Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
TellSun
PDF, PPTX
427 views
Deeplearning bank marketing dataset
Deeplearning bank marketing dataset
Technology
◦
Read more
0
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 26
2
/ 26
3
/ 26
4
/ 26
5
/ 26
6
/ 26
7
/ 26
8
/ 26
9
/ 26
10
/ 26
11
/ 26
12
/ 26
13
/ 26
14
/ 26
15
/ 26
16
/ 26
17
/ 26
18
/ 26
19
/ 26
20
/ 26
21
/ 26
22
/ 26
23
/ 26
24
/ 26
25
/ 26
26
/ 26
More Related Content
PDF
【論文調査】XAI技術の効能を ユーザ実験で評価する研究
by
Satoshi Hara
PDF
論文紹介:InternVideo: General Video Foundation Models via Generative and Discrimi...
by
Toru Tamaki
PDF
不均衡データのクラス分類
by
Shintaro Fukushima
PPTX
画像処理AIを用いた異常検知
by
Hideo Terada
PDF
最近のDeep Learning (NLP) 界隈におけるAttention事情
by
Yuta Kikuchi
PDF
トピックモデルの評価指標 Perplexity とは何なのか?
by
hoxo_m
PDF
機械学習で泣かないためのコード設計
by
Takahiro Kubo
PPTX
[DL輪読会]Dense Captioning分野のまとめ
by
Deep Learning JP
【論文調査】XAI技術の効能を ユーザ実験で評価する研究
by
Satoshi Hara
論文紹介:InternVideo: General Video Foundation Models via Generative and Discrimi...
by
Toru Tamaki
不均衡データのクラス分類
by
Shintaro Fukushima
画像処理AIを用いた異常検知
by
Hideo Terada
最近のDeep Learning (NLP) 界隈におけるAttention事情
by
Yuta Kikuchi
トピックモデルの評価指標 Perplexity とは何なのか?
by
hoxo_m
機械学習で泣かないためのコード設計
by
Takahiro Kubo
[DL輪読会]Dense Captioning分野のまとめ
by
Deep Learning JP
What's hot
PDF
失敗から学ぶ機械学習応用
by
Hiroyuki Masuda
PDF
機械学習モデルの判断根拠の説明
by
Satoshi Hara
PDF
LSTM (Long short-term memory) 概要
by
Kenji Urai
PDF
Prophet入門【Python編】Facebookの時系列予測ツール
by
hoxo_m
PDF
Bayesian Neural Networks : Survey
by
tmtm otm
PDF
【基調講演】『深層学習の原理の理解に向けた理論の試み』 今泉 允聡(東大)
by
MLSE
PDF
“機械学習の説明”の信頼性
by
Satoshi Hara
PDF
一般化線形モデル (GLM) & 一般化加法モデル(GAM)
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
Disentanglement Survey:Can You Explain How Much Are Generative models Disenta...
by
Hideki Tsunashima
PPTX
【DL輪読会】The Forward-Forward Algorithm: Some Preliminary
by
Deep Learning JP
PPTX
Efficient Neural Architecture Search via Parameters Sharing @ ICML2018読み会
by
tomohiro kato
PDF
機械学習のためのベイズ最適化入門
by
hoxo_m
PPTX
【DL輪読会】LAR-SR: A Local Autoregressive Model for Image Super-Resolution
by
Deep Learning JP
PPTX
[DL輪読会]Revisiting Deep Learning Models for Tabular Data (NeurIPS 2021) 表形式デー...
by
Deep Learning JP
PPTX
【DL輪読会】Scaling Laws for Neural Language Models
by
Deep Learning JP
PPTX
[DL輪読会]Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets
by
Deep Learning JP
PDF
ベルヌーイ分布からベータ分布までを関係づける
by
itoyan110
PPTX
SSII2020SS: グラフデータでも深層学習 〜 Graph Neural Networks 入門 〜
by
SSII
PPTX
Dimensionality reduction with t-SNE(Rtsne) and UMAP(uwot) using R packages.
by
Satoshi Kato
PPTX
深層学習の非常に簡単な説明
by
Seiichi Uchida
失敗から学ぶ機械学習応用
by
Hiroyuki Masuda
機械学習モデルの判断根拠の説明
by
Satoshi Hara
LSTM (Long short-term memory) 概要
by
Kenji Urai
Prophet入門【Python編】Facebookの時系列予測ツール
by
hoxo_m
Bayesian Neural Networks : Survey
by
tmtm otm
【基調講演】『深層学習の原理の理解に向けた理論の試み』 今泉 允聡(東大)
by
MLSE
“機械学習の説明”の信頼性
by
Satoshi Hara
一般化線形モデル (GLM) & 一般化加法モデル(GAM)
by
Deep Learning Lab(ディープラーニング・ラボ)
Disentanglement Survey:Can You Explain How Much Are Generative models Disenta...
by
Hideki Tsunashima
【DL輪読会】The Forward-Forward Algorithm: Some Preliminary
by
Deep Learning JP
Efficient Neural Architecture Search via Parameters Sharing @ ICML2018読み会
by
tomohiro kato
機械学習のためのベイズ最適化入門
by
hoxo_m
【DL輪読会】LAR-SR: A Local Autoregressive Model for Image Super-Resolution
by
Deep Learning JP
[DL輪読会]Revisiting Deep Learning Models for Tabular Data (NeurIPS 2021) 表形式デー...
by
Deep Learning JP
【DL輪読会】Scaling Laws for Neural Language Models
by
Deep Learning JP
[DL輪読会]Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets
by
Deep Learning JP
ベルヌーイ分布からベータ分布までを関係づける
by
itoyan110
SSII2020SS: グラフデータでも深層学習 〜 Graph Neural Networks 入門 〜
by
SSII
Dimensionality reduction with t-SNE(Rtsne) and UMAP(uwot) using R packages.
by
Satoshi Kato
深層学習の非常に簡単な説明
by
Seiichi Uchida
Similar to Deeplearning bank marketing dataset
PPTX
エンタープライズと機械学習技術
by
maruyama097
PPTX
データサイエンティストに聞く!今更聞けない機械学習の基礎から応用まで Vm 1
by
Shunsuke Nakamura
PPTX
Deep learningの世界に飛び込む前の命綱
by
Junya Kamura
PDF
ディープラーニング最近の発展とビジネス応用への課題
by
Kenta Oono
PDF
2018/8/6 トレLABO2 AI案件のよくある落とし穴と人材育成
by
Trainocate Japan, Ltd.
PPTX
機械学習の基礎
by
Ken Kumagai
PDF
全部見せます、データサイエンティストの仕事
by
Shunsuke Nakamura
PDF
kintone Café 大阪 Vol.13 〜karuraで学ぶ、機械学習の活かし方〜
by
Takahiro Kubo
PPTX
データサイエンティストに聞く!今更聞けない機械学習の基礎から応用まで V e-1
by
Shunsuke Nakamura
PPTX
20180920_【ヒカ☆ラボ】【データサイエンティストが教える 】 機械学習、人工知能を使った「ビジネスになる」アプリケーションの作り方
by
Shunsuke Nakamura
PPTX
20180925_【サポーターズCoLab勉強会】【営業から運用まで】データサイエンティストという職業
by
Shunsuke Nakamura
PPTX
1028 TECH & BRIDGE MEETING
by
健司 亀本
PDF
データサイエンティストに聞く!今更聞けない機械学習の基礎から応用まで V k-1
by
Shunsuke Nakamura
PDF
20180807_全部見せます、データサイエンティストの仕事
by
Shunsuke Nakamura
PPTX
Oracle advanced analyticsによる機械学習full version
by
幹雄 小川
PDF
ICT新技術の商業教育への導入 ― ディープラーニングとブロックチェーンの教材化の考究 ―
by
seastar orion
PPTX
データサイエンティストに聞く!今更聞けない機械学習の基礎から応用まで V8
by
Shunsuke Nakamura
PPTX
データサイエンティストに聞く!今更聞けない機械学習の基礎から応用まで
by
Shunsuke Nakamura
PDF
【初学者向け】AI・機械学習・深層学習の概観と深層学習による暗号通貨価格予測トライアル
by
Masaharu Kinoshita
PDF
ディープラーニング入門
by
t dev
エンタープライズと機械学習技術
by
maruyama097
データサイエンティストに聞く!今更聞けない機械学習の基礎から応用まで Vm 1
by
Shunsuke Nakamura
Deep learningの世界に飛び込む前の命綱
by
Junya Kamura
ディープラーニング最近の発展とビジネス応用への課題
by
Kenta Oono
2018/8/6 トレLABO2 AI案件のよくある落とし穴と人材育成
by
Trainocate Japan, Ltd.
機械学習の基礎
by
Ken Kumagai
全部見せます、データサイエンティストの仕事
by
Shunsuke Nakamura
kintone Café 大阪 Vol.13 〜karuraで学ぶ、機械学習の活かし方〜
by
Takahiro Kubo
データサイエンティストに聞く!今更聞けない機械学習の基礎から応用まで V e-1
by
Shunsuke Nakamura
20180920_【ヒカ☆ラボ】【データサイエンティストが教える 】 機械学習、人工知能を使った「ビジネスになる」アプリケーションの作り方
by
Shunsuke Nakamura
20180925_【サポーターズCoLab勉強会】【営業から運用まで】データサイエンティストという職業
by
Shunsuke Nakamura
1028 TECH & BRIDGE MEETING
by
健司 亀本
データサイエンティストに聞く!今更聞けない機械学習の基礎から応用まで V k-1
by
Shunsuke Nakamura
20180807_全部見せます、データサイエンティストの仕事
by
Shunsuke Nakamura
Oracle advanced analyticsによる機械学習full version
by
幹雄 小川
ICT新技術の商業教育への導入 ― ディープラーニングとブロックチェーンの教材化の考究 ―
by
seastar orion
データサイエンティストに聞く!今更聞けない機械学習の基礎から応用まで V8
by
Shunsuke Nakamura
データサイエンティストに聞く!今更聞けない機械学習の基礎から応用まで
by
Shunsuke Nakamura
【初学者向け】AI・機械学習・深層学習の概観と深層学習による暗号通貨価格予測トライアル
by
Masaharu Kinoshita
ディープラーニング入門
by
t dev
Recently uploaded
PDF
TomokaEdakawa_職種と講義の関係推定に基づく履修支援システムの基礎検討_HCI2026
by
Matsushita Laboratory
PDF
20260119_VIoTLT_vol22_kitazaki_v1___.pdf
by
Ayachika Kitazaki
PDF
自転車ユーザ参加型路面画像センシングによる点字ブロック検出における性能向上方法の模索 (20260123 SeMI研)
by
Yuto Matsuda
PDF
maisugimoto_曖昧さを含む仕様書の改善を目的としたアノテーション支援ツールの検討_HCI2025.pdf
by
Matsushita Laboratory
PDF
ST2024_PM1_2_Case_study_of_local_newspaper_company.pdf
by
akipii ogaoga
PDF
Team Topology Adaptive Organizational Design for Rapid Delivery of Valuable S...
by
akipii ogaoga
TomokaEdakawa_職種と講義の関係推定に基づく履修支援システムの基礎検討_HCI2026
by
Matsushita Laboratory
20260119_VIoTLT_vol22_kitazaki_v1___.pdf
by
Ayachika Kitazaki
自転車ユーザ参加型路面画像センシングによる点字ブロック検出における性能向上方法の模索 (20260123 SeMI研)
by
Yuto Matsuda
maisugimoto_曖昧さを含む仕様書の改善を目的としたアノテーション支援ツールの検討_HCI2025.pdf
by
Matsushita Laboratory
ST2024_PM1_2_Case_study_of_local_newspaper_company.pdf
by
akipii ogaoga
Team Topology Adaptive Organizational Design for Rapid Delivery of Valuable S...
by
akipii ogaoga
Deeplearning bank marketing dataset
1.
同一データに関する ディープラーニング アプローチ 1
2.
照山 康平 IT系ベンダー会社勤務 ◦ メインフレームのOS開発 ◦
AI関連お手伝い 情報系大学学部卒 AI歴半年くらい ◦ ちゃんとやりだしたのはここ3,4カ月 2
3.
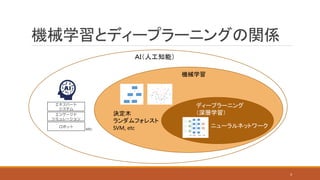
機械学習とディープラーニングの関係 機械学習 AI(人工知能) ディープラーニング (深層学習)決定木 ランダムフォレスト SVM, etc ニューラルネットワーク 3
4.
機械学習とディープラーニングの違い 今回、Bank Marketingデー タセットを使って、ディープ ラーニングでの分析に挑戦 4
5.
使用した環境 OS ◦ CentOS Linux
release 7.6.1810 (Core) GPU ◦ なし CPU ◦ 72 cores / Intel(R) Xeon(R) Gold 5118 CPU @ 2.30GHz RAM ◦ 756GiB プログラミング環境 ◦ Python3.6 + Keras 2.2.4 , backend=TensorFlow 5
6.
扱うデータセット Bank Marketing Dataset ポルトガルの銀行機関のテレマーケティングで、 クライアントが定期預金を契約するか(変数y)を 予測するデータセット 年齢、職業、ローン等の情報がある。 ◦
もともとはUCI機械学習リポジトリに掲載されていたもの 出展:http://lovedata.main.jp/2018/12/28/data-mining-process/ 6
7.
扱うデータセット こんなデータ 出展:https://www.kaggle.com/janiobachmann/bank-marketing-dataset 7
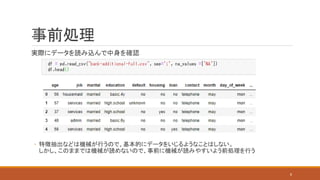
8.
事前処理 実際にデータを読み込んで中身を確認 ◦ 特徴抽出などは機械が行うので、基本的にデータをいじるようなことはしない。 しかし、このままでは機械が読めないので、事前に機械が読みやすいよう前処理を行う 8
9.
事前処理 ラベルエンコーディング(文字→数値変換) ◦ 機械は文字列(カテゴリデータ)を認識できないので、数値データに変換する 9
10.
カテゴリデータを数値化すれば、とりあえず訓練できるのでやってみる ◦ 中間層(全結合層) 3つ、各層のユニット数32のネットワーク モデル作成・訓練 : 入力層
中間層×3 出力層 : : : : 10
11.
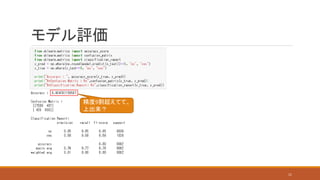
モデル評価 精度9割超えてて、 上出来? 11
12.
モデル評価 精度9割超えてて、 上出来? 予測したいのはこの y=yesの部分 12
13.
実はこのデータセットかなり偏っている! ⇒ このままでは良い訓練ができないので、 事前準備と訓練内容を精査していく モデル評価 精度9割超えてて、 上出来? 予測したいのはこの y=yesの部分 極端に言えば、常に0(No)を返す関数 def func(x): return
0 でも8割近くの精度が出てしまう! 13
14.
事前処理(追加) OneHotエンコーディング(数値→OneHotベクトル変換) ◦ ラベルエンコーディングでカテゴリを数値にしただけでは、そこに大小関係が生まれてしまい、機械で 適切に扱えなくなる ⇒
このため、OneHotベクトル化が必要 Animal 鳥 犬 猫 Animal 0 1 2 LabelEncode bird dog cat 1 0 0 0 1 0 0 0 1 OneHotEncode 鳥<犬<猫という 扱いになってしまう カテゴリ数分のダミー変数を用意して、 対応する列だけを1,他を0にしたベクト ルに変換する 例) 14
15.
事前処理(追加) pandas.get_dummies() ◦ pandas.DataFrameなら、pandas.get_dummies()メソッドでラベルエンコーディングとOneHotエンコーディ ングを一気にやれるのでそっちの方が楽 day_of_week :
[“fri”, “mon”, “thu”, …] を数値化&OneHotエンコードカテゴリ以外のデータはそのまま 15
16.
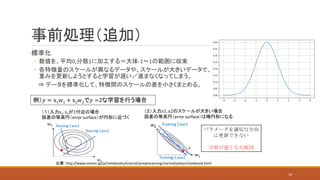
標準化 ◦ 数値を、平均0,分散1に加工する=大体-1~1の範囲に収束 ◦ 各特徴量のスケールが異なるデータや、スケールが大きいデータで、 重みを更新しようとすると学習が遅い/進まなくなってしまう。 ⇒
データを標準化して、特徴間のスケールの差を小さくまとめる。 事前処理(追加) 例)𝑦 = x1 𝑤1 + x2 𝑤2で𝑦 =2な学習を行う場合 (1)入力x1, x2が1付近の場合 誤差の等高円(error surface)が円形に近づく (2)入力x1, x2のスケ-ルが大きい場合 誤差の等高円(error surface)は楕円形になる 出展:http://www.renom.jp/ja/notebooks/tutorial/preprocessing/normalization/notebook.html 16
17.
事前処理(追加) 標準化(続き) ◦ 同様の目的で、正規化(値を0~1に圧縮する)もあるが、今回のデータのように、値のスケールが必 ずしも明確ではない場合は標準化を行う。 ◦ 画像のRGBなどは1~255で明確なので正規化を使う ◦
標準化も、対象データの母集団が正規分布になっていないと逆効果になるので注意(今回のデータは大体大丈夫そう) 表は見やすいようにDataFrame化したものです。 実際にはnumpy.ndarrayで出力されます。 17
18.
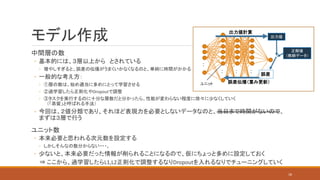
中間層の数 ◦ 基本的には、3層以上から とされている ◦
増やしすぎると、誤差の伝播がうまくいかなくなるのと、単純に時間がかかる ◦ 一般的な考え方: ◦ ①層の数は、始め適当に多めにとって学習させる ◦ ②過学習したら正則化やDropoutで調整 ◦ ③タスクを実行するのに十分な層数だと分かったら、性能が変わらない程度に徐々に少なくしていく (「蒸留」と呼ばれる手法) ◦ 今回は、2値分類であり、それほど表現力を必要としないデータなのと、当日まで時間がないので、 まずは3層で行う ユニット数 ◦ 本来必要と思われる次元数を設定する ◦ しかしそんなの数分からない・・・。 ◦ 少ないと、本来必要だった情報が削られることになるので、仮にちょっと多めに設定しておく ⇒ ここから、過学習したらL1,L2正則化で調整するなりDropoutを入れるなりでチューニングしていく モデル作成 : : : : 出力値計算 誤差伝播(重み更新) 正解値 (教師データ) 出力値 誤差 18 ユニット
19.
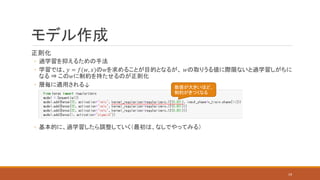
モデル作成 正則化 ◦ 過学習を抑えるための手法 ◦ 学習では、𝑦
= 𝑓(𝑤, 𝑥)の𝑤を求めることが目的となるが、 𝑤の取りうる値に際限ないと過学習しがちに なる ⇒ この𝑤に制約を持たせるのが正則化 ◦ 層毎に適用される↓ ◦ 基本的に、過学習したら調整していく(最初は、なしでやってみる) 数値が大きいほど、 制約がきつくなる 19
20.
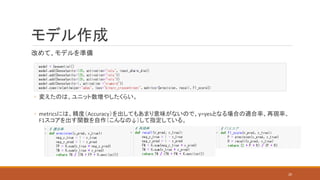
改めて、モデルを準備 ◦ 変えたのは、ユニット数増やしたくらい。 ◦ metricsには、精度(Accuracy)を出してもあまり意味がないので、y=yesとなる場合の適合率、再現率、 F1スコアを出す関数を自作(こんなの↓)して指定している。 モデル作成 20
21.
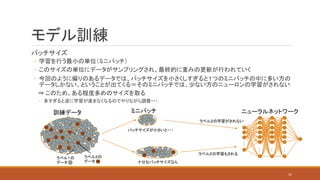
モデル訓練 バッチサイズ ◦ 学習を行う最小の単位(ミニバッチ) ◦ このサイズの単位にデータがサンプリングされ、最終的に重みの更新が行われていく ◦
今回のように偏りのあるデータでは、バッチサイズを小さくしすぎると1つのミニバッチの中に多い方の データしかない、ということが出てくる=そのミニバッチでは、少ない方のニューロンの学習がされない ⇒ このため、ある程度多めのサイズを取る ◦ 多すぎると逆に学習が進まなくなるのでやりながら調整・・・ バッチサイズが小さいと・・・ 十分なバッチサイズなら : : : : ラベル2の学習がされない ラベル2の学習もされる ミニバッチ訓練データ ニューラルネットワーク 21 ラベル2の データ ラベル1の データ
22.
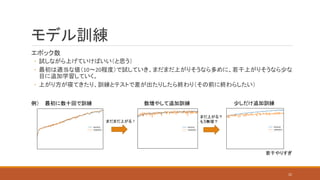
モデル訓練 エポック数 ◦ 試しながら上げていけばいい(と思う) ◦ 最初は適当な値(10~20程度)で試していき、まだまだ上がりそうなら多めに、若干上がりそうなら少な 目に追加学習していく。 ◦
上がり方が寝てきたり、訓練とテストで差が出たりしたら終わり(その前に終わらしたい) 最初に数十回で訓練 数増やして追加訓練 まだまだ上がる! まだ上がる? もう無理? 少しだけ追加訓練 若干やりすぎ 例) 22
23.
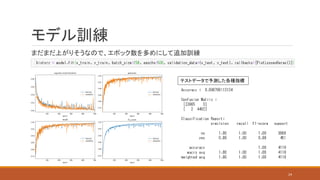
◦ バッチサイズ=256, エポックはとりあえず20回でループ ◦
callbacksのlivelossesplot.PlotLossesKeras()は、訓練しながらmetricsをプロットしてくれる素敵クラス ◦ 結果⇒ モデル訓練 なぜかvalidationのF1スコアが出ない・・・が、 F1score = 2*precision*recall/(precision+recall) で導けるのであまり気にしない 23
24.
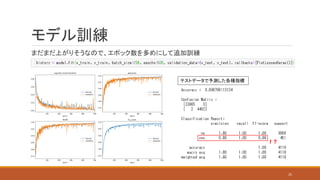
モデル訓練 まだまだ上がりそうなので、エポック数を多めにして追加訓練 テストデータで予測した各種指標 24
25.
モデル訓練 まだまだ上がりそうなので、エポック数を多めにして追加訓練 テストデータで予測した各種指標 !? 25
26.
まとめ データの前処理はかなり重要 × ディープラーニングなら入力データそのままで、機械がいい感じに加工してくれる 〇 データの理解と前準備が大切 ◦
異常値が混じっていないか? ⇒ ETL ◦ 誤ったスケールで学習していないか?⇒ 標準化・正規化 ◦ カテゴリデータが数値のままになっていないか? ⇒ OneHotベクトル化 ◦ そのそもデータは足りているか? ⇒ データ収集 ・・・ 今回のデータセットでは、たまたまこれらがうまく整っていたためか、(異常な)超高精度! ただ、せっかく良いモデルができてもそれを説明できないと使ってもらえない・・・。 ◦ このためにも、データの理解は必要になってくる ディープラーニングにおいても、BIと連携していくことは重要 26
Download











![事前処理(追加)
pandas.get_dummies()
◦ pandas.DataFrameなら、pandas.get_dummies()メソッドでラベルエンコーディングとOneHotエンコーディ
ングを一気にやれるのでそっちの方が楽
day_of_week : [“fri”, “mon”, “thu”, …] を数値化&OneHotエンコードカテゴリ以外のデータはそのまま
15](https://image.slidesharecdn.com/deeplearningbankmarketing-190718012046/85/Deeplearning-bank-marketing-dataset-15-320.jpg)










![[DL輪読会]Dense Captioning分野のまとめ](https://cdn.slidesharecdn.com/ss_thumbnails/dlseminar-201202012355-thumbnail.jpg?width=640&height=640&fit=bounds)













![[DL輪読会]Revisiting Deep Learning Models for Tabular Data (NeurIPS 2021) 表形式デー...](https://cdn.slidesharecdn.com/ss_thumbnails/dl20220318dlfin-220322065433-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets](https://cdn.slidesharecdn.com/ss_thumbnails/20220325okimura-220405024717-thumbnail.jpg?width=640&height=640&fit=bounds)





























