




![参考文献
60
• [1] Khurram Soomro and Amir Roshan Zamir. Action Recognition in Realistic Sports Videos, 2015
https://cs.stanford.edu/~amirz/index_files/Springer2015_action_chapter.pdf
• [2] Christian Ledig, et al. Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network, 2016
https://arxiv.org/abs/1609.04802
• [3] Tero Karras (Tero Karras FI). Progressive Growing of GANs for Improved Quality, Stability, and Variation. 2017.
https://arxiv.org/pdf/1710.10196.pdf
• [4] Kunihiko Fukushima, Neocognitron: A Self-organizing Neural Network Model for a Mechanism of Pattern
Recognition Unaffected by Shift in Position, 1980
http://www.cs.princeton.edu/courses/archive/spr08/cos598B/Readings/Fukushima1980.pdf
• [5] Zhe Cao, et al. Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields, 2016
https://arxiv.org/pdf/1611.08050.pdf
• [6] Ching-Hang Chen et al. 3D Human Pose Estimation = 2D Pose Estimation + Matching. In CVPR, 2017.
http://openaccess.thecvf.com/content_cvpr_2017/papers/Chen_3D_Human_Pose_CVPR_2017_paper.pdf
• [7] Julieta Martinez et al. A simple yet effective baseline for 3d human pose estimation. In ICCV, 2017.
http://openaccess.thecvf.com/content_ICCV_2017/papers/Martinez_A_Simple_yet_ICCV_2017_paper.pdf](https://image.slidesharecdn.com/techcon2018-180214015907/85/slide-61-320.jpg)


![SSII2022 [SS1] ニューラル3D表現の最新動向〜 ニューラルネットでなんでも表せる?? 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss1ssii2022hkatoneural3drepresentationhiroharukato-220607054619-fadc6480-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]GQNと関連研究,世界モデルとの関係について](https://cdn.slidesharecdn.com/ss_thumbnails/20180817-180827085537-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Deep High-Resolution Representation Learning for Human Pose Estimation](https://cdn.slidesharecdn.com/ss_thumbnails/20190517hrnet-190517005504-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]画像を使ったSim2Realの現況](https://cdn.slidesharecdn.com/ss_thumbnails/imagesim2real-201030025320-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会] Spectral Norm Regularization for Improving the Generalizability of De...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhackspectralnorm1-170907072536-thumbnail.jpg?width=640&height=640&fit=bounds)





![SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss2ssii2022-220607054716-2760bd30-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis](https://cdn.slidesharecdn.com/ss_thumbnails/nerfdlseminar1-200327021512-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Neural Radiance Flow for 4D View Synthesis and Video Processing (NeRF...](https://cdn.slidesharecdn.com/ss_thumbnails/20210806journalclub-210806023711-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://cdn.slidesharecdn.com/ss_thumbnails/swintransformer-210514020542-thumbnail.jpg?width=640&height=640&fit=bounds)







































![タクシーxAIを支えるKubernetesとAIデータパイプラインの信頼性の取り組みについて [SRE NEXT 2020]](https://cdn.slidesharecdn.com/ss_thumbnails/202001srenext-200125032719-thumbnail.jpg?width=640&height=640&fit=bounds)

![後部座席タブレットにおけるMaaS時代を見据えた半歩先のUX設計」 [MOBILITY:dev]](https://cdn.slidesharecdn.com/ss_thumbnails/20191031mobilitydevyoneyama-191031085554-thumbnail.jpg?width=640&height=640&fit=bounds)
![ドライブレコーダ映像からの3次元空間認識 [MOBILITY:dev]](https://cdn.slidesharecdn.com/ss_thumbnails/20191031mobilitydevmiyazawa-191031085336-thumbnail.jpg?width=640&height=640&fit=bounds)
![MOVで実践したサーバーAPI実装の超最適化について [MOBILITY:dev]](https://cdn.slidesharecdn.com/ss_thumbnails/20191031mobilitydevera-191031084650-thumbnail.jpg?width=640&height=640&fit=bounds)

![課題ドリブン、フルスタックAI開発術 [MOBILITY:dev]](https://cdn.slidesharecdn.com/ss_thumbnails/20191031mobilitydevkuzuoka-191031073741-thumbnail.jpg?width=640&height=640&fit=bounds)
