コメント、質問をお待ちしております
• Twitter /YouTube Live からの投稿お待ちしております!
• #自由と統制のバランス
のハッシュタグで質問ツイートをいただけると
本日回答できなかった場合にも
DeNA Analytics Blog - Medium などで後日回答差し上げます。
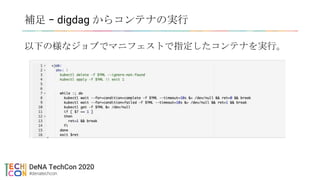
7.
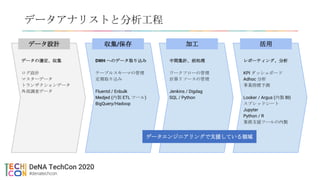
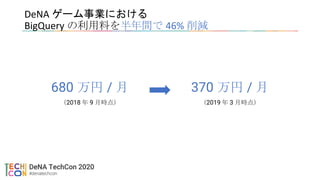
• BigQuery の利用におけるコスト削減の取り組み
•Google Cloud Next '19 in Tokyo で発表済み(2019/08/01)
• BigQuery を使い倒せ!DeNA データエンジニアの取り組み事例
• https://cloud.withgoogle.com/next/19/tokyo/sessions?session=D2-2-S09
• オンプレ(Hadoop/Vertica)から クラウド(BigQuery) への移行の詳細
• Google Cloud Data Platform Day #2 で発表予定(2020/03/31)
• Google Cloud を使ったデータプラットフォームへの変革と最新の活用状況について
• https://cloudonair.withgoogle.com/events/jp-data-platform-day
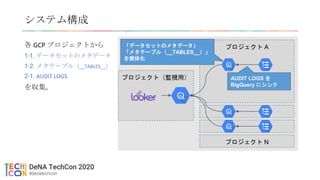
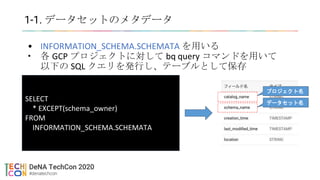
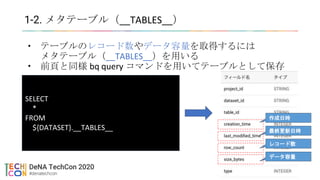
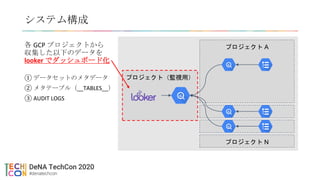
• DeNA が Looker を採用した経緯
• Looker Game Night で発表予定(時期未定)
• https://discover.looker.com/Q1Y2020JPNGameEvent.html
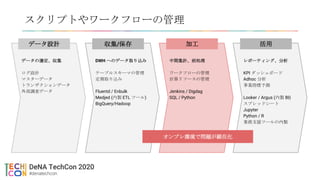
本日お話しないこと
Service B
Service A
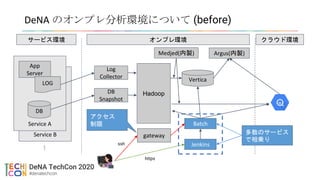
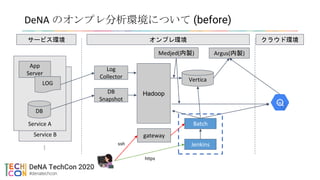
DeNAのオンプレ分析環境について (before)
App
Server
LOG
DB
...
Log
Collector
DB
Snapshot
Hadoop
Medjed(内製)
Vertica
Argus(内製)
Batch
Jenkins
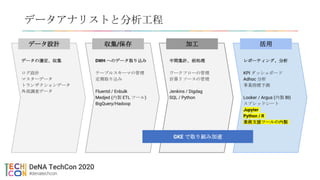
サービス環境 オンプレ環境 クラウド環境
gateway
ssh
https
アクセス
制限
多数のサービス
で相乗り
Service B
Service A
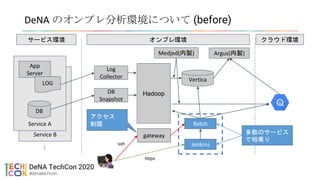
DeNAのオンプレ分析環境について (before)
App
Server
LOG
DB
...
Log
Collector
DB
Snapshot
Hadoop
Medjed(内製)
Vertica
Argus(内製)
Batch
Jenkins
サービス環境 オンプレ環境 クラウド環境
gateway
ssh
https
アクセス
制限
多数のサービス
で相乗り
Service B
Service A
DeNAのオンプレ分析環境について (before)
App
Server
LOG
DB
...
Log
Collector
DB
Snapshot
Hadoop
Medjed(内製)
Vertica
Argus(内製)
Batch
Jenkins
サービス環境 オンプレ環境 クラウド環境
gateway
ssh
https
62.
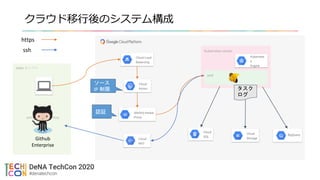
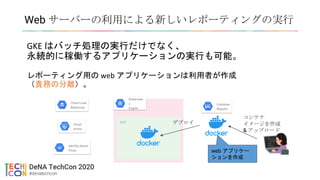
DeNA オンプレ
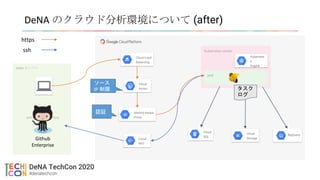
DeNA のクラウド分析環境について(after)
Cloud Load
Balancing
Identity-Aware
Proxy
Cloud
Armor
Kubernetes cluster
Kubernete
s
Engine
pod
Cloud
SQL
Cloud
NAT
Cloud
StorageGithub
Enterprise
タスク
ログ
ssh
https
BigQuery
ソース
IP 制限
認証












































































![SSII2022 [TS3] コンテンツ制作を支援する機械学習技術〜 イラストレーションやデザインの基礎から最新鋭の技術まで 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts32022ssiiess-220607054523-e80be8dc-thumbnail.jpg?width=640&height=640&fit=bounds)








![[DL輪読会]Dense Captioning分野のまとめ](https://cdn.slidesharecdn.com/ss_thumbnails/dlseminar-201202012355-thumbnail.jpg?width=640&height=640&fit=bounds)



![[Cloud OnAir] BigQuery の仕組みからベストプラクティスまでのご紹介 2018年9月6日 放送](https://cdn.slidesharecdn.com/ss_thumbnails/dddddd-180906091548-thumbnail.jpg?width=640&height=640&fit=bounds)

























![[DI06] 並列分散処理の考え方とオープンソース分散処理系の動向](https://cdn.slidesharecdn.com/ss_thumbnails/di06-170605024555-thumbnail.jpg?width=640&height=640&fit=bounds)
![[de:code 2017] 並列分散処理の考え方とオープンソース分散処理系の動向](https://cdn.slidesharecdn.com/ss_thumbnails/20170524decode17di06hdinsight-170702125017-thumbnail.jpg?width=640&height=640&fit=bounds)















![タクシーxAIを支えるKubernetesとAIデータパイプラインの信頼性の取り組みについて [SRE NEXT 2020]](https://cdn.slidesharecdn.com/ss_thumbnails/202001srenext-200125032719-thumbnail.jpg?width=640&height=640&fit=bounds)

![後部座席タブレットにおけるMaaS時代を見据えた半歩先のUX設計」 [MOBILITY:dev]](https://cdn.slidesharecdn.com/ss_thumbnails/20191031mobilitydevyoneyama-191031085554-thumbnail.jpg?width=640&height=640&fit=bounds)
![ドライブレコーダ映像からの3次元空間認識 [MOBILITY:dev]](https://cdn.slidesharecdn.com/ss_thumbnails/20191031mobilitydevmiyazawa-191031085336-thumbnail.jpg?width=640&height=640&fit=bounds)
![MOVで実践したサーバーAPI実装の超最適化について [MOBILITY:dev]](https://cdn.slidesharecdn.com/ss_thumbnails/20191031mobilitydevera-191031084650-thumbnail.jpg?width=640&height=640&fit=bounds)

![課題ドリブン、フルスタックAI開発術 [MOBILITY:dev]](https://cdn.slidesharecdn.com/ss_thumbnails/20191031mobilitydevkuzuoka-191031073741-thumbnail.jpg?width=640&height=640&fit=bounds)

![DeNAのQCTマネジメント IaaS利用のベストプラクティス [AWS Summit Tokyo 2019]](https://cdn.slidesharecdn.com/ss_thumbnails/aws-summit-tokyo-2019-kei-190617011042-thumbnail.jpg?width=640&height=640&fit=bounds)






